
GPT-4와 같은 대규모 언어 모델이 점차 로봇 공학과 통합되면서 인공 지능이 점차 현실 세계로 이동하고 있습니다. 이에 체화지능(embodied Intelligence)과 관련된 연구도 점점 주목을 받고 있다. 많은 연구 프로젝트 중에서 Google의 "RT" 로봇 시리즈가 항상 선두에 있었으며 최근 이러한 추세가 가속화되기 시작했습니다(자세한 내용은 "대형 모델이 로봇을 재구성하고 있는 방법, Google Deepmind가 미래에 구현된 지능을 정의하는 방법" 참조).

지난해 7월, 구글 딥마인드는 시각-언어-행동(VLA) 상호작용을 위해 로봇을 제어할 수 있는 세계 최초의 모델인 RT-2를 출시했습니다. RT-2는 대화 방식으로 지시하는 것만으로도 수많은 사진에서 Swift를 식별하고 그녀에게 콜라 캔을 전달할 수 있습니다.
이제 이 로봇은 또 진화했습니다. RT 로봇의 최신 버전은 'RT-H'로, 복잡한 작업을 간단한 언어 명령어로 분해한 후 이를 로봇 동작으로 변환해 작업 실행의 정확성과 학습 효율성을 높일 수 있다. 예를 들어, "피스타치오 병 뚜껑을 닫으세요"와 같은 작업과 장면 이미지가 주어지면 RT-H는 VLM(시각 언어 모델)을 사용하여 "팔을 앞으로 움직이세요"와 같은 언어 동작(모션)을 예측합니다. 그리고 "팔을 오른쪽으로 회전"하고, 이러한 언어적 행동을 기반으로 로봇의 행동을 예측합니다.

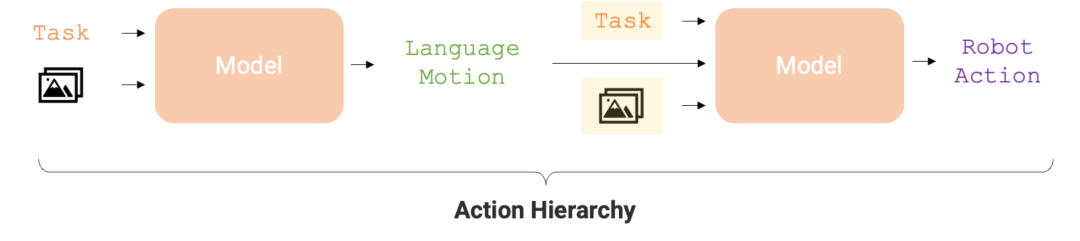
행동 수준은 로봇 작업 실행의 정확성과 학습 효율성을 최적화하는 데 중요합니다. 이러한 계층적 구조를 통해 RT-H는 다양한 로봇 작업에서 RT-2보다 훨씬 더 나은 성능을 발휘하여 로봇에 보다 효율적인 실행 경로를 제공합니다.

다음은 논문의 내용입니다.

언어는 인간 추론의 엔진으로, 이를 통해 복잡한 개념을 더 간단한 구성 요소로 분해할 수 있습니다. 우리의 오해를 풀고 새로운 맥락에서 개념을 일반화합니다. 최근 몇 년 동안 로봇은 효율적이고 결합된 언어 구조를 사용하여 높은 수준의 개념을 분해하고, 언어 교정을 제공하거나, 새로운 환경에서 일반화를 달성하기 시작했습니다.
이러한 연구는 일반적으로 공통 패러다임을 따릅니다. 즉, 언어로 설명된 상위 수준 작업(예: "콜라 캔 집기")에 직면하여 언어로 관찰 및 작업 설명을 하위 수준 로봇에 매핑하는 전략을 학습합니다. 이는 대규모 다중 작업 데이터 세트를 통해 달성되어야 합니다. 이러한 시나리오에서 언어의 장점은 유사한 작업(예: "콜라 캔 집기" 대 "사과 집기") 간의 공유 구조를 인코딩하여 작업에서 동작으로의 매핑을 학습하는 데 필요한 데이터를 줄이는 것입니다. 그러나 작업이 더욱 다양해짐에 따라 각 작업을 설명하는 데 사용되는 언어도 더욱 다양해지며(예: "콜라 캔을 집다" 대 "물 한 잔 채우다") 고급 언어를 통해서만 다양한 작업 간 학습이 가능해집니다. 서로 구조를 공유하는 것이 더 어려워집니다.
다양한 작업을 학습하기 위해 연구자들은 이러한 작업 간의 유사점을 보다 정확하게 포착하는 것을 목표로 합니다.
그들은 언어가 높은 수준의 작업을 설명할 수 있을 뿐만 아니라 작업을 완료하는 방법을 자세히 설명할 수도 있다는 것을 발견했습니다. 이러한 종류의 표현은 더 섬세하고 특정 작업에 더 가깝습니다. 예를 들어, "콜라 캔 집기" 작업은 일련의 보다 자세한 단계, 즉 "언어 동작"으로 나눌 수 있습니다. 먼저 "팔을 앞으로 뻗기", 그 다음 "캔 잡기", 마지막으로 "올리기" 팔을 위쪽으로 " ". 연구자들의 핵심 통찰력은 언어적 행동을 높은 수준의 작업 설명과 낮은 수준의 행동을 연결하는 중간 계층으로 사용함으로써 언어적 행동을 통해 형성된 행동 계층을 구축하는 데 사용될 수 있다는 것입니다.
이러한 수준의 행동을 확립하면 여러 가지 이점이 있습니다.

언어 동작의 위 장점을 고려하여 Google DeepMind의 연구원은 엔드 투 엔드 프레임워크인 RT-H(동작 계층이 있는 로봇 변환기, 즉 동작 수준을 사용하는 로봇 변환기)를 설계했습니다. , 이 수준의 동작을 학습하는 데 중점을 둡니다. RT-H는 관찰 내용과 높은 수준의 작업 설명을 분석하여 현재의 언어적 행동 지침을 예측함으로써 세부적인 수준에서 작업을 수행하는 방법을 이해합니다. 그런 다음 이러한 관찰, 작업 및 추론된 언어 행동을 사용하여 RT-H는 각 단계에 해당하는 행동을 예측합니다. 언어 행동은 프로세스에 추가 컨텍스트를 제공하여 특정 행동을 보다 정확하게 예측하는 데 도움이 됩니다(그림 1의 보라색 영역).
또한 로봇의 고유 감각에서 단순화된 언어 동작 세트를 추출하는 자동화된 방법을 개발하여 수동으로 주석을 달 필요 없이 2500개 이상의 언어 동작으로 구성된 풍부한 데이터베이스를 구축했습니다.
RT-H의 모델 아키텍처는 정책 학습 효과를 높이기 위해 인터넷 규모의 시각 및 언어 데이터를 공동 학습한 대규모 시각 언어 모델(VLM)인 RT-2를 기반으로 합니다. RT-H는 단일 모델을 사용하여 언어 작업과 작업 쿼리를 모두 처리하고 광범위한 인터넷 규모 지식을 활용하여 작업 계층 구조의 모든 수준을 강화합니다.
실험에서 연구원들은 언어 동작 계층 구조를 사용하면 다양한 다중 작업 데이터 세트를 처리할 때 상당한 개선을 가져올 수 있으며 RT-2에 비해 다양한 작업에서 성능이 15% 향상된다는 사실을 발견했습니다. 그들은 또한 음성 동작을 수정하면 동일한 작업에서 거의 완벽한 성공률을 가져오며 학습된 음성 동작의 유연성과 상황 적응성을 입증한다는 것을 발견했습니다. 또한, 언어 행동 개입 모델을 미세 조정함으로써 성능이 SOTA 대화형 모방 학습 방법(예: IWR)을 50% 초과합니다. 궁극적으로 그들은 RT-H의 언어 동작이 장면과 객체 변화에 더 잘 적응할 수 있으며 RT-2보다 더 나은 일반화 성능을 보여줄 수 있음을 입증했습니다.
다중 작업 데이터 세트(상위 수준 작업 설명으로 표시되지 않음)에서 공유 구조를 효과적으로 캡처하기 위해 RT-H는 작업 수준 정책을 명시적으로 활용하는 방법을 학습하는 것을 목표로 합니다.
구체적으로 연구팀은 정책 학습에 중간 언어 행동 예측 레이어를 도입했습니다. 로봇의 세분화된 동작을 설명하는 언어 작업은 다중 작업 데이터 세트에서 유용한 정보를 캡처하고 고성능 정책을 생성할 수 있습니다. 학습된 정책을 실행하기 어려울 때 언어적 행동이 다시 작동할 수 있습니다. 이는 주어진 시나리오와 관련된 온라인 인간 수정을 위한 직관적인 인터페이스를 제공합니다. 음성 동작에 대해 훈련된 정책은 자연스럽게 낮은 수준의 인간 수정을 따르고 수정 데이터가 제공된 작업을 성공적으로 완료할 수 있습니다. 또한 전략은 언어가 수정된 데이터로 학습되어 성능을 더욱 향상시킬 수도 있습니다.
그림 2에 표시된 것처럼 RT-H에는 두 가지 주요 단계가 있습니다. 먼저 작업 설명과 시각적 관찰을 기반으로 언어 동작을 예측하고, 예측된 언어 동작, 특정 작업 및 관찰 결과를 기반으로 정확한 동작을 추론합니다.
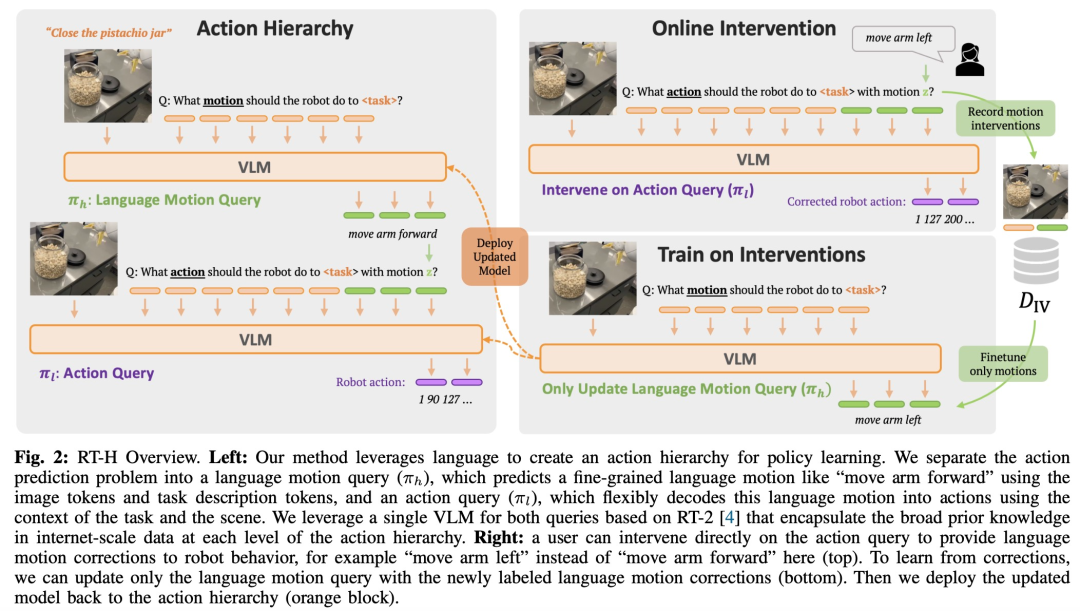
RT-H는 VLM 백본 네트워크를 사용하고 인스턴스화를 위해 RT-2의 교육 프로세스를 따릅니다. RT-2와 마찬가지로 RT-H는 협업 교육을 통해 인터넷 규모 데이터의 자연어 및 이미지 처리에 대한 광범위한 사전 지식을 활용합니다. 이러한 사전 지식을 행동 계층의 모든 수준에 통합하기 위해 단일 모델은 언어적 행동과 행동 쿼리를 동시에 학습합니다.
RT-H의 성능을 종합적으로 평가하기 위해 연구팀은 4가지 핵심 실험 질문을 설정했습니다. 작업 데이터세트에 대한 정책 성능이 향상되었나요?
Kitchen: RT-1 및 RT-2에서 사용되는 데이터세트로, 70K 샘플의 6개 의미 작업 범주로 구성됩니다.
1) 카운터에 그릇을 똑바로 세우기
2) 피스타치오 병 열기
3) 피스타치오 병을 닫습니다
4) 그릇을 시리얼 디스펜서에서 멀리 옮깁니다
5) 그릇을 시리얼 디스펜서 아래에 놓습니다
6) 오트밀을 그릇에 넣습니다
7) 바구니에서 숟가락 꺼내기
8) 디스펜서에서 냅킨 꺼내기
이 8가지 작업은 복잡한 동작 순서와 높은 정밀도가 필요하기 때문에 선택되었습니다.
아래 표는 Diverse+Kitchen 데이터세트 또는 Kitchen 데이터세트에 대한 교육 시 RT-H, RT-H-Joint 및 RT-2 교육 체크포인트에 대한 최소 MSE를 제공합니다. RT-H의 MSE는 RT-2보다 약 20% 낮고, RTH-Joint의 MSE는 RT-2보다 5~10% 낮습니다. 이는 동작 계층이 대규모 다중 작업에서 오프라인 동작 예측을 향상시키는 데 도움이 될 수 있음을 나타냅니다. 작업 데이터세트. RT-H(GT)는 Ground Truth MSE 측정법을 사용하고 종단 간 MSE에서 40%의 차이를 달성합니다. 이는 올바르게 레이블이 지정된 언어 동작이 동작 예측에 높은 정보 가치가 있음을 나타냅니다.
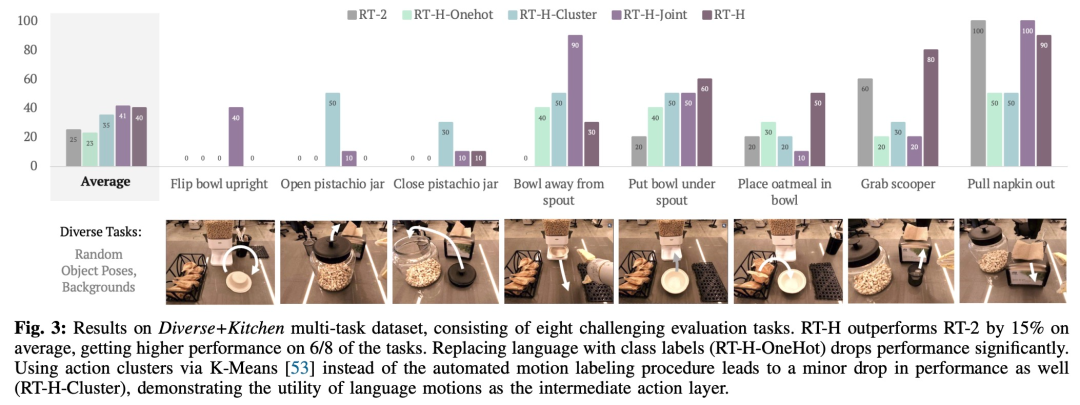
그림 4는 RT-H 온라인 평가에서 취한 상황별 조치의 몇 가지 예를 보여줍니다. 보시다시피, 동일한 언어적 행동은 더 높은 수준의 언어적 행동을 존중하면서도 작업을 달성하기 위한 행동에 미묘한 변화를 가져오는 경우가 많습니다.
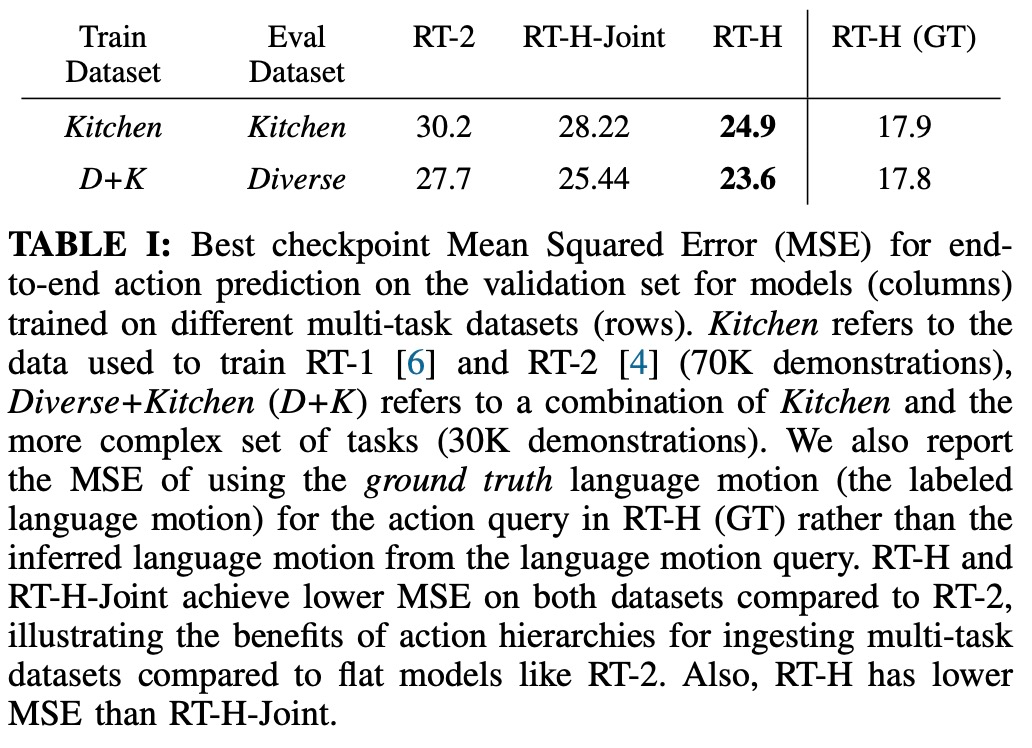
그림 5에서 볼 수 있듯이 연구팀은 RT-H의 언어 이동에 온라인으로 개입하여 RT-H의 유연성을 입증했습니다.

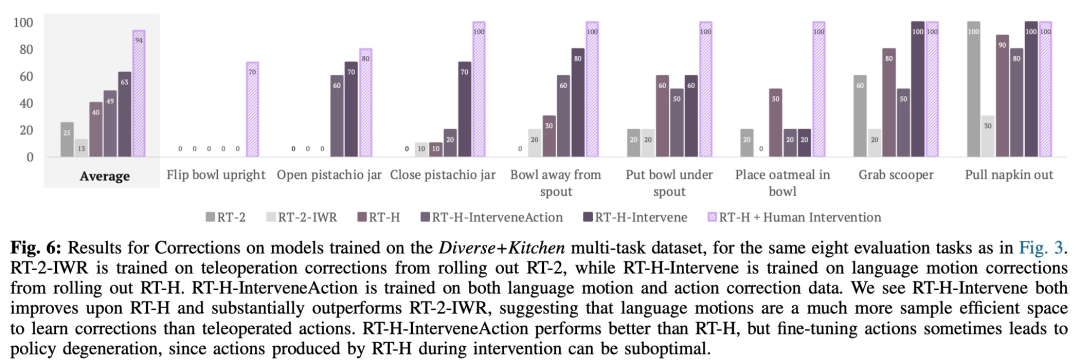
본 연구에서도 보정 효과를 분석하기 위해 비교 실험을 사용했습니다. 그 결과는 아래 그림 6과 같습니다.

그림 7과 같이 RT-H와 RT-H- 조인트는 장면에 다양한 영향을 미칩니다. 변경 사항이 눈에 띄게 더 강력해졌습니다.
실제로 서로 다른 것처럼 보이는 작업 간에는 공유 구조가 있습니다. 예를 들어 이러한 각 작업에는 작업을 시작하기 위해 몇 가지 선택 동작이 필요하며, RT-H는 다양한 작업 전반에 걸쳐 언어 동작의 공유 구조를 학습함으로써 이를 달성할 수 있습니다. .수정 없이 스테이지를 픽업합니다. RT-H가 더 이상 언어적 행동 예측을 일반화할 수 없는 경우에도 언어적 행동 수정은 종종 일반화되므로 작업을 성공적으로 완료하려면 몇 가지 수정만 필요합니다. 이는 새로운 작업에 대한 데이터 수집을 확장하기 위한 구두 조치의 잠재력을 보여줍니다. 관심 있는 독자는 논문 원문을 읽고 연구 내용에 대해 자세히 알아볼 수 있습니다. 
위 내용은 구현 지능에 대한 Google의 새로운 연구: RT-2보다 나은 RT-H가 여기에 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



