
생성형 대형 모델은 인공 지능 분야에 큰 변화를 가져왔습니다. 일반 인공 지능(AGI) 실현에 대한 사람들의 희망이 높아지고 있지만 대형 모델을 훈련하고 배포하는 데 필요한 컴퓨팅 성능도 점점 커지고 있습니다.
방금 Meta는 2개의 24k GPU 클러스터(총 49152 H100) 출시를 발표하여 인공 지능의 미래에 대한 Meta의 대규모 투자를 발표했습니다.
이것은 Meta의 야심찬 인프라 계획의 일부입니다. 2024년 말까지 Meta는 350,000개의 NVIDIA H100 GPU를 포함하도록 인프라를 확장하여 거의 600,000개의 H100에 해당하는 컴퓨팅 성능을 제공할 계획입니다. Meta는 미래의 요구 사항을 충족하기 위해 인프라를 지속적으로 확장하기 위해 최선을 다하고 있습니다.
Meta는 다음과 같이 강조했습니다. "우리는 오픈 컴퓨팅과 오픈 소스 기술을 확고히 지지합니다. 우리는 Grand Teton, OpenRack 및 PyTorch를 기반으로 이러한 컴퓨팅 클러스터를 구축했으며 업계 전반에 걸쳐 개방형 혁신을 지속적으로 촉진할 것입니다. 우리는 이를 활용할 것입니다. 라마 3 훈련을 위한 컴퓨팅 자원 클러스터.”
Turing Award 수상자이자 Meta 수석 과학자인 Yann LeCun도 트윗을 통해 이 점을 강조했습니다.
Meta는 다양한 인공 지능 워크로드에 높은 처리량과 높은 안정성을 제공하도록 설계된 새 클러스터의 하드웨어, 네트워크, 스토리지, 설계, 성능 및 소프트웨어에 대한 세부 정보를 공유했습니다.
Meta의 장기 비전은 모든 사람이 널리 활용하고 혜택을 누릴 수 있도록 개방적이고 책임감 있는 일반 인공지능을 구축하는 것입니다.
2022년 Meta는 16,000개의 NVIDIA A100 GPU를 갖춘 AI 연구 슈퍼 클러스터(RSC)의 세부 정보를 처음으로 공유했습니다. RSC는 Llama와 Llama 2의 개발은 물론 컴퓨터 비전, NLP, 음성 인식, 이미지 생성, 인코딩 등의 고급 인공 지능 모델 개발에 중요한 역할을 했습니다.
Meta의 최신 AI 클러스터는 이전 단계에서 얻은 성공과 교훈을 바탕으로 구축되었습니다. Meta는 종합적인 인공지능 시스템을 구축하겠다는 의지를 강조하고, 연구자와 개발자의 경험과 업무 효율성을 향상시키는 데 중점을 둡니다.
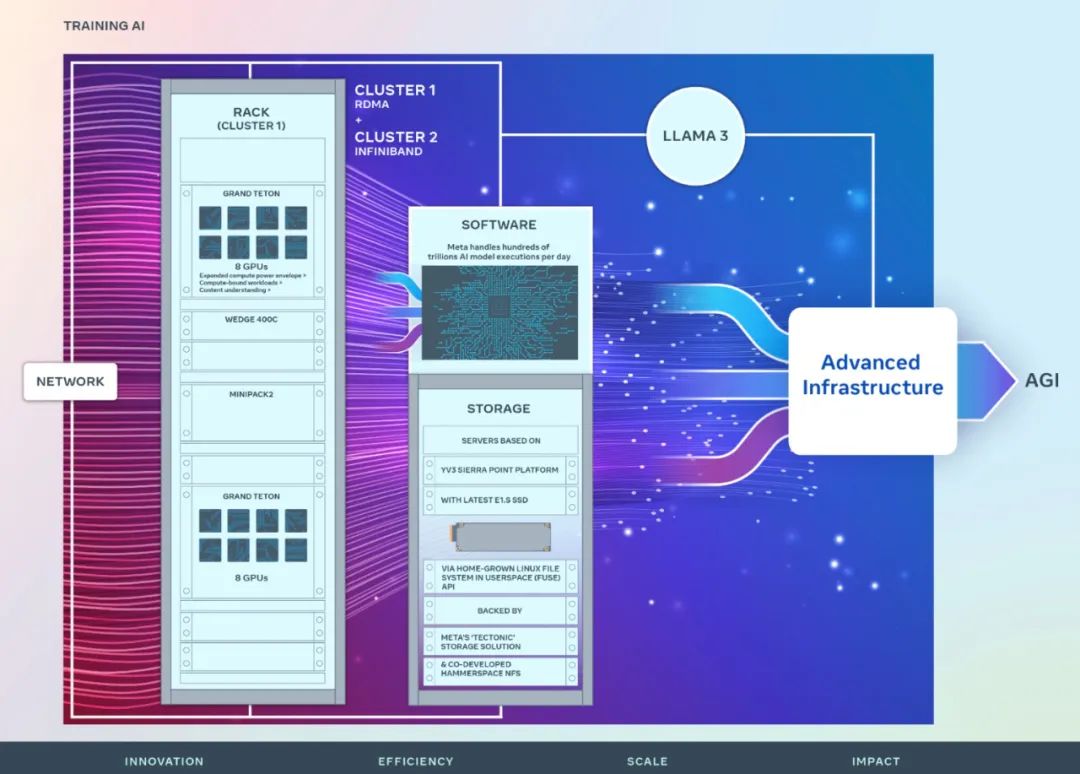
두 개의 새로운 클러스터에 사용된 고성능 네트워크 패브릭과 각 클러스터의 주요 스토리지 결정 및 24,576개의 NVIDIA Tensor Core H100 GPU가 결합되어 이 두 클러스터가 RSC 클러스터 모델보다 더 크고 복잡한 클러스터를 지원할 수 있습니다.
Network
Meta는 매일 수천억 개의 AI 모델 실행을 처리합니다. AI 모델을 대규모로 제공하려면 고도로 발전되고 유연한 인프라가 필요합니다.
Meta의 데이터 센터가 효율적으로 작동하도록 보장하면서 인공 지능 연구자를 위한 엔드 투 엔드 경험을 최적화하기 위해 Meta는 네트워크인 Arista 7800과 Wedge400 및 Minipack2 OCP 랙 스위치를 기반으로 클러스터 네트워크 통신 프로토콜을 구축했습니다. 이더넷을 통해 RDMA(Remote Direct Memory Access)를 구현하는 구조 클러스터입니다. 다른 클러스터는 NVIDIA Quantum2 InfiniBand 패브릭을 사용합니다. 두 솔루션 모두 400Gbps 엔드포인트를 상호 연결합니다.
이 두 개의 새로운 클러스터는 대규모 훈련을 위한 다양한 유형의 상호 연결의 적합성과 확장성을 평가하는 데 사용될 수 있으며, 이는 Meta가 향후 대규모 클러스터를 설계하고 구축하는 방법을 이해하는 데 도움이 됩니다. Meta는 네트워크, 소프트웨어 및 모델 아키텍처의 신중한 공동 설계를 통해 네트워크 병목 현상 없이 대규모 GenAI 워크로드에 RoCE 및 InfiniBand 클러스터를 성공적으로 활용했습니다.
Compute
두 클러스터 모두 Meta에서 자체적으로 설계된 개방형 GPU 하드웨어 플랫폼인 Grand Teton을 사용하여 구축되었습니다.
Grand Teton은 여러 세대의 AI 시스템을 기반으로 구축되어 전력, 제어, 컴퓨팅 및 패브릭 인터페이스를 단일 섀시에 통합하여 전반적인 성능, 신호 무결성 및 열 성능을 향상시킵니다. 단순화된 설계로 빠른 확장성과 유연성을 제공하므로 데이터 센터 전체에 신속하게 배포하고 쉽게 유지 관리 및 확장할 수 있습니다.
Storage
스토리지는 AI 훈련에서 중요한 역할을 하지만 가장 적게 언급되는 측면 중 하나입니다.
시간이 지남에 따라 GenAI 교육 노력은 더욱 다양해졌으며 대량의 이미지, 비디오 및 텍스트 데이터를 소비했으며 데이터 저장에 대한 수요가 급격히 증가했습니다.
Meta의 새 클러스터용 스토리지 배포는 Meta의 “Tectonic” 분산 스토리지 솔루션으로 구동되는 사용자 공간의 Native Linux File System(FUSE) API를 통해 AI 클러스터의 데이터 및 체크포인트 요구 사항을 충족합니다. 이 솔루션을 사용하면 수천 개의 GPU가 동기식으로 체크포인트를 저장하고 로드하는 동시에 데이터 로드에 필요한 유연하고 처리량이 높은 엑사바이트 규모의 스토리지를 제공할 수 있습니다.
Meta는 또한 Hammerspace와 협력하여 병렬 NFS(네트워크 파일 시스템) 배포를 공동으로 개발하고 구현합니다. Hammerspace를 사용하면 엔지니어는 수천 개의 GPU를 사용하여 작업에 대한 대화형 디버깅을 수행할 수 있습니다.
Performance
Meta 대규모 인공지능 클러스터를 구축하는 원칙 중 하나는 성능을 극대화하는 동시에 사용 편의성을 극대화하는 것입니다. 이는 최고의 AI 모델을 만들기 위한 중요한 원칙입니다.
메타 인공 지능 시스템의 한계를 뛰어넘을 때 확장 가능한 설계의 기능을 테스트하는 가장 좋은 방법은 단순히 시스템을 구축한 다음 최적화하고 실제로 테스트하는 것입니다(시뮬레이터가 도움이 되지만 한계는 한계가 있습니다) ).
이 설계에서 Meta는 병목 현상이 발생하는 위치를 파악하기 위해 소규모 클러스터와 대규모 클러스터의 성능을 비교했습니다. 다음은 다수의 GPU가 기대되는 성능이 가장 높은 통신 크기로 서로 통신할 때 집합적인 AllGather 성능(0~100 범위의 정규화된 대역폭으로 표현)을 나타냅니다.
대형 클러스터의 기본 성능은 최적화된 소규모 클러스터 성능에 비해 처음에는 열악하고 일관성이 없습니다. 이 문제를 해결하기 위해 Meta는 내부 작업 스케줄러가 네트워크 토폴로지 인식을 통해 조정되는 방식을 일부 변경하여 대기 시간 이점을 제공하고 네트워크 상위 계층에 대한 트래픽을 최소화했습니다.
Meta는 또한 최적의 네트워크 활용을 위해 NCCL(NVIDIA Collective Communications Library) 변경 사항과 결합된 네트워크 라우팅 전략을 최적화합니다. 이는 대규모 클러스터가 소규모 클러스터와 동일한 예상 성능을 달성하도록 유도하는 데 도움이 됩니다.
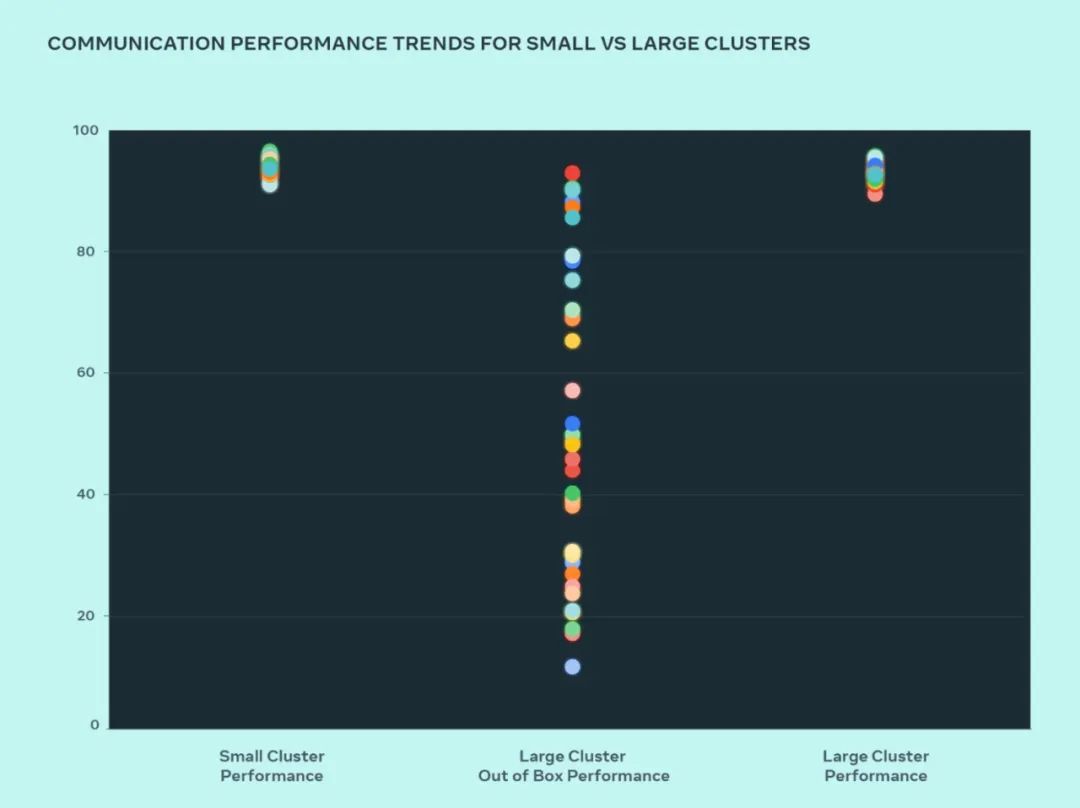
그림에서 볼 수 있듯이 소규모 클러스터 성능(전체 통신 대역폭 및 활용도)은 기본적으로 90% 이상에 도달하지만 최적화되지 않은 대규모 클러스터 성능 활용도는 10%에서 매우 낮습니다. 90%에서 90%로. 전체 시스템(소프트웨어, 네트워크 등)을 최적화한 후 대규모 클러스터 성능이 이상적인 90%+ 범위로 돌아오는 것을 확인했습니다.
내부 인프라의 소프트웨어 변경 외에도 Meta는 진화하는 인프라에 적응하기 위해 교육 프레임워크 및 모델을 작성하는 팀과 긴밀히 협력합니다. 예를 들어, NVIDIA H100 GPU는 8비트 부동 소수점(FP8)과 같은 새로운 데이터 유형으로 교육할 수 있는 가능성을 열어줍니다. 대규모 클러스터를 최대한 활용하려면 추가 병렬화 기술과 새로운 스토리지 솔루션에 대한 투자가 필요합니다. 이를 통해 수백 밀리초 내에 실행되도록 수천 수준의 체크포인트를 고도로 최적화할 수 있는 기회를 제공합니다.
Meta는 또한 디버그 가능성이 대규모 교육의 주요 과제 중 하나라는 것을 인식하고 있습니다. 전체 훈련을 지연시키는 잘못된 GPU를 식별하는 것은 대규모로 어렵습니다. Meta는 분산 교육의 세부 정보를 공개하고 더 빠르고 쉬운 방법으로 발생하는 문제를 식별하는 데 도움이 되는 비동기 디버깅 또는 분산 집단 비행 기록 장치와 같은 도구를 구축하고 있습니다.
위 내용은 Llama 3 훈련을 위해 설계되었으며 Meta 49,000 H100 클러스터의 세부 정보가 발표되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



