
대규모 언어 모델(llm)을 훈련하는 것은 계산 집약적인 작업입니다. 매개변수가 "단지" 70억 개인 경우에도 마찬가지입니다. 이 수준의 교육에는 대부분의 개인 매니아의 능력을 넘어서는 리소스가 필요합니다. 이러한 격차를 해소하기 위해 LoRA(낮은 순위 적응)와 같은 매개변수 효율적인 방법이 등장하여 소비자급 GPU에서 수많은 모델을 미세 조정할 수 있습니다.
GaLore는 단순히 매개변수 수를 줄이는 대신 최적화된 매개변수 트레이닝을 사용하여 VRAM 요구 사항을 줄이는 혁신적인 방법입니다. 이는 GaLore가 모델이 학습을 위한 모든 매개변수를 완전히 활용하고 LoRA보다 더 효율적으로 메모리를 절약할 수 있도록 하는 새로운 모델 훈련 전략임을 의미합니다.
GaLore는 주요 교육 정보를 유지하면서 이러한 그라데이션을 저차원 공간에 매핑하여 계산 부담을 효과적으로 줄입니다. 역전파 중에 모든 레이어를 한 번에 업데이트하는 기존 최적화 프로그램과 달리 GaLore는 역전파를 위해 레이어별 업데이트 방법을 사용합니다. 이 전략은 훈련 중에 메모리 사용량을 크게 줄이고 성능을 더욱 최적화합니다.
LoRA와 마찬가지로 GaLore를 사용하면 최대 24GB VRAM이 장착된 소비자급 GPU에서 7B 모델을 미세 조정할 수 있습니다. 결과는 모델의 성능이 전체 매개변수 미세 조정과 비슷하며 LoRA보다 더 나은 것으로 보입니다.
현재 공식 코드가 없습니다. 수동으로 논문의 코드를 사용하여 LoRA와 비교해 보겠습니다.
pip install galore-torch
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrsfrom transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,save_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "user", response_template = "assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()GaLore 최적화에는 다음과 같이 설정해야 하는 몇 가지 하이퍼 매개변수가 있습니다.
target_modules_list: GaLore 대상 레이어를 지정합니다.
rank: 투영 행렬의 순위. LoRA와 유사하게 순위가 높을수록 미세 조정이 전체 매개변수 미세 조정에 가까워집니다. GaLore의 저자는 7B에서 1024
update_proj_gap: 투영을 업데이트하는 단계 수를 사용하도록 권장합니다. 이는 비용이 많이 드는 단계이며 7B의 경우 약 15분이 소요됩니다. 투영 업데이트 간격을 정의합니다. 권장 범위는 50~1000단계입니다.
scale: 업데이트 강도를 조정하는 데 사용되는 LoRA의 알파와 유사한 배율 인수입니다. 여러 값을 시도한 후에 scale=2가 기존의 전체 매개변수 미세 조정에 가장 가깝다는 것을 알았습니다.
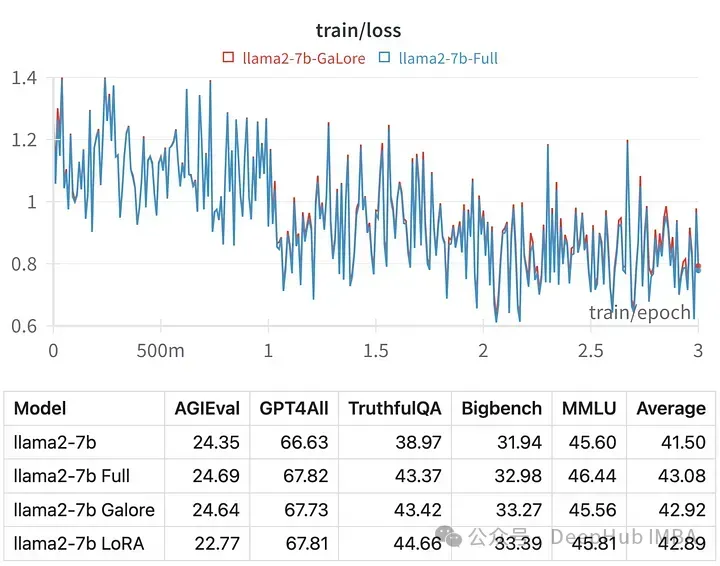
특정 하이퍼파라미터에 대한 훈련 손실은 전체 매개변수 조정의 궤적과 매우 유사하여 GaLore 계층화 방법이 실제로 동일하다는 것을 나타냅니다.
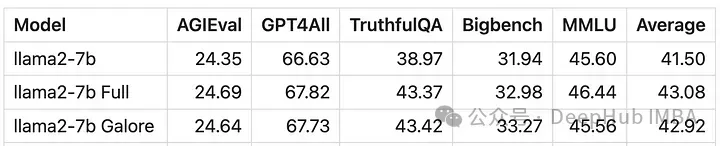
GaLore로 훈련된 모델의 점수는 전체 매개변수 미세 조정과 매우 유사합니다.
GaLore는 약 15GB의 VRAM을 절약할 수 있지만 정기적인 프로젝션 업데이트로 인해 훈련하는 데 시간이 더 오래 걸립니다.
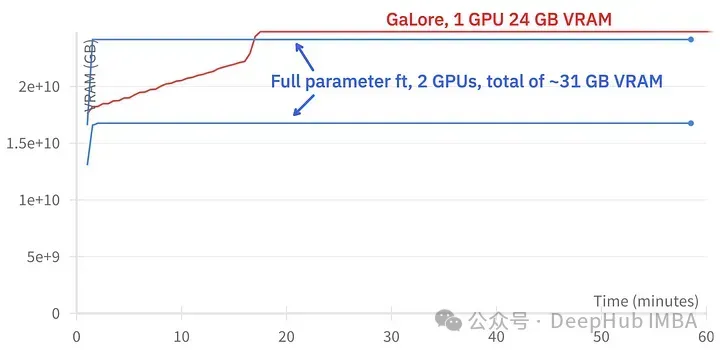
위 그림은 두 3090의 메모리 사용량 비교를 보여줍니다.
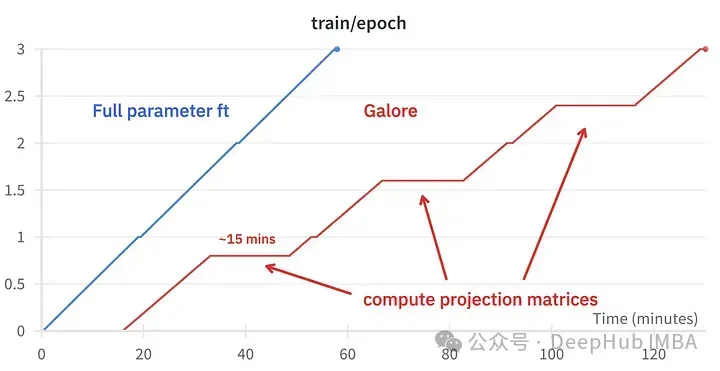
훈련 이벤트 비교, 미세 조정: ~58분. GaLore : 약 130분
마지막으로 GaLore와 LoRA의 비교를 살펴보겠습니다
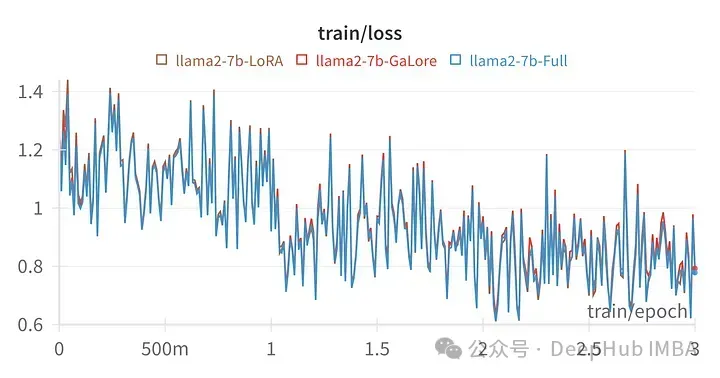
위 사진은 모든 선형 레이어를 미세 조정한 LoRA의 손실 차트, 랭크64, 알파 16
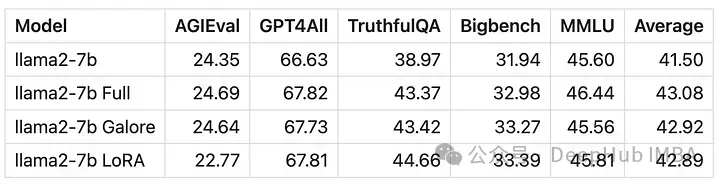
수치적으로 보면 GaLore는 전체 매개변수 훈련에 근접한 새로운 방법이며 성능은 미세 조정과 비슷하고 LoRA보다 훨씬 우수하다는 것을 알 수 있습니다.
GaLore는 VRAM을 절약하고 소비자 GPU에서 7B 모델 교육을 허용하지만 미세 조정 및 LoRA보다 속도가 느리고 시간이 거의 두 배 더 걸립니다.
위 내용은 GaLore를 사용하여 로컬 GPU에서 효율적인 LLM 튜닝의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



