
AIGC에 대해 더 알고 싶다면
51CTO AI를 방문하세요. Llama-2 레벨에서 대형 모델을 훈련하세요.
MoE
모델은 더 작지만 성능은 동일합니다.
JetMoE라고 하며 MIT, Princeton과 같은 연구 기관에서 나온 것입니다. 동일 크기의 Llama-2를 훨씬 능가하는 성능입니다.
ΔJia Yangqing이 리트윗
후자는수억 달러
수준의 투자 비용이 든다는 것을 알아야 합니다.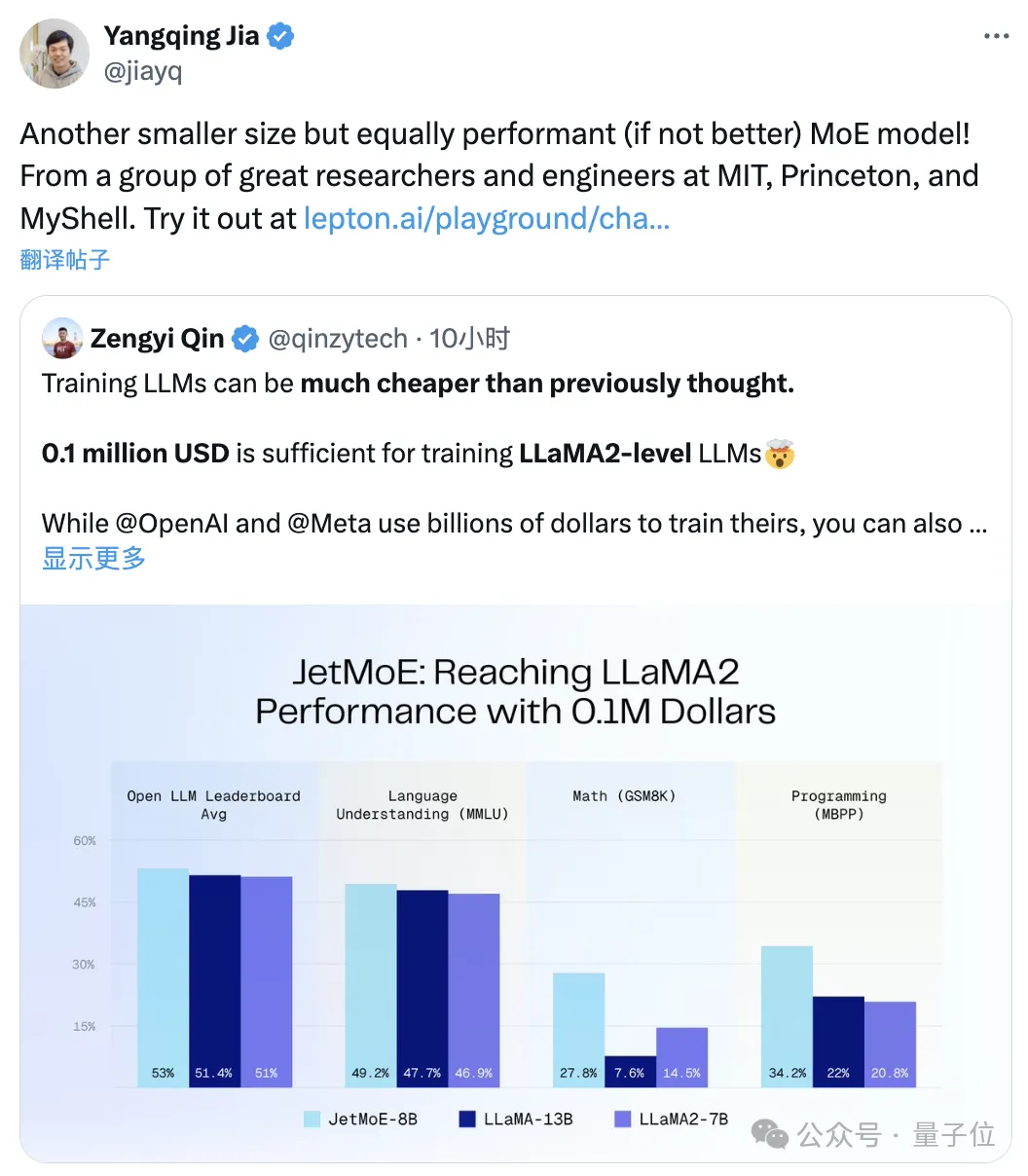
오픈 소스로 출시되었으며 학문적으로 친숙합니다. 공개 데이터 세트와 오픈 소스 코드만 사용하여 소비자급 GPU
로 미세 조정할 수 있습니다.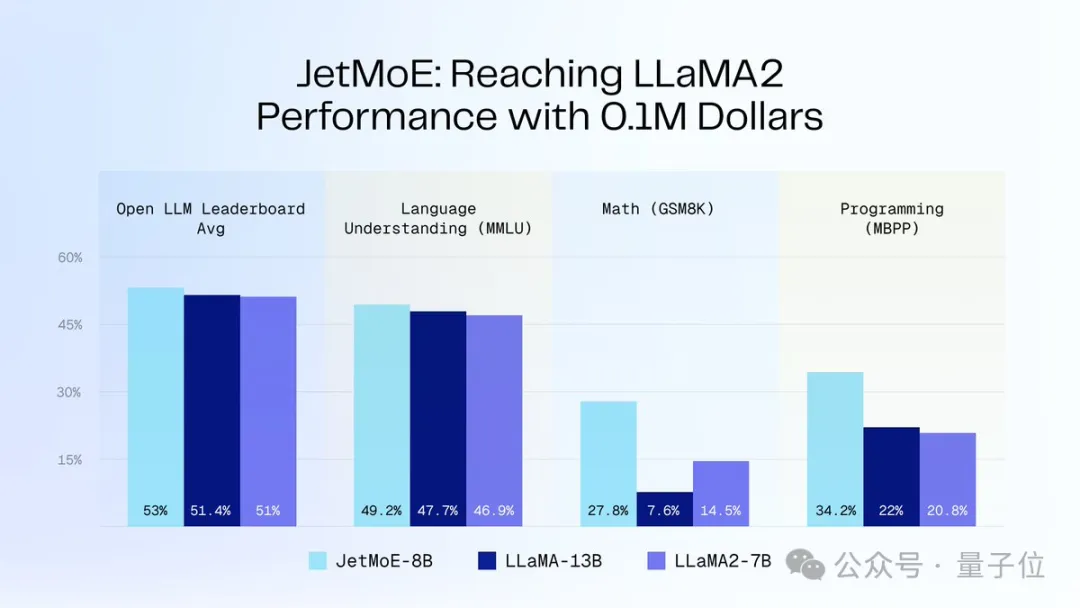 대형 모델을 제작하는 데 드는 비용은 사람들이 생각하는 것보다 정말 훨씬 저렴하다고 할 수 있습니다.
대형 모델을 제작하는 데 드는 비용은 사람들이 생각하는 것보다 정말 훨씬 저렴하다고 할 수 있습니다.
Stable Diffusion의 전 사장인 Emad도 좋아했습니다.
$100,000로 Llama-2 성능을 달성했습니다JetMoE는 ModuleFormer의 희소 활성화 아키텍처에서 영감을 받았습니다.
(대형 모델의 효율성과 유연성을 향상시키기 위해 SMoE(Sparse Mixture of Experts) 기반의 모듈식 아키텍처인 ModuleFormer, 작년 6월에 제안됨) 
JetMoE는 80억 개 매개변수에는 총 24개의 블록이 있으며, 각 블록에는 Attention Head Mixing
(MoA)및 MLP Expert Mixing (MoE) 이라는 2개의 MoE 레이어가 포함되어 있습니다.
각 MoA 및 MoE 계층에는 8명의 전문가가 있으며, 토큰이 입력될 때마다 2명이 활성화됩니다.
JetMoE-8B는 학습용 공개 데이터 세트에서
1.25T 토큰을 사용하며 학습률은 5.0 x 10-4이고 글로벌 배치 크기는 4M 토큰입니다.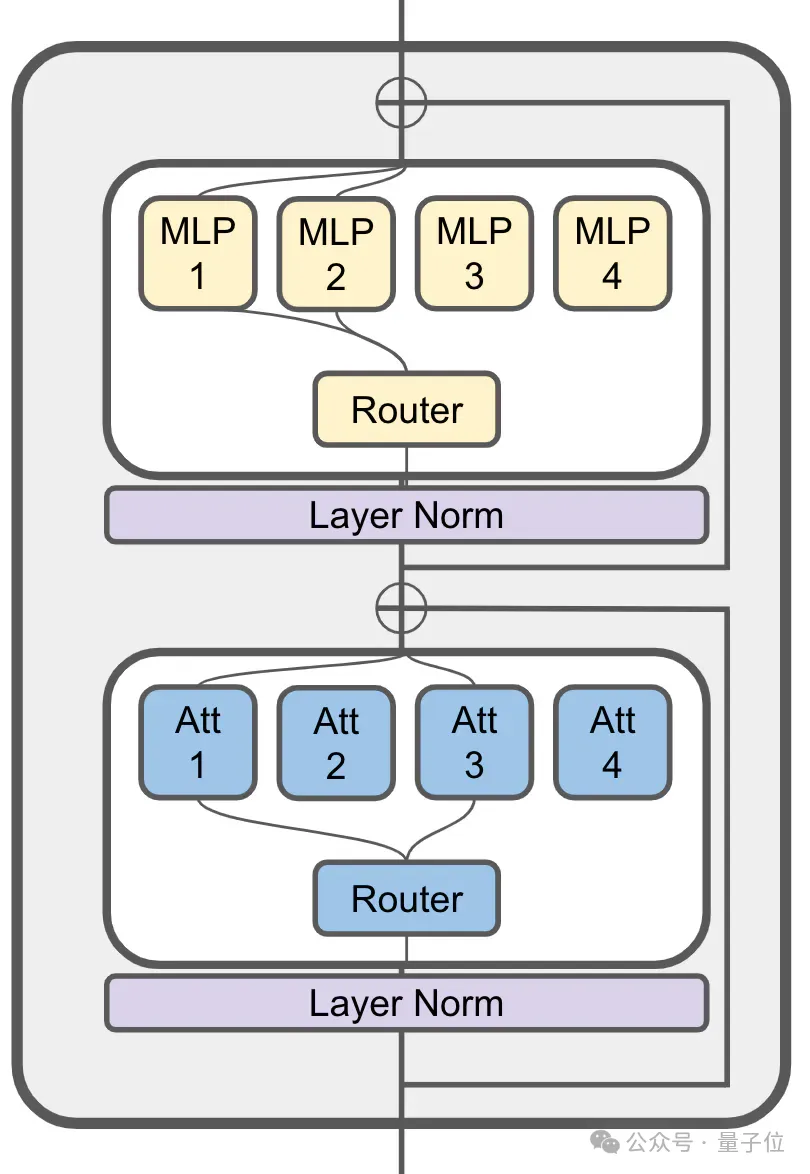
구체적인 훈련 계획은 MiniCPM(벽면 지능에서 2B 모델이 Mistral-7B를 따라잡을 수 있음)의 아이디어를 따르며
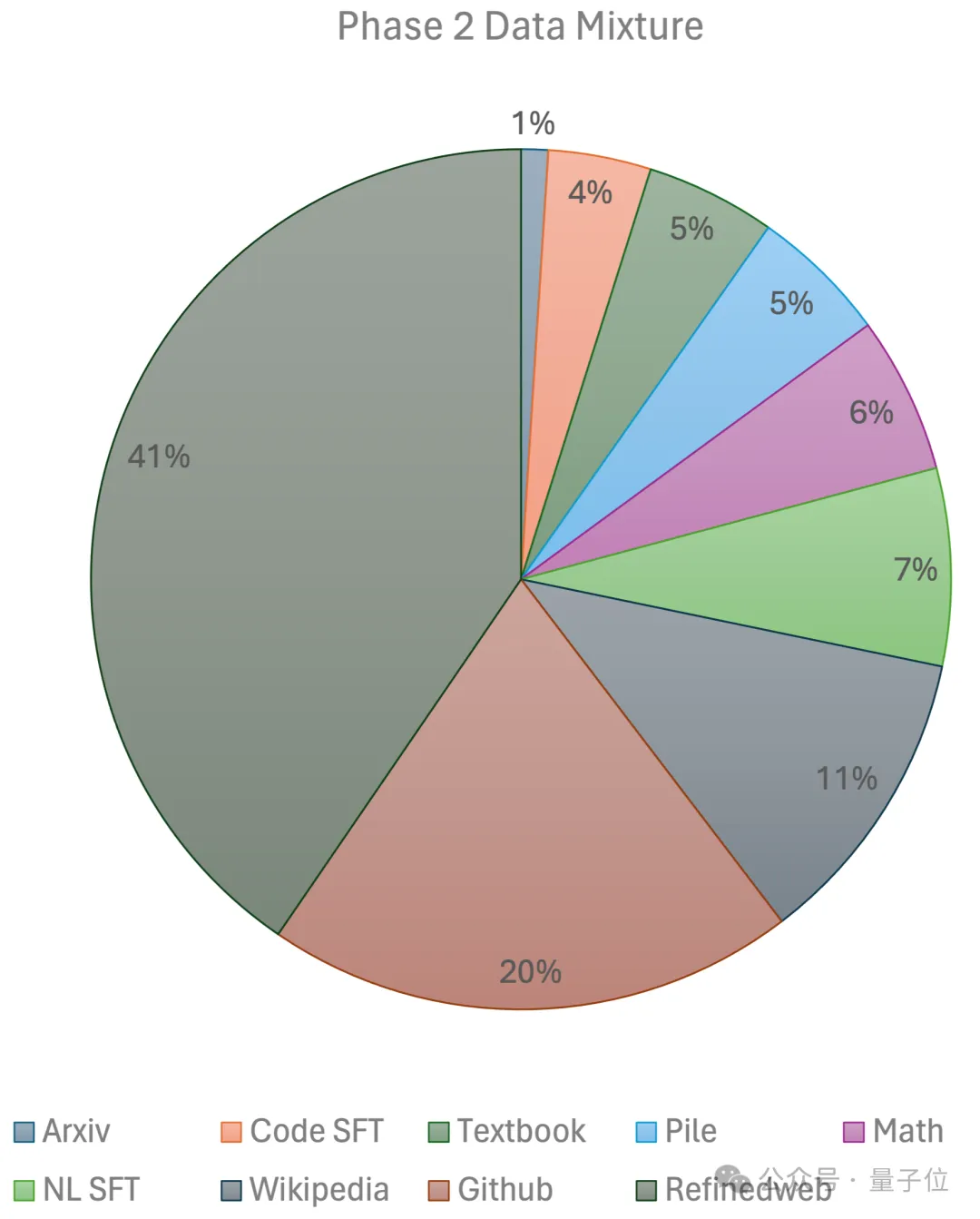
두 단계를 포함합니다. 첫 번째 단계는 선형 예열을 사용합니다. RefinedWeb, Pile, Github 데이터 등을 포함한 대규모 오픈 소스 사전 학습 데이터 세트에서 1조 개의 토큰으로 학습된 일정한 학습 속도입니다. 두 번째 단계에서는 지수적 학습 속도 감소를 사용하고 2,500억 개의 토큰을 사용하여 첫 번째 단계 데이터 세트와 초고품질 오픈 소스 데이터 세트에서 토큰을 훈련합니다.
결국 팀은 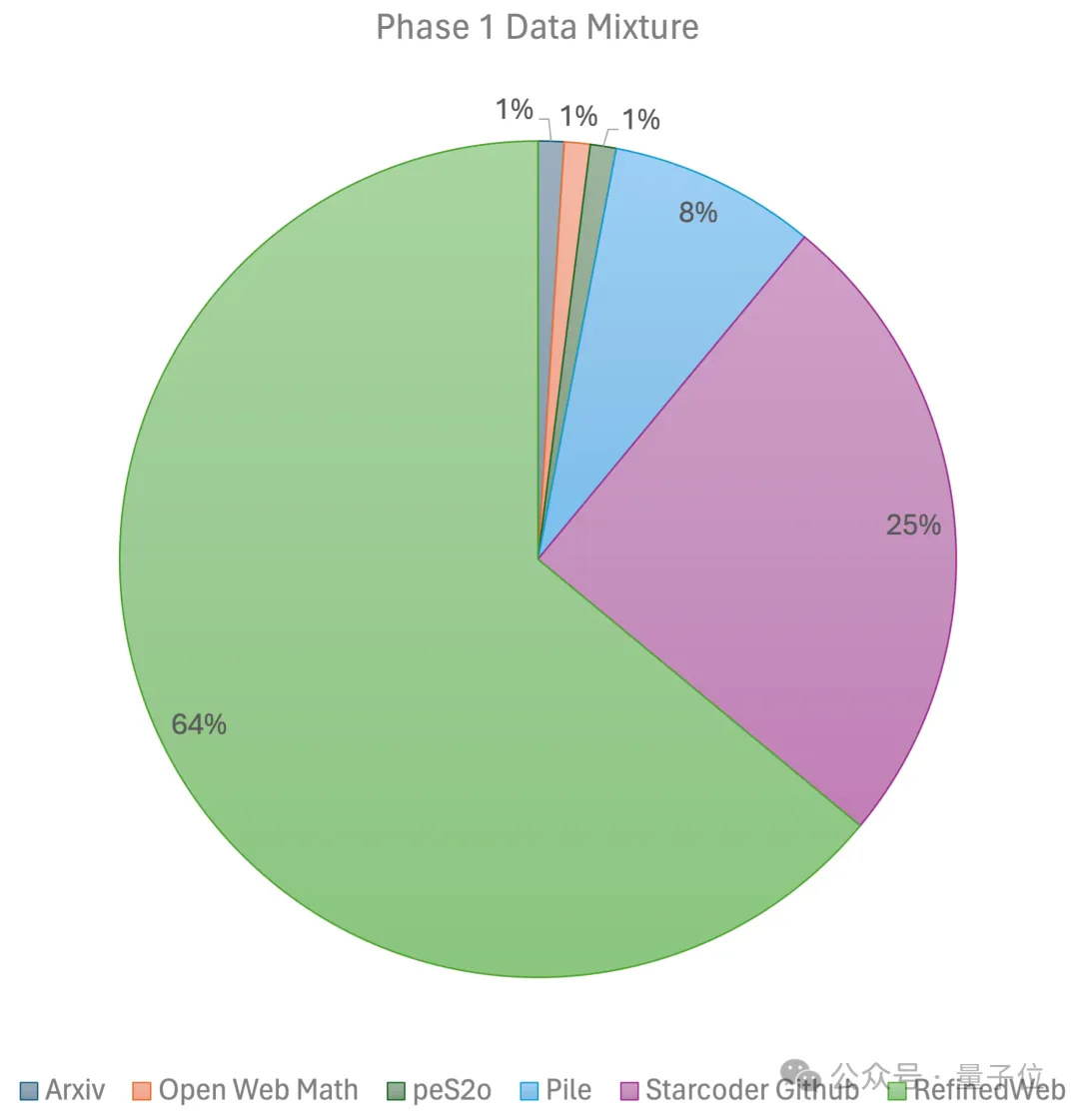
 약 80,000달러
약 80,000달러
를 들여 2주에 걸쳐 JetMoE-8B를 완성했습니다. 더 자세한 기술 내용은 곧 공개되는 기술 보고서에서 공개될 예정입니다. 추론 과정에서 JetMoE-8B에는 22억 활성화 매개변수만 있으므로 계산 비용이 크게 절감됩니다. -
동시에 좋은 성능도 달성했습니다.
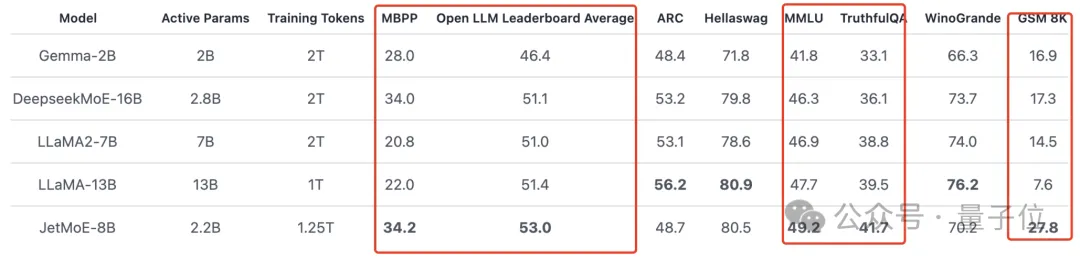
아래 그림과 같이: JetMoE-8B는 8개 평가 벤치마크(대형 모델 경기장 Open LLM Leaderboard 포함)에서 5 sota를 달성하여 LLaMA-13B, LLaMA2-7B 및 DeepseekMoE-16B를 능가합니다.
MT-Bench 벤치마크에서 6.681점을 기록했으며, 130억 개의 매개변수로 LLaMA2 및 Vicuna와 같은 모델을 능가했습니다.
저자 소개
 JetMoE에는 총 4명의 저자가 있습니다.
JetMoE에는 총 4명의 저자가 있습니다.
MIT-IBM Watson Lab 연구원, NLP 연구 방향.
베이항대학교에서 학사, 석사 학위를 취득하고 요슈아 벤지오(Yoshua Bengio)가 설립한 밀라 연구소에서 박사 학위를 취득했습니다.
그의 연구 방향은 3D 이미징을 위한 데이터 효율적인 기계 학습입니다.
UC Berkeley에서 학사 학위를 취득한 그는 지난 여름 MIT-IBM Watson Lab에 학생 연구원으로 합류했습니다. 그의 멘토는 Yikang Shen 외였습니다.
베이징 대학교에서 응용 수학과 컴퓨터 과학 학사 학위를 취득한 박사 과정입니다. 그는 현재 Together.ai에서 Tri Dao와 함께 일하고 있습니다. .
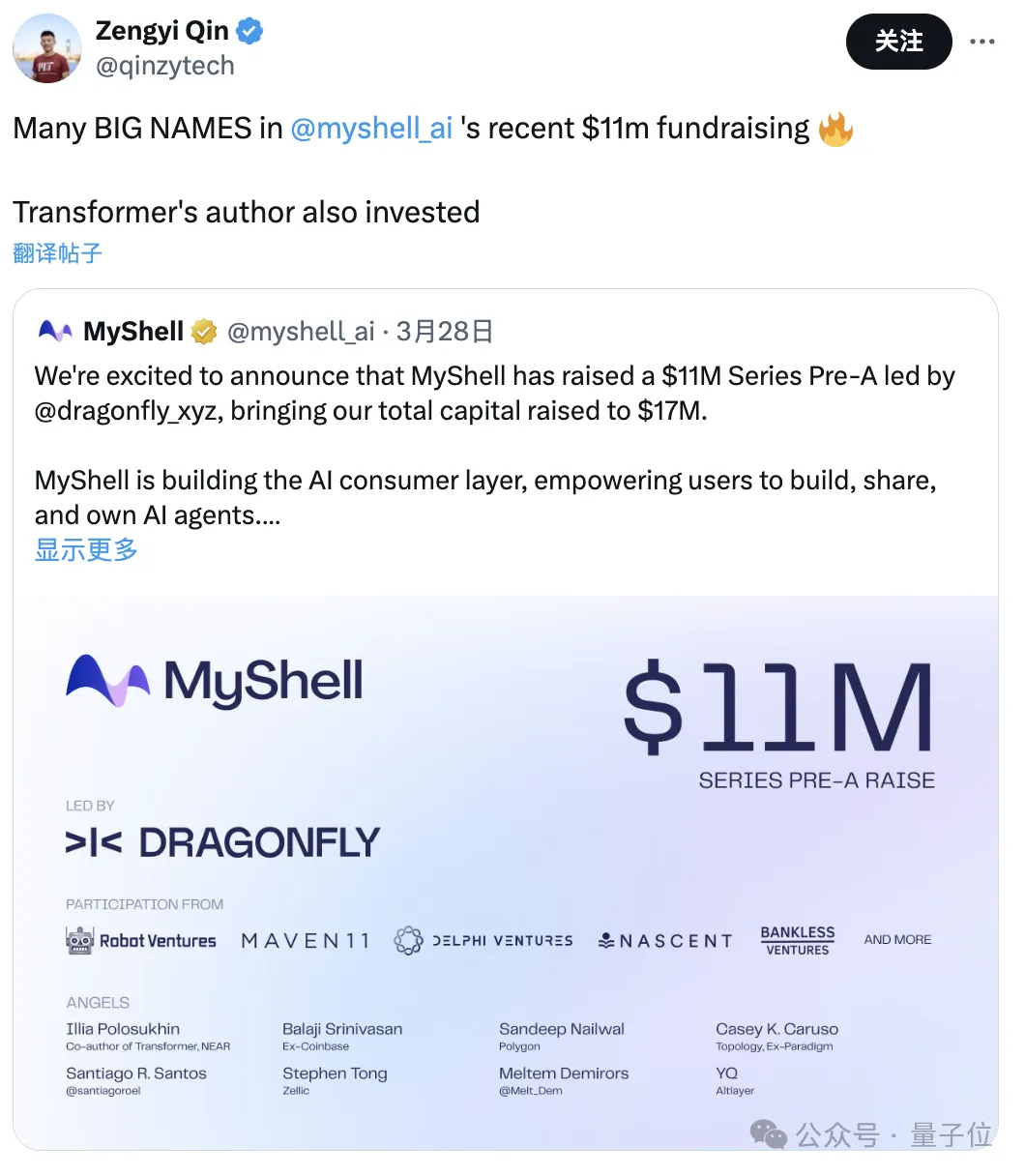
MIT 박사과정 학생이자 창업을 시작한 MyShell의 AI R&D 디렉터.
이 회사는 방금 1,100만 달러를 모금했으며 투자자에는 Transformer의 저자도 포함됩니다.
포털: https://github.com/myshell-ai/JetMoE
참조 링크: https://twitter.com/jiayq/status/1775935845205463292
AIGC에 대해 더 알고 싶으세요? 콘텐츠를 보려면
51CTO AI를 방문하세요.
위 내용은 Llama-2 대형 모델을 훈련시키는 데 100,000달러! 모든 중국인이 새로운 MoE를 구축하고 SD 전 CEO Jia Yangqing이 지켜보고 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



