

궤도 예측 시리즈 | HiVT QCNet의 진화된 버전은 무엇에 대해 이야기합니까?

성능과 효율성이 크게 향상된 HiVT의 진화된 버전(HiVT를 먼저 읽지 않고도 이 기사를 직접 읽을 수 있음).
글도 읽기 쉽습니다.
[궤적 예측 시리즈] [참고] HiVT: 다중 에이전트 모션 예측을 위한 계층적 벡터 변환기 - Zhihu (zhihu.com)
원본 링크:
https://openaccess.thecvf.com/content/CVPR2023/ papers /Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf
Abstract
에이전트를 예측 센터로 사용하는 모델에는 창이 이동할 때 에이전트 센터로 정규화하기 위해 여러 번 반복해야 하는 문제가 있습니다. 그런 다음 인코딩 프로세스를 반복하십시오. 온보드 사용에는 적합하지 않습니다. 따라서 우리는 계산된 결과를 재사용할 수 있고 글로벌 시간 좌표계에 의존하지 않는 쿼리 중심 프레임워크를 장면 인코딩에 사용합니다. 동시에 장면 특징이 서로 다른 에이전트 간에 공유되기 때문에 에이전트의 궤적 디코딩 프로세스가 더 병렬적으로 처리될 수 있습니다.
장면이 복잡하게 인코딩되어 있으며 현재 디코딩 방법으로는 특히 장기 예측의 경우 모드 정보를 캡처하기가 여전히 어렵습니다. 이 문제를 해결하기 위해 먼저 앵커 없는 쿼리를 사용하여 궤적 제안(단계별 특징 추출 방법)을 생성하여 모델이 다양한 시간에 장면 특징을 더 잘 활용할 수 있도록 합니다. 그런 다음 이전 단계에서 얻은 제안을 사용하여 궤적을 최적화하는 조정 모듈이 있습니다(동적 앵커 기반). 이러한 고품질 앵커를 통해 쿼리 기반 디코더는 모드의 특성을 더 잘 처리할 수 있습니다.
순위가 성공적으로 매겨졌습니다. 이 디자인은 또한 시나리오 기능 인코딩 및 병렬 다중 에이전트 디코딩 파이프라인을 구현합니다.
서론
현재의 궤적 예측지는 다음과 같은 문제점을 가지고 있습니다.
- 여러 이종 장면 정보에 대한 정보 처리 효율이 낮습니다. 무인 운전 작업에서는 벡터화된 고정밀 지도와 주변 에이전트의 과거 궤적을 포함하여 데이터가 프레임별로 모델로 스트리밍됩니다. 최근의 요인화된 주의 방법(공간과 시간에 대한 별도의 주의)은 이 정보 처리를 새로운 수준으로 끌어올렸습니다. 하지만 이를 위해서는 각 장면 요소에 주의가 필요합니다. 장면이 매우 복잡하다면 비용은 여전히 매우 높습니다.
- 예보 시간이 길어질수록 예보의 불확실성도 폭발합니다. 예를 들어, 교차로의 자동차는 직진하거나 회전할 수 있습니다. 잠재적 가능성의 누락을 방지하기 위해 모델은 빈도가 가장 높은 모드를 예측하는 대신 여러 모드의 분포를 얻어야 합니다. 하지만 gt는 하나뿐이고 여러 가능성에 대해 더 나은 학습을 수행하는 것은 불가능합니다. 일부 논문에서는 감독을 위해 여러 개의 휴대용 앵커를 사용하는 방법을 제안합니다. 이 효과는 전적으로 앵커의 품질에 달려 있습니다. 이 접근 방식은 앵커가 GT를 정확하게 덮을 수 없는 경우 매우 나쁩니다. 모드 붕괴 및 훈련 불안정성 문제를 무시하고 다중 모드를 직접 예측하는 다른 접근 방식도 있습니다.
위의 문제를 해결하기 위해 우리는 QCNet을 제안했습니다.
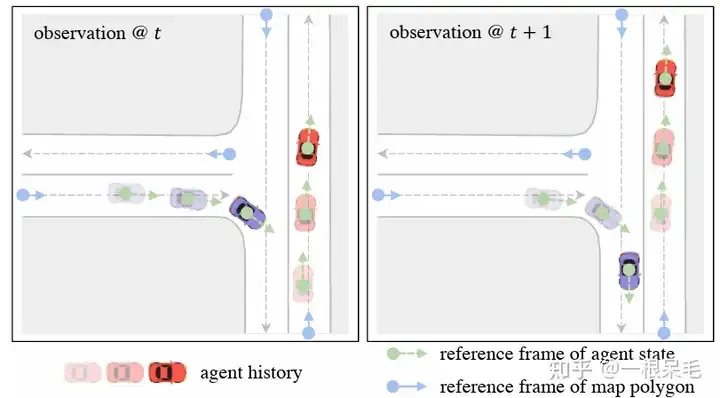
우선, 우리는 강력한 Factorized attention을 잘 활용하면서 onboard의 추론 속도를 향상시키고 싶습니다. 과거의 에이전트 중심 인코딩 방법은 분명히 작동하지 않습니다. 다음 데이터 프레임이 도착하면 창이 이동하지만 여전히 이전 프레임과 크게 겹치므로 이러한 기능을 재사용할 수 있는 기회가 있습니다. 하지만 에이전트 중심 방식은 에이전트 좌표계로 전환해야 하므로 장면을 다시 인코딩해야 합니다. 이 문제를 해결하기 위해 우리는 쿼리 중심 방법을 사용합니다. 장면 요소는 전역 좌표계(자아가 어디에 있는지는 중요하지 않음)에 관계없이 자체 시공간 좌표계 내에서 특징을 추출합니다. (지도 요소에는 장기 ID가 있으므로 고정밀 지도를 사용할 수 있습니다. HD가 아닌 지도는 유용하지 않을 수 있습니다. 지도 요소는 이전 프레임과 다음 프레임에서 추적해야 합니다.)
이를 통해 이전에 처리된 결과는 재사용되며 에이전트는 이러한 캐시의 기능을 직접 사용하므로 대기 시간이 절약됩니다.
두 번째로, 다중 모드 장기 예측을 위해 이러한 장면 인코딩 결과를 더 잘 사용하기 위해 앵커 없는 쿼리를 사용하여 장면 특징을 단계별로(이전 위치에서) 추출하므로 모든 디코드는 아주 짧은 걸음. 이 접근 방식을 사용하면 미래의 여러 순간의 위치를 고려하기 위해 멀리 있는 특징을 추출하는 대신 장면의 특징 추출이 미래 에이전트의 특정 위치에 집중할 수 있습니다. 이렇게 얻은 고품질 앵커는 다음 Refine 모듈에서 세밀하게 조정될 예정입니다. 이 앵커 없는 방식과 앵커 기반의 조합은 두 가지 방법의 장점을 최대한 활용하여 다중 모드 및 장기 예측을 달성합니다.
이 접근 방식은 고속 추론을 달성하기 위해 궤적 예측의 연속성을 탐색하는 최초의 접근 방식입니다. 동시에 디코더 부분은 다중 모드 및 장기 예측 작업도 고려합니다.
접근법
입력 및 출력

동시에 예측 모듈은 고정밀 지도에서 M개의 다각형을 얻을 수도 있습니다. 각 다각형에는 여러 지점과 의미 정보(횡단보도, 차선 등)가 있습니다.
예측 모듈은 위의 에이전트 상태와 T 순간의 맵 정보를 사용하여 총 길이가 T'인 K개의 예측 궤적과 확률 분포를 제공합니다.
쿼리 중심 장면 컨텍스트 인코딩
첫 번째 단계는 자연스럽게 장면을 인코딩하는 것입니다. 현재 인기 있는 Factorized attention(각각 시간 차원과 공간 차원에서의 주의)은 이러한 방식으로 수행됩니다. 구체적으로 세 가지 단계가 있습니다:
- 시간 차원 주의, 시간 복잡도 O(A), 각 에이전트의 시간 차원 행렬 곱셈
- 에이전트와 맵의 교차 주목, 시간 복잡도 O(ATM), 매 순간 에이전트와 맵 요소의 행렬 곱셈
- 에이전트와 에이전트 간 주목, 시간 복잡도 O(T), 매 순간 에이전트 시간 차원의 특징을 현재 순간으로 압축한 후 에이전트와 맵 사이에서 상호 작용하는 이전 방법과 비교하면 이 방법은 각 순간에 대한 것입니다. 과거에 상호작용하려면 매 순간 에이전트와 지도 간의 상호작용이 어떻게 전개되는지 등 더 많은 정보를 얻을 수 있습니다.
Local Spacetime Coordinate System
시간 t에서 에이전트 i의 특징에 대해 이때의 위치와 방향을 기준 시스템으로 선택합니다. 지도 요소의 경우 이 요소의 시작점이 참조 프레임으로 사용됩니다. 이러한 참조 시스템 선택 방법은 자아가 이동한 후에도 추출된 특징을 변경하지 않고 유지할 수 있습니다.
장면 요소 삽입
각 요소 내의 다른 벡터 특징의 경우 극좌표 표현은 위의 참조 시스템에서 얻어집니다. 그런 다음 푸리에 기능으로 변환되어 고주파 신호를 얻습니다. 의미론적 특징을 연결한 후 MLP는 특징을 얻습니다. 맵 요소의 경우 내부 포인트의 순서가 관련되지 않도록 주의(attention)를 먼저 수행한 후 풀링(pooling)을 수행합니다. 마지막으로 에이전트 특성은 [A, T, D]이고 맵 특성은 [M, D]입니다. D는 특성 차원을 일관되게 유지해야만 주의의 행렬 곱셈이 촉진될 수 있습니다. 이렇게 추출된 특징은 어디에서나 ego를 사용할 수 있게 해줍니다.
푸리에 임베딩: 다양한 주파수의 가중치에 해당하는 정규 분포 임베딩을 생성하고 입력 합에 2Π를 곱한 후 마지막으로 cos와 sin을 특징으로 취합니다. 직관적인 이해는 입력을 신호로 처리하고 신호를 여러 기본 신호(다중 주파수의 신호)로 디코딩하는 것입니다. 이는 고주파 신호를 더 잘 포착할 수 있습니다. 고주파 신호는 결과의 정밀도에 매우 중요합니다. 일반적인 방법에서는 미세한 고주파 신호가 쉽게 손실될 수 있습니다. 노이즈가 있는 데이터를 사용하면 실수로 잘못된 고주파 신호를 캡처할 수 있으므로 권장하지 않는다는 점은 주목할 가치가 있습니다. (너무 일반적이지는 않지만 너무 정확하지는 않은 약간 오버핏 느낌)Relative Spatial-Temporal Positional Embedding
 Map Encoding을 위한 Self-Attention
Map Encoding을 위한 Self-Attention
 Factorized Attention for Agent Encoding
Factorized Attention for Agent Encoding

 Nearby는 상담원 주변 50m 이내로 정의됩니다. 총 횟수가 수행됩니다.
Nearby는 상담원 주변 50m 이내로 정의됩니다. 총 횟수가 수행됩니다. 
위의 방법을 통해 얻은 특징은 시공간 불변성을 갖는다는 점, 즉 자아가 언제 어디로 가든지 현재 위치 정보를 기준으로 한 이동이나 회전이 없기 때문에 위의 특징은 변하지 않는다는 점에 주목할 필요가 있습니다. 이전 프레임과 비교하여 새로운 데이터 프레임만 있으므로 이전 순간의 특징을 계산할 필요가 없으므로 전체 계산 복잡도를 T로 나눕니다.

쿼리 기반 궤적 디코딩
특정 키 값에 주의를 기울이는 DETR의 앵커 프리 쿼리 방법과 유사하게 훈련이 불안정하고 모드 붕괴 문제가 발생하며 장기적인 예측도 어렵습니다. 불확실성은 나중에 폭발할 것이기 때문에 신뢰할 수 없습니다. 따라서 이 모델은 먼저 대략적인 앵커 없는 쿼리 방법을 사용한 다음 이 출력에 대해 앵커 기반 방법을 개선합니다.
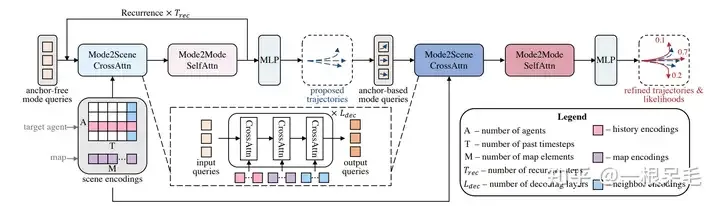 전체 네트워크 구조
전체 네트워크 구조
Mode2Scene 및 Mode2Mode Attention
Mode2Scene은 두 단계 모두에서 DETR 구조를 사용합니다. 쿼리는 K 궤적 모드입니다(대략적인 제안 단계는 직접 무작위로 생성되고 개선 단계는 제안에서 얻음) 기능을 입력으로 단계화한 다음 장면 기능(에이전트 기록, 지도, 주변 에이전트)에 대해 다중 교차 주의를 수행합니다.
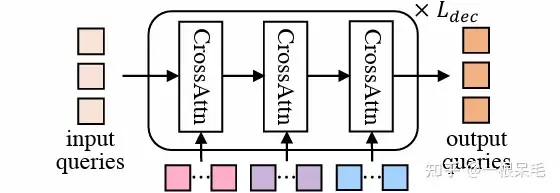 DETR 구조
DETR 구조
Mode2Mode는 K 모드 중에서 Self Attention을 수행하여 모드 간의 다양성을 실현하여 모든 모드를 하나로 모으지 않도록 노력합니다.
모드 쿼리의 참조 프레임
여러 에이전트의 궤적을 병렬로 예측하기 위해 장면의 인코딩은 여러 에이전트가 공유합니다. 장면 기능은 모두 그 자체와 관련된 기능이므로 사용하려면 에이전트의 관점으로 전환해야 합니다. 모드 쿼리의 경우 에이전트의 위치 및 방향 정보가 추가됩니다. 이전의 상대 위치 인코딩 작업과 유사하게 장면 요소와 에이전트의 상대 위치 정보도 키와 값으로 포함됩니다. (직관적으로 말하면, 주변 정보 사용에 대한 에이전트의 각 모드의 가중치 관심)
Anchor-Free Trajectory Proposal
첫 번째는 Anchor Free 방법으로 학습 가능한 쿼리를 사용하여 상대적으로 낮은 경로를 생성합니다. 품질 궤적 제안은 총 K개의 제안을 생성합니다. Cross Attention은 장면 정보에서 특징을 추출하는 데 사용되므로 상대적으로 작고 효과적인 앵커를 효율적으로 생성하여 두 번째 리파인에 사용할 수 있습니다. 자기 관심은 각 제안을 전체적으로 더욱 다양하게 만듭니다.

Anchor-Based Trajectory Refinement
Anchor Free 방식은 상대적으로 간단하지만 훈련이 불안정하고 모드 붕괴가 발생할 수 있다는 문제도 있습니다. 동시에 무작위로 생성된 모드는 전체 장면의 다양한 에이전트에 대해 잘 수행될 수 있어야 하며 이는 어렵고 운동학이나 교통과 일치하지 않는 궤적 제안을 생성하기 쉽습니다. 그래서 우리는 또 다른 앵커 기반 수정을 생각했습니다. 제안(수정된 궤도를 얻기 위해 원래 제안에 추가됨)을 기반으로 오프셋을 예측하고 각각의 새로운 궤도의 확률을 예측합니다.
이 모듈도 DETR 형식을 사용합니다. 이전 단계의 제안을 사용하여 각 모드의 쿼리를 추출합니다. 구체적으로 각 앵커를 삽입(단계 전진)하는 데 사용되며 끝까지 사용됩니다. 순간의 특징이 쿼리 역할을 합니다. 이러한 앵커 기반 쿼리는 특정 공간 정보를 제공하여 주의를 기울이는 동안 유용한 정보를 더 쉽게 캡처할 수 있습니다.
교육 목표
HiVT와 동일합니다(HiVT의 분석 참조). Laplace 분포를 사용합니다. 직설적으로 말하면, 각 모드의 각 순간은 라플라스 분포(일반 가우스 분포 참조, 여기서 평균과 var는 이 점의 위치와 불확실성을 나타냄)로 모델링됩니다. 그리고 적률은 독립적인(직접 곱한) 것으로 간주됩니다. Π는 해당 모드의 확률을 나타냅니다.
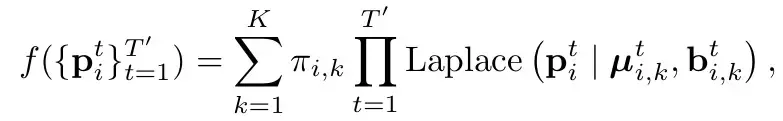
손실은 3가지 부분으로 구성됩니다
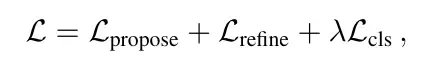
크게 분류 손실과 회귀 손실 두 부분으로 나뉩니다.
분류 손실은 예측 확률의 손실을 의미합니다. 여기서 주목해야 할 점은 그라디언트 반환을 중단해야 하며 확률로 인한 그라데이션은 좌표 예측에 전달할 수 없다는 것입니다. 각 모드의 예상 위치는 합리적인 전제하에 있습니다). gt에 가장 가까운 레이블은 1이고 나머지 레이블은 0입니다.
회귀 손실은 두 가지가 있는데, 하나는 1단계 제안의 손실이고, 다른 하나는 2단계 정제의 손실입니다. 승자 독식 방식이 채택되었습니다. 즉, gt에 가장 가까운 모드의 손실만 계산하고 두 단계의 회귀 손실을 계산합니다. 훈련의 안정성을 위해 그래디언트 리턴도 두 단계에서 중단되므로 제안 학습은 제안만 학습하고 정제는 정제만 학습합니다.
ExperimentsArgoverse2 basic SOTA (*는 앙상블 기법이 사용됨을 나타냄)
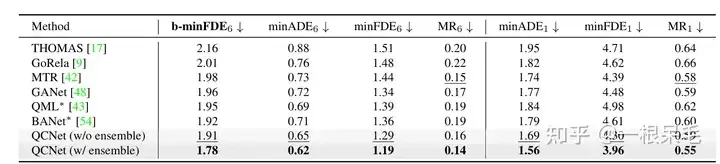 b-minFDE와 minFDE의 차이점은 확률과 관련된 추가 계수를 곱한다는 점입니다. 목표는 FDE가 가장 작기를 원합니다. 해당 궤도의 확률이 높을수록 좋습니다.
b-minFDE와 minFDE의 차이점은 확률과 관련된 추가 계수를 곱한다는 점입니다. 목표는 FDE가 가장 작기를 원합니다. 해당 궤도의 확률이 높을수록 좋습니다.
앙상블 테크닉에 관해서는 약간 부정확한 느낌이 듭니다. 아래에 간략하게 소개된 BANet의 소개를 참고하시면 됩니다.
궤적 생성의 마지막 단계는 동일한 구조를 가진 여러 하위 모델(디코더)을 동시에 연결하는 것입니다. 그러면 여러 예측 세트가 제공됩니다. 예를 들어 각각 6개의 예측이 포함된 7개의 하위 모델이 있으며 총 42개입니다. . 그런 다음 kmeans를 사용하여 클러스터링을 수행합니다(마지막 좌표점을 클러스터링 기준으로 사용). 목표는 6개 그룹, 각 그룹당 7개 항목이며, 각 그룹에서 가중 평균을 수행하여 새로운 궤적을 얻습니다.
가중치 방법은 현재 궤적의 b-minFDE와 gt이며, c는 각 그룹별로 가중치를 계산한 후 궤적 좌표를 합산합니다. 새로운 궤도를 얻습니다. (c는 실제로 하위 모델 출력에서 이 궤도의 확률이고 클러스터링에 사용될 때 기대와 약간 일치하지 않기 때문에 약간 까다롭게 느껴집니다.)
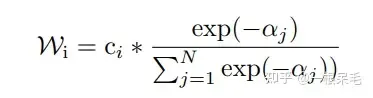 그리고 이 작업 후 새로운 궤도의 확률은 다음과 같습니다. 또한 정확하게 계산하기 어렵기 때문에 위의 방법을 사용할 수 없습니다. 그렇지 않으면 총 확률 합계가 반드시 1이 될 수는 없습니다. 동일한 가중치를 가진 클러스터에서만 확률을 계산할 수 있는 것 같습니다.
그리고 이 작업 후 새로운 궤도의 확률은 다음과 같습니다. 또한 정확하게 계산하기 어렵기 때문에 위의 방법을 사용할 수 없습니다. 그렇지 않으면 총 확률 합계가 반드시 1이 될 수는 없습니다. 동일한 가중치를 가진 클러스터에서만 확률을 계산할 수 있는 것 같습니다.
Argoverse1도 훨씬 앞서있습니다
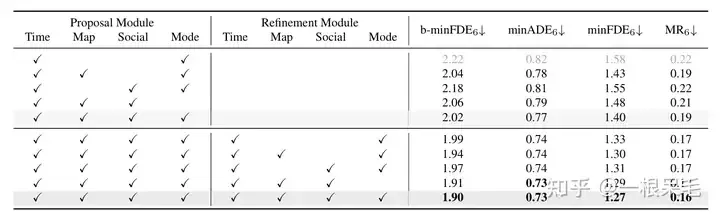
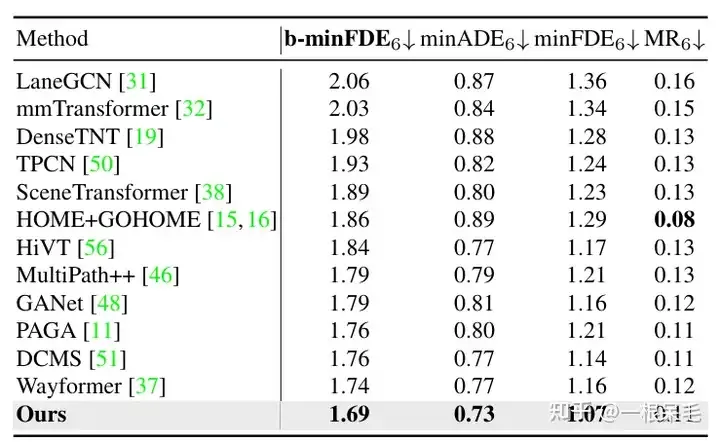 장면 인코딩 연구: 이전 장면 인코딩 결과를 재사용하면 추론 시간을 대폭 줄일 수 있습니다. 에이전트와 장면 정보 사이의 Factorized attention 상호 작용 횟수가 증가하고 예측 효과도 좋아지지만 지연 시간도 급격히 증가하므로 가중치를 둘 필요가 있습니다.
장면 인코딩 연구: 이전 장면 인코딩 결과를 재사용하면 추론 시간을 대폭 줄일 수 있습니다. 에이전트와 장면 정보 사이의 Factorized attention 상호 작용 횟수가 증가하고 예측 효과도 좋아지지만 지연 시간도 급격히 증가하므로 가중치를 둘 필요가 있습니다.
 다양한 작업에 대한 연구: 다양한 상호작용에서 정제의 중요성과 요인화된 주의의 중요성을 입증하는 것은 둘 다 필수 불가결합니다.
다양한 작업에 대한 연구: 다양한 상호작용에서 정제의 중요성과 요인화된 주의의 중요성을 입증하는 것은 둘 다 필수 불가결합니다.
위 내용은 궤도 예측 시리즈 | HiVT QCNet의 진화된 버전은 무엇에 대해 이야기합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 SQL IF 문을 사용하는 방법
Apr 09, 2025 pm 06:12 PM
SQL IF 문을 사용하는 방법
Apr 09, 2025 pm 06:12 PM
SQL IF 명령문은 구문을 다음과 같이 조건부로 실행하는 데 사용됩니다. if (조건) 그런 다음 {state} else {state} end if;. 조건은 유효한 SQL 표현식 일 수 있으며 조건이 참이면 당시 조항을 실행하십시오. 조건이 false 인 경우 else 절을 실행하십시오. 명세서를 중첩 할 수있는 경우 더 복잡한 조건부 점검이 가능합니다.
 도메인의 Vue Axios로 인한 '네트워크 오류'를 해결하는 방법
Apr 07, 2025 pm 10:27 PM
도메인의 Vue Axios로 인한 '네트워크 오류'를 해결하는 방법
Apr 07, 2025 pm 10:27 PM
Vue Axios의 크로스 도메인 문제를 해결하는 방법 : Cors 플러그인을 사용하여 Websocket을 사용하여 JSONP를 사용하여 Axios 프록시를 사용하여 서버 측의 CORS 헤더 구성
 Apache의 Zend를 구성하는 방법
Apr 13, 2025 pm 12:57 PM
Apache의 Zend를 구성하는 방법
Apr 13, 2025 pm 12:57 PM
Apache에서 Zend를 구성하는 방법은 무엇입니까? Apache 웹 서버에서 Zend 프레임 워크를 구성하는 단계는 다음과 같습니다. Zend 프레임 워크를 설치하고 웹 서버 디렉토리로 추출하십시오. .htaccess 파일을 만듭니다. Zend 응용 프로그램 디렉토리를 작성하고 Index.php 파일을 추가하십시오. Zend 응용 프로그램 (application.ini)을 구성하십시오. Apache 웹 서버를 다시 시작하십시오.
 C#에서 멀티 스레딩의 이점은 무엇입니까?
Apr 03, 2025 pm 02:51 PM
C#에서 멀티 스레딩의 이점은 무엇입니까?
Apr 03, 2025 pm 02:51 PM
멀티 스레딩의 장점은 특히 많은 양의 데이터를 처리하거나 시간이 많이 걸리는 작업을 수행하기 위해 성능 및 리소스 활용도를 향상시킬 수 있다는 것입니다. 이를 통해 여러 작업을 동시에 수행하여 효율성을 향상시킬 수 있습니다. 그러나 너무 많은 스레드가 성능 저하로 이어질 수 있으므로 CPU 코어 수와 작업 특성에 따라 스레드 수를 신중하게 선택해야합니다. 또한 다중 스레드 프로그래밍에는 교착 상태 및 레이스 조건과 같은 과제가 포함되며 동기화 메커니즘을 사용하여 해결해야하며 동시 프로그래밍에 대한 확실한 지식, 장단점을 측정하고주의해서 사용해야합니다.
 MySQL에 루트로 로그인 할 수 없습니다
Apr 08, 2025 pm 04:54 PM
MySQL에 루트로 로그인 할 수 없습니다
Apr 08, 2025 pm 04:54 PM
Root로 MySQL에 로그인 할 수없는 주된 이유는 권한 문제, 구성 파일 오류, 암호 일관성이 없음, 소켓 파일 문제 또는 방화벽 차단입니다. 솔루션에는 다음이 포함됩니다. 구성 파일의 BAND-ADDRESS 매개 변수가 올바르게 구성되어 있는지 확인하십시오. 루트 사용자 권한이 수정 또는 삭제되어 재설정되었는지 확인하십시오. 케이스 및 특수 문자를 포함하여 비밀번호가 정확한지 확인하십시오. 소켓 파일 권한 설정 및 경로를 확인하십시오. 방화벽이 MySQL 서버에 연결되는지 확인하십시오.
 데비안에서 nginx ssl 성능을 모니터링하는 방법
Apr 12, 2025 pm 10:18 PM
데비안에서 nginx ssl 성능을 모니터링하는 방법
Apr 12, 2025 pm 10:18 PM
이 기사에서는 데비안 시스템에서 NGINX 서버의 SSL 성능을 효과적으로 모니터링하는 방법에 대해 설명합니다. NginxOxporter를 사용하여 Nginx 상태 데이터를 프로 메테우스로 내보낸 다음 Grafana를 통해 시각적으로 표시합니다. 1 단계 : nginx 구성 먼저 Nginx 구성 파일에서 stub_status 모듈을 활성화하여 nginx의 상태 정보를 얻어야합니다. nginx 구성 파일에 다음 스 니펫을 추가하십시오 (일반적으로 /etc/nginx/nginx.conf에 있거나 포함 파일에 위치) : location/nginx_status {stub_status
 phpmyadmin 취약성 요약
Apr 10, 2025 pm 10:24 PM
phpmyadmin 취약성 요약
Apr 10, 2025 pm 10:24 PM
Phpmyadmin 보안 방어 전략의 핵심은 다음과 같습니다. 1. Phpmyadmin의 최신 버전을 사용하고 정기적으로 PHP 및 MySQL을 업데이트합니다. 2. 액세스 권한을 엄격하게 제어하고, .htaccess 또는 웹 서버 액세스 제어 사용; 3. 강력한 비밀번호와 2 단계 인증을 활성화합니다. 4. 데이터베이스를 정기적으로 백업하십시오. 5. 민감한 정보를 노출하지 않도록 구성 파일을주의 깊게 확인하십시오. 6. WAF (Web Application Firewall) 사용; 7. 보안 감사를 수행하십시오. 이러한 조치는 부적절한 구성, 이전 버전 또는 환경 보안 위험으로 인해 PhpmyAdmin으로 인한 보안 위험을 효과적으로 줄이고 데이터베이스의 보안을 보장 할 수 있습니다.
 데비안 아파치 로그에서 악의적 인 액세스를 식별하는 방법
Apr 13, 2025 am 07:30 AM
데비안 아파치 로그에서 악의적 인 액세스를 식별하는 방법
Apr 13, 2025 am 07:30 AM
악의적 인 웹 사이트 액세스에 대한 효과적인 모니터링 및 방어는 데비안 시스템의 Apache 서버에 중요합니다. Apache Access Logs는 이러한 위협을 식별하기위한 주요 정보 소스입니다. 이 기사에서는 로그를 분석하고 방어 조치를 취하는 방법을 안내합니다. 악의적 인 액세스 동작을 식별하는 Apache Access Log는 일반적으로 /var/log/apache2/access.log에 있습니다. 로그 파일 위치 확인 : 먼저 시스템 구성에 따라 약간 다를 수있는 Apache 액세스 로그의 정확한 위치를 확인하십시오. 명령 줄 도구 분석 : GREP 명령을 사용하여 GREP "404"와 같은 특정 패턴을 검색하십시오.
