

방법 1: 메뉴 버튼
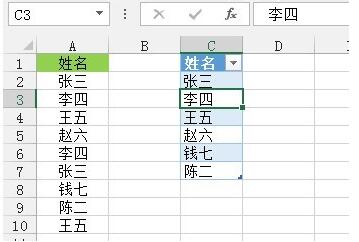
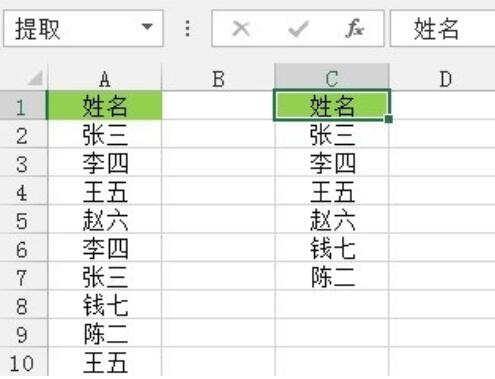
그림과 같이 이 작업의 소스 데이터입니다.
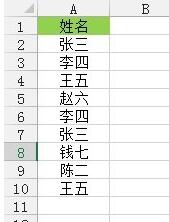
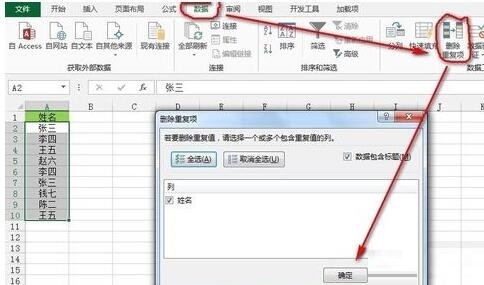
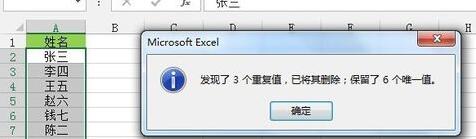
[데이터] 탭--"[데이터 도구] 리본--"[중복 항목 삭제]를 클릭하면 [중복 항목 삭제] 대화 상자가 나타나고 [확인]을 클릭하여 단일에서 중복 값을 삭제합니다. 데이터 열.
방법 2: 피벗 테이블 방법
계속 위의 데이터 소스를 사용하여 [삽입] 탭--"[테이블] 리본--"[피벗 테이블]을 클릭하면 그림과 같은 프롬프트가 나타납니다. 상자에서 기존 워크시트의 C1 셀을 선택하고(필요에 따라 새 워크시트를 선택할 수 있음) [확인]을 클릭하여 아래와 같이 피벗 테이블 생성을 완료합니다.
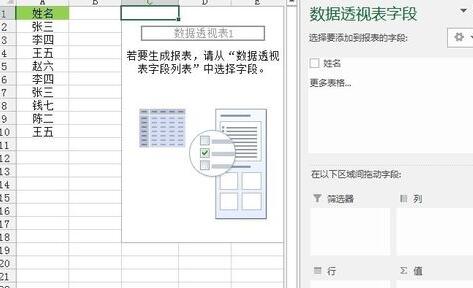
[ 앞의 확인란을 선택합니다. 이름] 상자를 선택하면 그림과 같이 "행" 필드의 프레임에 [이름] 필드가 나타납니다.
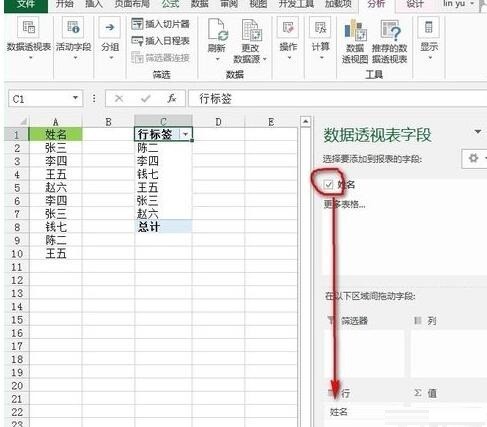
그런 다음 피벗 테이블의 데이터를 수정하고 [ 행 레이블]이 있고 셀의 텍스트를 [이름]으로 변경하고 피벗 테이블에서 아무 셀이나 클릭한 다음 [피벗 테이블 도구]-"디자인" 탭-"레이아웃" 리본-"전체"를 클릭합니다. 행과 열] 버튼이 완성되면 그림과 같이
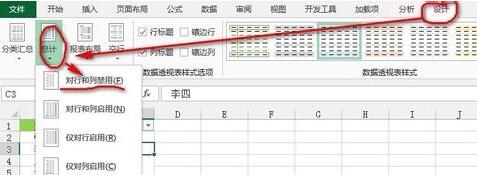
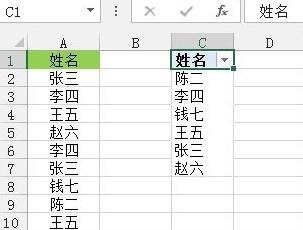
방법 3: 수식법
그림과 같이 셀 C1에 다음 수식을 입력하고 동시에 Ctrl+Shift+Enter를 누릅니다. 시간 입력이 완료되면 수식이 입력된 셀 오른쪽 하단의 채우기 핸들을 드래그하면 중복되지 않은 데이터 필터링이 완료됩니다.
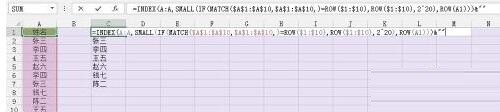
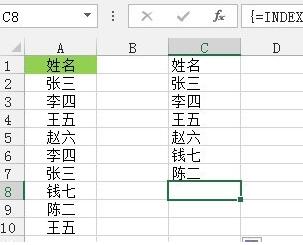
그럼 공식을 단계별로 설명하겠습니다. 먼저 MATCH($A$1:$A$10,$A$1:$A$10,)=ROW($1:$10)은 A1부터 A10까지의 셀을 찾는다는 의미입니다. in 참조 영역 $A$1:$A$10의 위치가 현재 셀 행 번호의 위치와 같은지 여부, 동일하면 해당 영역에서 데이터가 고유하다는 의미이며 이후 이 필드의 행이 반환됩니다. IF(MATCH()) 조합 함수 번호를 통해 그렇지 않으면 2^20=1048576을 반환하고 SMALL 함수를 사용하여 얻은 행 번호를 오름차순으로 정렬하고 마지막으로 INDEX 함수를 사용하여 해당 위치의 값을 찾습니다. 행 번호입니다. &[]는 주로 내결함성을 위한 것입니다. 모든 데이터를 가져오면 1048576의 위치만 남고 INDEX(A:A,1048576)=0이면 &[]를 추가합니다. 빈 텍스트를 반환합니다.
방법 4: SQL 방법
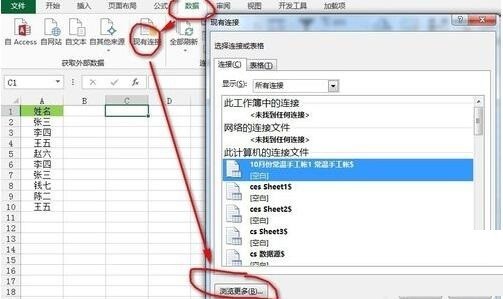
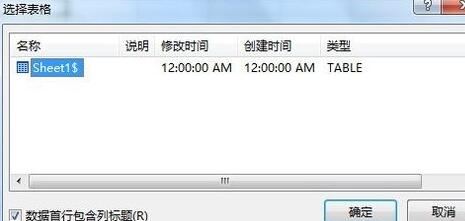
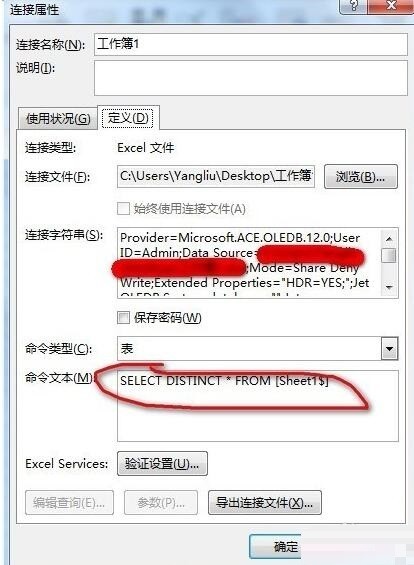
[데이터] 탭--""외부 데이터 가져오기" 리본--"기존 연결을 클릭하고 [기존 연결] 대화 상자를 열고 왼쪽 하단에서 [업데이트 찾아보기]를 클릭합니다. 다중]을 선택한 후, 자신이 운영하는 데이터소스가 있는 워크북의 경로를 찾아 [열기]를 클릭하면 [테이블 선택] 대화상자가 나타나며, 기본 상태를 유지한 후 [확인] 버튼을 클릭하면 그림과 같이 됩니다. 그림:
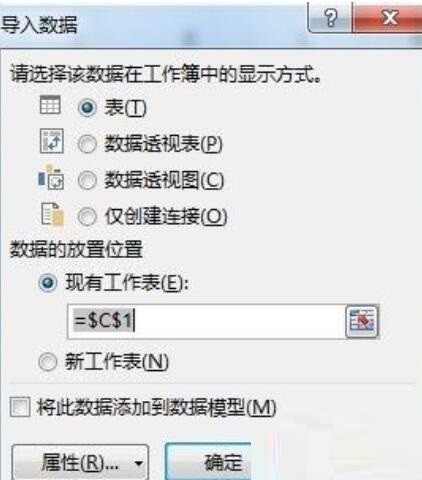
그런 다음 [테이블] 라디오 버튼을 선택합니다. 여기에서는 기존 워크시트의 C1 셀을 선택하고(필요에 따라 새 워크시트를 선택할 수 있음) [속성] 버튼을 클릭한 다음 "연결 속성" 대화 상자를 엽니다. 상자에서 [정의 "탭, 지우기] 명령 텍스트 [텍스트, 다음 명령문을 입력하십시오. SELECT DISTINCT * FROM [Sheet1$] (여기서 Sheet1은 내 소스 데이터의 이름이고 자신의 워크시트 이름을 입력하고 [ ] 및 $는 누락될 수 없습니다. 셀 영역에 다른 필드가 있거나 데이터가 행의 시작 부분에 없는 경우 [Sheet1$].A4:A12)와 같이 데이터 소스 영역도 입력해야 합니다. 그림과 같이:
방법 5: 고급 필터링 방법
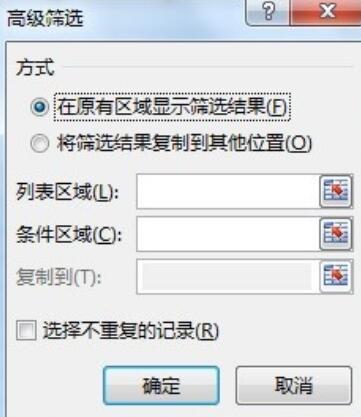
[데이터] 탭--"[정렬 및 필터] 리본--"[고급] 버튼을 클릭하여 [고급 필터링] 팝업을 엽니다. 그림과 같은 대화 상자:

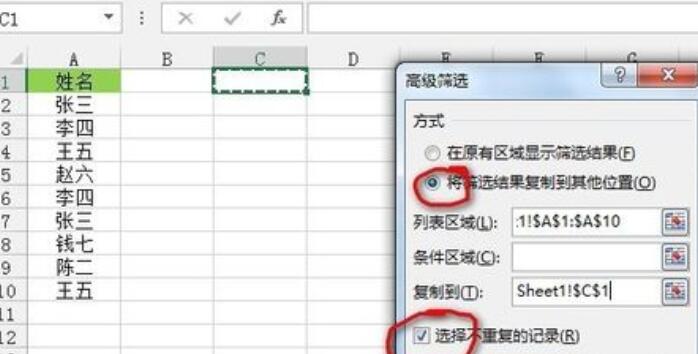
[필터 결과를 다른 위치로 복사]를 선택하고 [목록 영역]과 [복사 위치]를 선택한 후 [중복되지 않은 레코드 선택] 확인란을 선택하고 그림과 같이 [확인]을 클릭합니다. 중복 값이 완료되었습니다.
위 내용은 단일열 데이터에서 중복값을 제거하는 엑셀 연산 내용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



