

Llama3의 훈련 비용이 1/17에 불과한 Snowflake 오픈 소스 128x3B MoE 모델

Snowflake가 LLM 근접전에 합류했습니다.
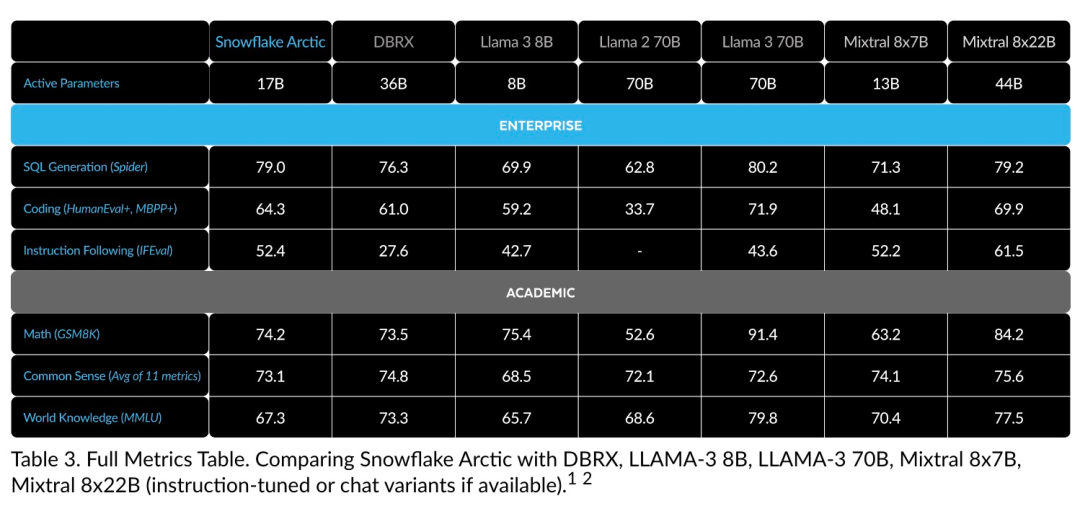
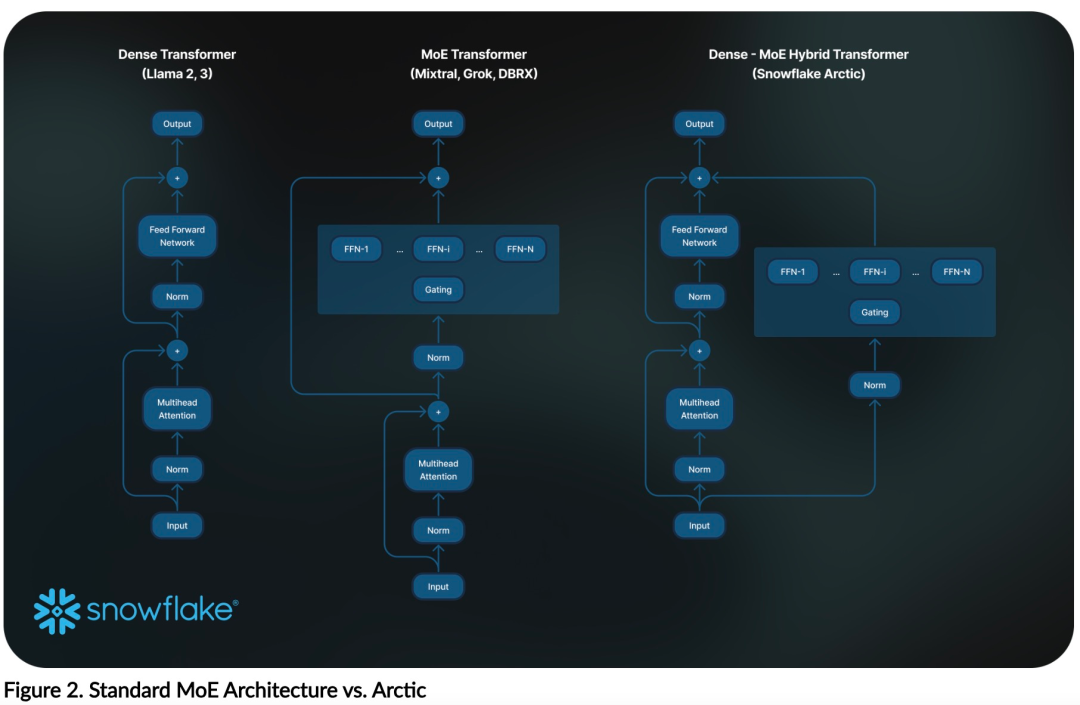
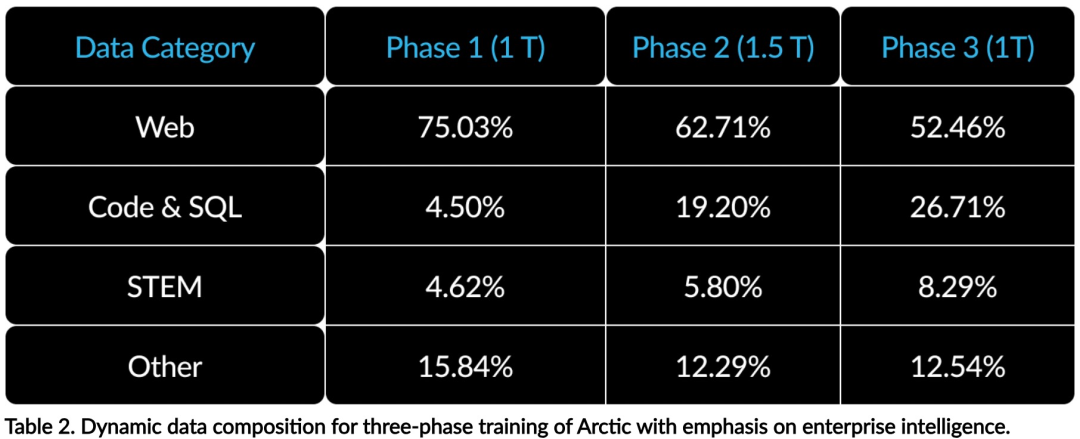
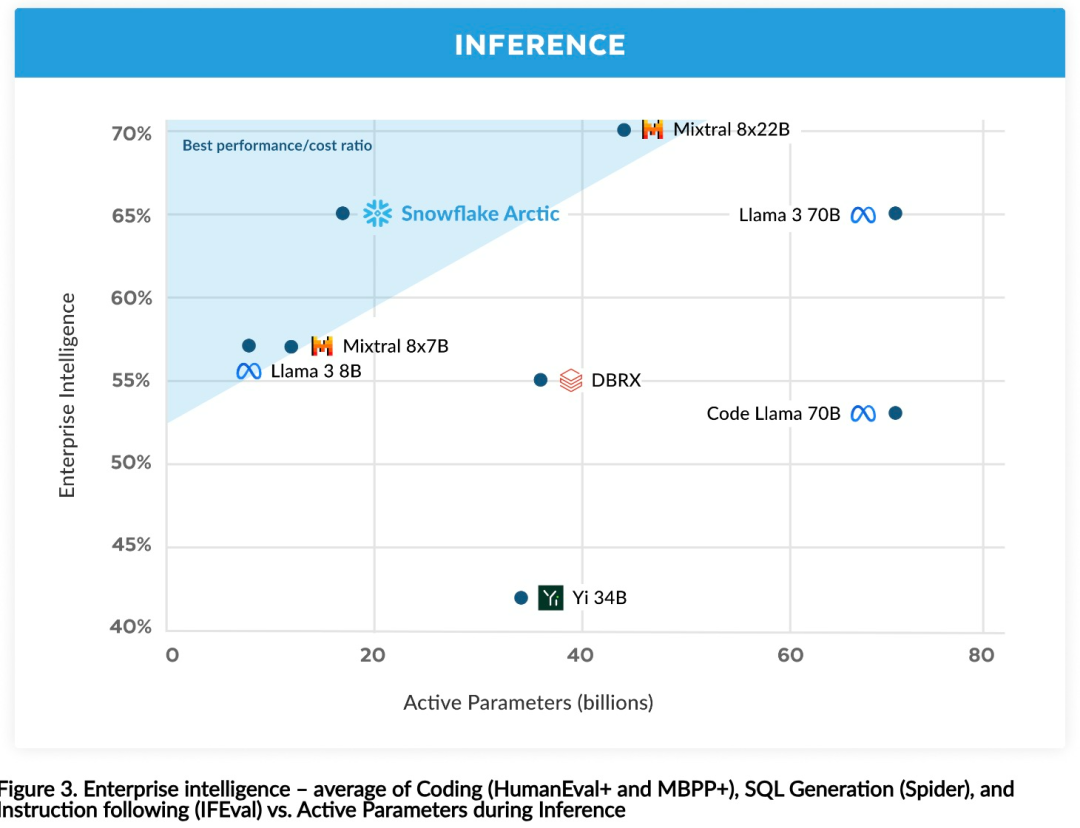
효율적인 인텔리전스: Arctic은 SQL 생성, 프로그래밍 및 지침 따르기와 같은 엔터프라이즈 작업에서 잘 수행됩니다. , 더 높은 계산 비용으로 훈련된 오픈 소스 모델과도 비교할 수 있습니다. Arctic은 비용 효율적인 교육을 위한 새로운 기준을 설정하여 Snowflake 고객이 기업 요구 사항에 맞는 고품질 맞춤형 모델을 저렴한 비용으로 만들 수 있도록 지원합니다. 오픈 소스: Arctic은 Apache 2.0 라이선스를 채택하여 무게와 코드에 대한 공개 액세스를 제공하며 Snowflake는 모든 데이터 솔루션과 연구 결과도 오픈 소스로 제공합니다.
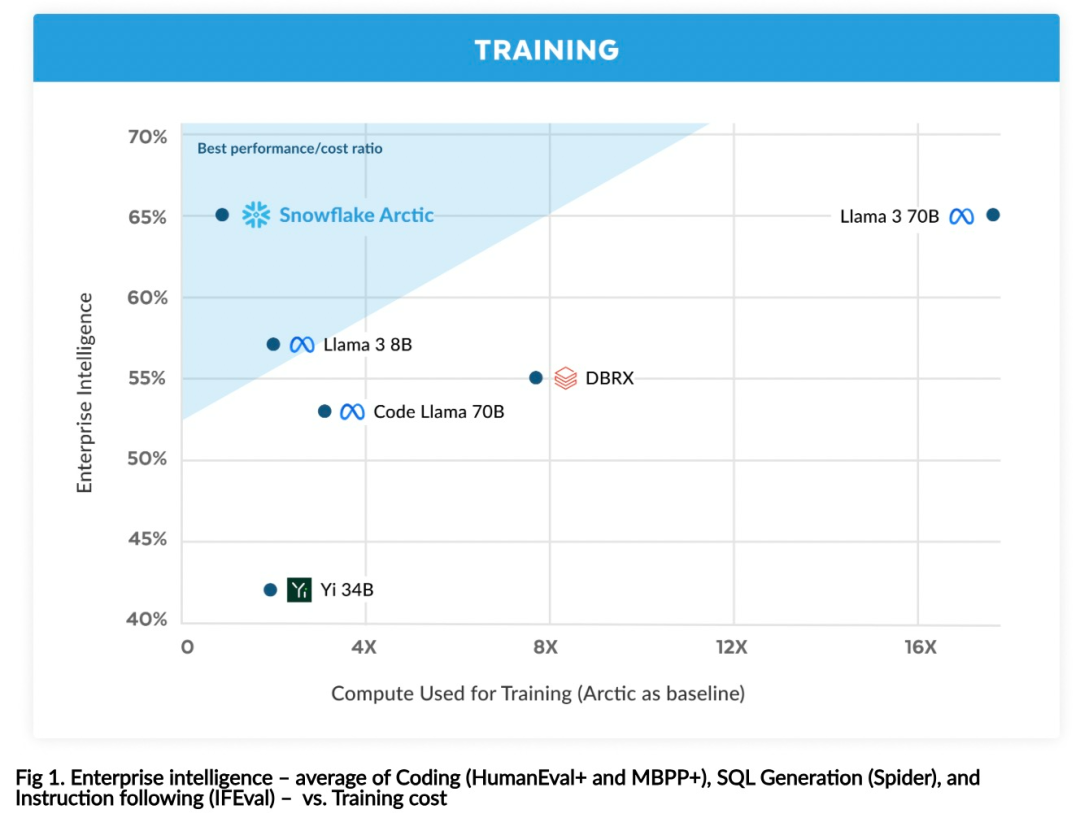
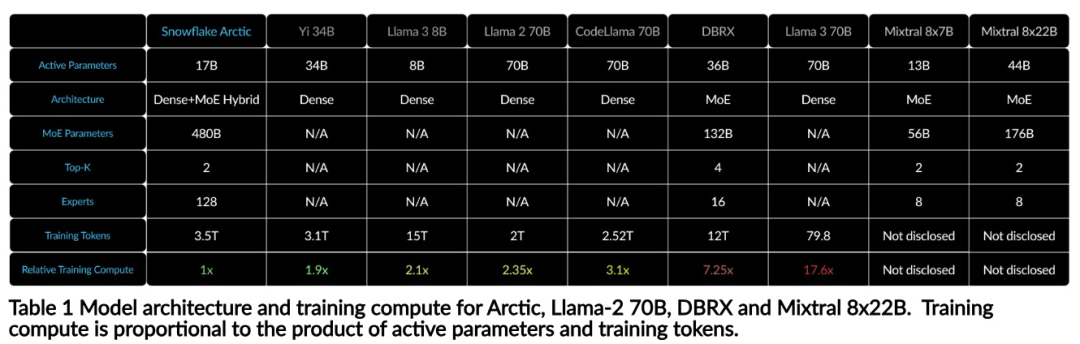
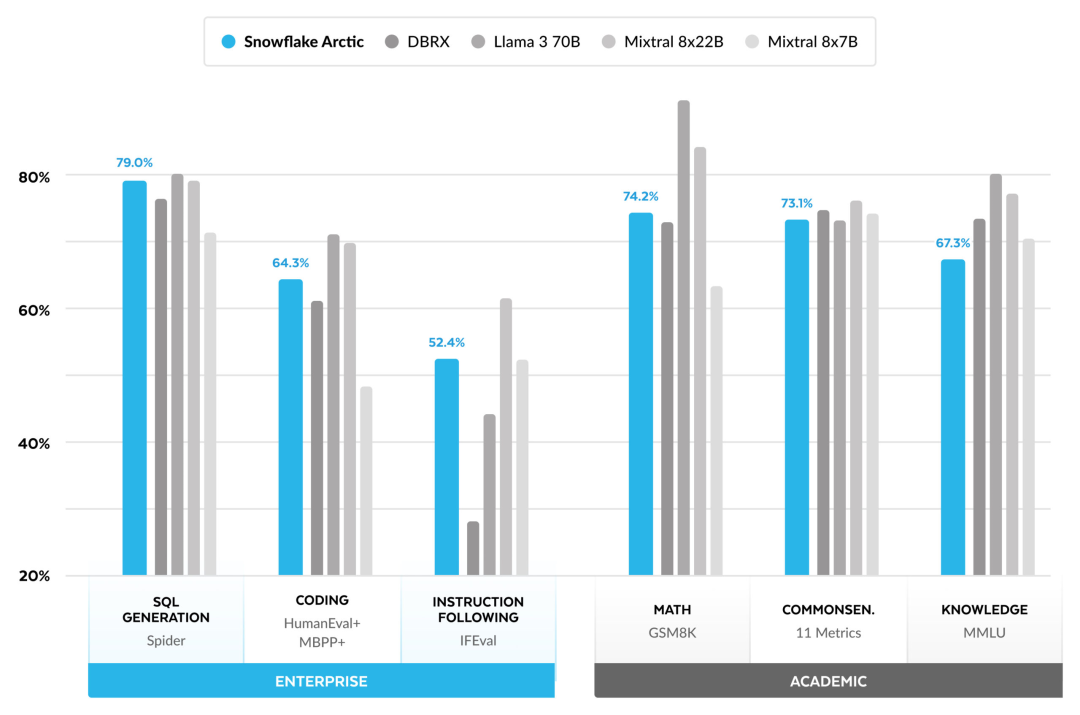
위 내용은 Llama3의 훈련 비용이 1/17에 불과한 Snowflake 오픈 소스 128x3B MoE 모델의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7814
7814
 15
1646
14
1402
52
1300
25
1238
29
15
1646
14
1402
52
1300
25
1238
29

 Apache에서 CGI 디렉토리를 설정하는 방법
Apr 13, 2025 pm 01:18 PM
Apache에서 CGI 디렉토리를 설정하는 방법
Apr 13, 2025 pm 01:18 PM
Apache에서 CGI 디렉토리를 설정하려면 다음 단계를 수행해야합니다. "CGI-BIN"과 같은 CGI 디렉토리를 작성하고 Apache 쓰기 권한을 부여하십시오. Apache 구성 파일에 "Scriptalias"지시록 블록을 추가하여 CGI 디렉토리를 "/cgi-bin"URL에 매핑하십시오. Apache를 다시 시작하십시오.
 Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache의 데이터베이스에 연결하는 방법
Apr 13, 2025 pm 01:03 PM
Apache는 데이터베이스에 연결하여 다음 단계가 필요합니다. 데이터베이스 드라이버 설치. 연결 풀을 만들려면 Web.xml 파일을 구성하십시오. JDBC 데이터 소스를 작성하고 연결 설정을 지정하십시오. JDBC API를 사용하여 Connections, 명세서 작성, 매개 변수 바인딩, 쿼리 또는 업데이트 실행 및 처리를 포함하여 Java 코드의 데이터베이스에 액세스하십시오.
 Apache80 포트가 점유 된 경우해야 할 일
Apr 13, 2025 pm 01:24 PM
Apache80 포트가 점유 된 경우해야 할 일
Apr 13, 2025 pm 01:24 PM
Apache 80 포트가 점유되면 솔루션은 다음과 같습니다. 포트를 차지하고 닫는 프로세스를 찾으십시오. 방화벽 설정을 확인하여 Apache가 차단되지 않았는지 확인하십시오. 위의 방법이 작동하지 않으면 Apache를 재구성하여 다른 포트를 사용하십시오. Apache 서비스를 다시 시작하십시오.
 Apache 버전을 보는 방법
Apr 13, 2025 pm 01:15 PM
Apache 버전을 보는 방법
Apr 13, 2025 pm 01:15 PM
APACHE 서버에서 버전을 보는 3 가지 방법이 있습니다. 명령 줄 (APACHECTL -V 또는 APACHE2CTL -V)을 통해 서버 상태 페이지 (http : // & lt; 서버 IP 또는 도메인 이름 & gt;/server -status)를 확인하거나 APACHE 구성 파일 (ServerVersion : Apache/& lt; 버전 번호 & gt;).
 CentOS HDFS 구성을 최적화하는 방법
Apr 14, 2025 pm 07:15 PM
CentOS HDFS 구성을 최적화하는 방법
Apr 14, 2025 pm 07:15 PM
CentOS에서 HDFS 성능 향상 : CentOS에서 HDFS (Hadoop 분산 파일 시스템)를 최적화하기위한 포괄적 인 최적화 안내서에는 하드웨어, 시스템 구성 및 네트워크 설정에 대한 포괄적 인 고려가 필요합니다. 이 기사는 HDFS 성능을 향상시키는 데 도움이되는 일련의 최적화 전략을 제공합니다. 1. 하드웨어 업그레이드 및 선택 리소스 확장 : 서버의 CPU, 메모리 및 저장 용량을 최대한 많이 늘립니다. 고성능 하드웨어 : 고성능 네트워크 카드 및 스위치를 채택하여 네트워크 처리량을 개선합니다. 2. 시스템 구성 미세 조정 커널 매개 변수 조정 : TCP 연결 번호, 파일 핸들 번호 및 메모리 관리와 같은 커널 매개 변수를 최적화하기 위해 /etc/sysctl.conf 파일을 수정합니다. 예를 들어 TCP 연결 상태 및 버퍼 크기를 조정하십시오
 Apache 버전을 보는 방법
Apr 13, 2025 pm 01:00 PM
Apache 버전을 보는 방법
Apr 13, 2025 pm 01:00 PM
Apache 버전을 보는 방법? Apache Server 시작 : Sudo Service Apache2를 사용하여 서버를 시작하십시오. 버전 번호보기 : 다음 방법 중 하나를 사용하여 버전을 봅니다. 명령 줄 : APACHE2 -V 명령을 실행하십시오. 서버 상태 페이지 : 웹 브라우저에서 Apache 서버의 기본 포트 (일반적으로 80)에 액세스하고 버전 정보가 페이지 하단에 표시됩니다.
 Apache의 서버 이름 이상을 삭제하는 방법
Apr 13, 2025 pm 01:09 PM
Apache의 서버 이름 이상을 삭제하는 방법
Apr 13, 2025 pm 01:09 PM
Apache에서 추가 ServerName 지시문을 삭제하려면 다음 단계를 수행 할 수 있습니다. 추가 ServerName Directive를 식별하고 삭제하십시오. Apache를 다시 시작하여 변경 사항이 적용됩니다. 구성 파일을 확인하여 변경 사항을 확인하십시오. 서버를 테스트하여 문제가 해결되었는지 확인하십시오.
 Apache를 시작할 수없는 문제를 해결하는 방법
Apr 13, 2025 pm 01:21 PM
Apache를 시작할 수없는 문제를 해결하는 방법
Apr 13, 2025 pm 01:21 PM
다음과 같은 이유로 Apache가 시작할 수 없습니다. 구성 파일 구문 오류. 다른 응용 프로그램 포트와 충돌합니다. 권한 문제. 기억이 없습니다. 프로세스 교착 상태. 데몬 실패. Selinux 권한 문제. 방화벽 문제. 소프트웨어 충돌.
