

학습 곡선을 통해 과적합과 과소적합 식별

이 글에서는 학습 곡선을 통해 머신러닝 모델에서 과적합과 과소적합을 효과적으로 식별하는 방법을 소개합니다.
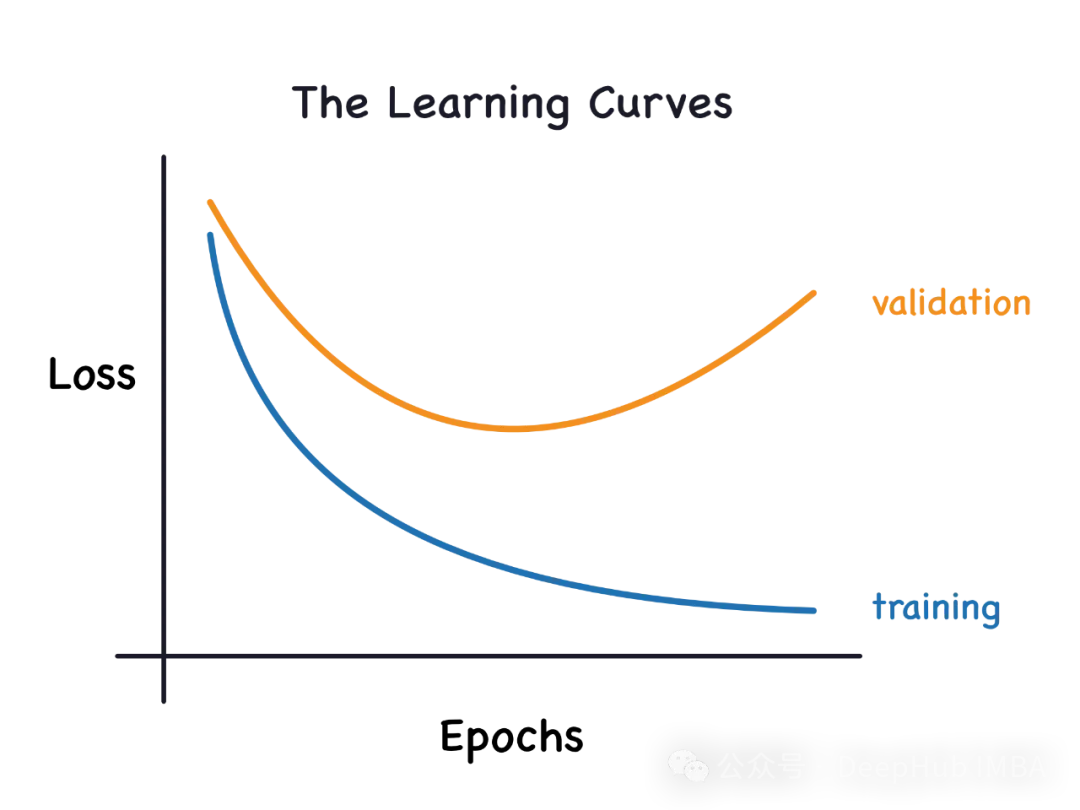
과소적합 및 과적합
1. 과적합
모델이 데이터에서 과도하게 학습되어 데이터로부터 노이즈를 학습하는 경우 이를 과적합이라고 합니다. 과적합된 모델은 모든 예를 너무 완벽하게 학습하므로 보이지 않거나 새로운 예를 잘못 분류합니다. 과대적합 모델의 경우 완벽/거의 완벽에 가까운 훈련 세트 점수와 형편없는 검증 세트/테스트 점수를 얻게 됩니다.
약간 수정됨: "과적합의 원인: 간단한 문제를 해결하기 위해 복잡한 모델을 사용하면 데이터에서 노이즈가 추출됩니다. 훈련 세트로 사용되는 작은 데이터 세트는 모든 데이터를 올바르게 표현하지 못할 수 있기 때문입니다." 2. 과소적합
모델이 데이터의 패턴을 올바르게 학습할 수 없는 경우 과소적합이라고 합니다. 과소적합 모델은 데이터 세트의 모든 예를 완전히 학습하지는 않습니다. 이 경우 훈련 세트와 검증 세트 모두의 오류가 낮다는 것을 알 수 있습니다. 이는 모델이 너무 단순하고 데이터에 맞는 매개변수가 충분하지 않기 때문일 수 있습니다. 과소적합 문제를 해결하기 위해 모델의 복잡성을 높이고, 레이어 또는 뉴런의 수를 늘리려고 노력할 수 있습니다. 그러나 모델 복잡성이 증가하면 과적합 위험도 증가한다는 점에 유의해야 합니다.
적합하지 않은 이유: 복잡한 문제를 해결하기 위해 간단한 모델을 사용합니다. 모델이 데이터의 모든 패턴을 학습할 수 없거나, 모델이 기본 데이터의 패턴을 잘못 학습합니다. 데이터 분석과 머신러닝에서는 모델 선택이 매우 중요합니다. 문제에 적합한 모델을 선택하면 예측의 정확성과 신뢰성이 향상될 수 있습니다. 복잡한 문제의 경우 데이터의 모든 패턴을 캡처하려면 더 복잡한 모델이 필요할 수 있습니다. 또한
Learning Curve
학습 곡선은 새로운 훈련 샘플을 점진적으로 추가하여 훈련 샘플 자체의 훈련 및 검증 손실을 표시합니다. 검증 점수(보이지 않는 데이터에 대한 점수)를 향상시키기 위해 추가 훈련 예제를 추가해야 하는지 결정하는 데 도움이 될 수 있습니다. 모델이 과적합된 경우 추가 학습 예제를 추가하면 보이지 않는 데이터에 대한 모델 성능이 향상될 수 있습니다. 마찬가지로, 모델이 과소적합한 경우 훈련 예제를 추가하는 것이 유용하지 않을 수 있습니다. 'learning_curve' 방법은 Scikit-Learn의 'model_selection' 모듈에서 가져올 수 있습니다.
from sklearn.model_selection import learning_curve
#The function below builds the model and returns cross validation scores, train score and learning curve data def learn_curve(X,y,c): ''' param X: Matrix of input featuresparam y: Vector of Target/Labelc: Inverse Regularization variable to control overfitting (high value causes overfitting, low value causes underfitting)''' '''We aren't splitting the data into train and test because we will use StratifiedKFoldCV.KFold CV is a preferred method compared to hold out CV, since the model is tested on all the examples.Hold out CV is preferred when the model takes too long to train and we have a huge test set that truly represents the universe''' le = LabelEncoder() # Label encoding the target sc = StandardScaler() # Scaling the input features y = le.fit_transform(y)#Label Encoding the target log_reg = LogisticRegression(max_iter=200,random_state=11,C=c) # LogisticRegression model # Pipeline with scaling and classification as steps, must use a pipelne since we are using KFoldCV lr = Pipeline(steps=(['scaler',sc],['classifier',log_reg])) cv = StratifiedKFold(n_splits=5,random_state=11,shuffle=True) # Creating a StratifiedKFold object with 5 folds cv_scores = cross_val_score(lr,X,y,scoring="accuracy",cv=cv) # Storing the CV scores (accuracy) of each fold lr.fit(X,y) # Fitting the model train_score = lr.score(X,y) # Scoring the model on train set #Building the learning curve train_size,train_scores,test_scores =learning_curve(estimator=lr,X=X,y=y,cv=cv,scoring="accuracy",random_state=11) train_scores = 1-np.mean(train_scores,axis=1)#converting the accuracy score to misclassification rate test_scores = 1-np.mean(test_scores,axis=1)#converting the accuracy score to misclassification rate lc =pd.DataFrame({"Training_size":train_size,"Training_loss":train_scores,"Validation_loss":test_scores}).melt(id_vars="Training_size") return {"cv_scores":cv_scores,"train_score":train_score,"learning_curve":lc}
1. 피팅 모델의 학습 곡선
'learn_curve' 함수를 사용하세요. 반정규화 변수/매개변수 'c'를 1로 설정하면 좋은 피팅 모델을 얻을 수 있습니다(즉, 정규화를 수행하지 않습니다).
lc = learn_curve(X,y,1) print(f'Cross Validation Accuracies:\n{"-"*25}\n{list(lc["cv_scores"])}\n\n\ Mean Cross Validation Accuracy:\n{"-"*25}\n{np.mean(lc["cv_scores"])}\n\n\ Standard Deviation of Deep HUB Cross Validation Accuracy:\n{"-"*25}\n{np.std(lc["cv_scores"])}\n\n\ Training Accuracy:\n{"-"*15}\n{lc["train_score"]}\n\n') sns.lineplot(data=lc["learning_curve"],x="Training_size",y="value",hue="variable") plt.title("Learning Curve of Good Fit Model") plt.ylabel("Misclassification Rate/Loss");
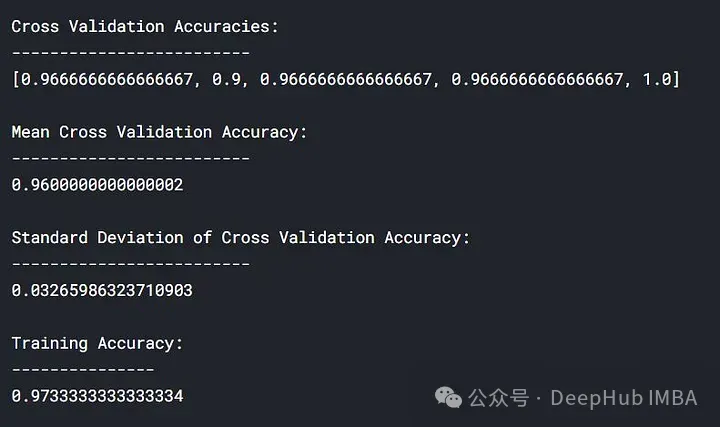 위 결과에서 교차 검증 정확도는 훈련 정확도에 가깝습니다.
위 결과에서 교차 검증 정확도는 훈련 정확도에 가깝습니다.
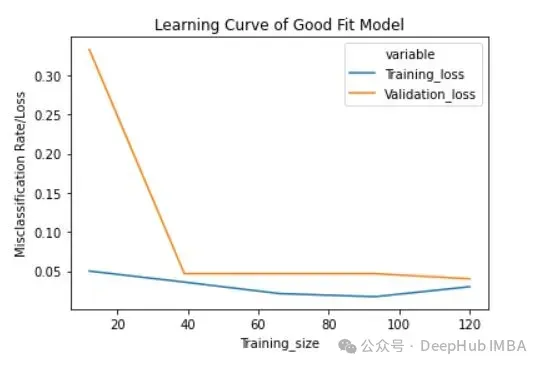 훈련 손실(파란색): 잘 맞는 모델의 학습 곡선은 훈련 사례 수가 증가함에 따라 점차적으로 감소하고 평탄해집니다. 이는 더 많은 훈련 사례를 추가해도 모델의 성능을 향상시킬 수 없음을 나타냅니다. 훈련 데이터.
훈련 손실(파란색): 잘 맞는 모델의 학습 곡선은 훈련 사례 수가 증가함에 따라 점차적으로 감소하고 평탄해집니다. 이는 더 많은 훈련 사례를 추가해도 모델의 성능을 향상시킬 수 없음을 나타냅니다. 훈련 데이터.
검증 손실(노란색): 잘 맞는 모델의 학습 곡선은 처음에는 검증 손실이 높으며 훈련 샘플 수가 증가함에 따라 점차적으로 감소하고 평탄해집니다. 이는 샘플이 많을수록 더 많은 패턴을 배울 수 있으며 이는 "보이지 않는" 데이터에 도움이 될 것입니다
마지막으로, 합리적인 수의 훈련 예제를 추가한 후에 훈련 손실과 검증 손실이 서로 가깝다는 것을 알 수 있습니다.
2. 과적합 모델의 학습 곡선
'learn_curve' 함수를 사용하여 과적합 모델의 높은 값을 얻습니다('c' 값은 과적합으로 이어짐).
lc = learn_curve(X,y,10000) print(f'Cross Validation Accuracies:\n{"-"*25}\n{list(lc["cv_scores"])}\n\n\ Mean Cross Validation Deep HUB Accuracy:\n{"-"*25}\n{np.mean(lc["cv_scores"])}\n\n\ Standard Deviation of Cross Validation Accuracy:\n{"-"*25}\n{np.std(lc["cv_scores"])} (High Variance)\n\n\ Training Accuracy:\n{"-"*15}\n{lc["train_score"]}\n\n') sns.lineplot(data=lc["learning_curve"],x="Training_size",y="value",hue="variable") plt.title("Learning Curve of an Overfit Model") plt.ylabel("Misclassification Rate/Loss");
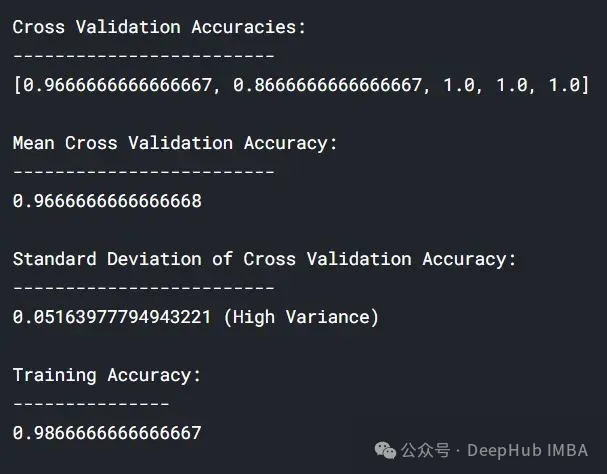
与拟合模型相比,交叉验证精度的标准差较高。
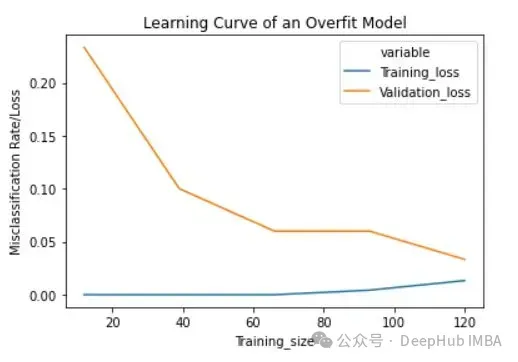
过拟合模型的学习曲线一开始的训练损失很低,随着训练样例的增加,学习曲线逐渐增加,但不会变平。过拟合模型的学习曲线在开始时具有较高的验证损失,随着训练样例的增加逐渐减小并且不趋于平坦,说明增加更多的训练样例可以提高模型在未知数据上的性能。同时还可以看到,训练损失和验证损失彼此相差很远,在增加额外的训练数据时,它们可能会彼此接近。
3、欠拟合模型的学习曲线
将反正则化变量/参数' c '设置为1/10000来获得欠拟合模型(' c '的低值导致欠拟合)。
lc = learn_curve(X,y,1/10000) print(f'Cross Validation Accuracies:\n{"-"*25}\n{list(lc["cv_scores"])}\n\n\ Mean Cross Validation Accuracy:\n{"-"*25}\n{np.mean(lc["cv_scores"])}\n\n\ Standard Deviation of Cross Validation Accuracy:\n{"-"*25}\n{np.std(lc["cv_scores"])} (Low variance)\n\n\ Training Deep HUB Accuracy:\n{"-"*15}\n{lc["train_score"]}\n\n') sns.lineplot(data=lc["learning_curve"],x="Training_size",y="value",hue="variable") plt.title("Learning Curve of an Underfit Model") plt.ylabel("Misclassification Rate/Loss");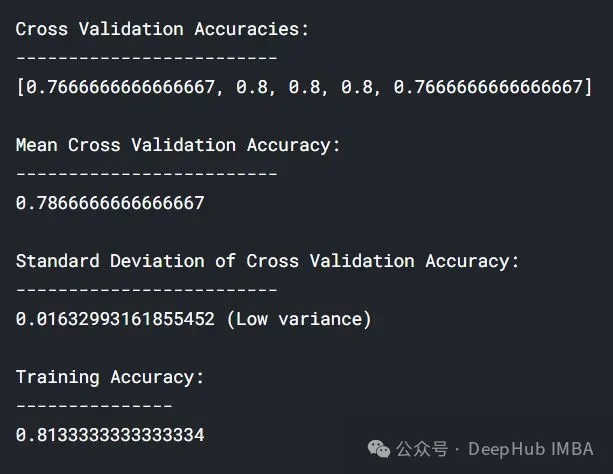
与过拟合和良好拟合模型相比,交叉验证精度的标准差较低。
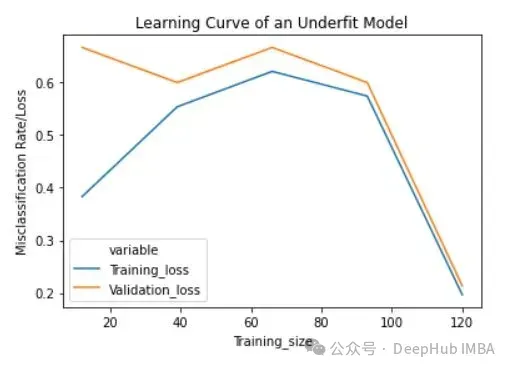
欠拟合模型的学习曲线在开始时具有较低的训练损失,随着训练样例的增加逐渐增加,并在最后突然下降到任意最小点(最小并不意味着零损失)。这种最后的突然下跌可能并不总是会发生。这表明增加更多的训练样例并不能提高模型在未知数据上的性能。
总结
在机器学习和统计建模中,过拟合(Overfitting)和欠拟合(Underfitting)是两种常见的问题,它们描述了模型与训练数据的拟合程度如何影响模型在新数据上的表现。
分析生成的学习曲线时,可以关注以下几个方面:
- 欠拟合:如果学习曲线显示训练集和验证集的性能都比较低,或者两者都随着训练样本数量的增加而缓慢提升,这通常表明模型欠拟合。这种情况下,模型可能太简单,无法捕捉数据中的基本模式。
- 过拟合:如果训练集的性能随着样本数量的增加而提高,而验证集的性能在一定点后开始下降或停滞不前,这通常表示模型过拟合。在这种情况下,模型可能太复杂,过度适应了训练数据中的噪声而非潜在的数据模式。
根据学习曲线的分析,你可以采取以下策略进行调整:
- 对于欠拟合:
- 增加模型复杂度,例如使用更多的特征、更深的网络或更多的参数。
- 改善特征工程,尝试不同的特征组合或转换。
- 增加迭代次数或调整学习率。
- 对于过拟合:
使用正则化技术(如L1、L2正则化)。
减少模型的复杂性,比如减少参数数量、层数或特征数量。
增加更多的训练数据。
应用数据增强技术。
使用早停(early stopping)等技术来避免过度训练。
通过这样的分析和调整,学习曲线能够帮助你更有效地优化模型,并提高其在未知数据上的泛化能力。
위 내용은 학습 곡선을 통해 과적합과 과소적합 식별의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7487
7487
 15
1377
52
77
11
51
19
19
39
15
1377
52
77
11
51
19
19
39

 Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
Bytedance Cutting, SVIP 슈퍼 멤버십 출시: 연간 연속 구독료 499위안, 다양한 AI 기능 제공
Jun 28, 2024 am 03:51 AM
이 사이트는 6월 27일에 Jianying이 ByteDance의 자회사인 FaceMeng Technology에서 개발한 비디오 편집 소프트웨어라고 보도했습니다. 이 소프트웨어는 Douyin 플랫폼을 기반으로 하며 기본적으로 플랫폼 사용자를 위한 짧은 비디오 콘텐츠를 제작합니다. Windows, MacOS 및 기타 운영 체제. Jianying은 멤버십 시스템 업그레이드를 공식 발표하고 지능형 번역, 지능형 하이라이트, 지능형 패키징, 디지털 인간 합성 등 다양한 AI 블랙 기술을 포함하는 새로운 SVIP를 출시했습니다. 가격면에서 SVIP 클리핑 월 요금은 79위안, 연간 요금은 599위안(본 사이트 참고: 월 49.9위안에 해당), 월간 연속 구독료는 월 59위안, 연간 연속 구독료는 59위안입니다. 연간 499위안(월 41.6위안)입니다. 또한, 컷 관계자는 "사용자 경험 향상을 위해 기존 VIP에 가입하신 분들도
 Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
Rag 및 Sem-Rag를 사용한 상황 증강 AI 코딩 도우미
Jun 10, 2024 am 11:08 AM
검색 강화 생성 및 의미론적 메모리를 AI 코딩 도우미에 통합하여 개발자 생산성, 효율성 및 정확성을 향상시킵니다. EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG에서 번역됨, 저자 JanakiramMSV. 기본 AI 프로그래밍 도우미는 자연스럽게 도움이 되지만, 소프트웨어 언어에 대한 일반적인 이해와 소프트웨어 작성의 가장 일반적인 패턴에 의존하기 때문에 가장 관련성이 높고 정확한 코드 제안을 제공하지 못하는 경우가 많습니다. 이러한 코딩 도우미가 생성한 코드는 자신이 해결해야 할 문제를 해결하는 데 적합하지만 개별 팀의 코딩 표준, 규칙 및 스타일을 따르지 않는 경우가 많습니다. 이로 인해 코드가 애플리케이션에 승인되기 위해 수정되거나 개선되어야 하는 제안이 나타나는 경우가 많습니다.
 미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
미세 조정을 통해 LLM이 실제로 새로운 것을 배울 수 있습니까? 새로운 지식을 도입하면 모델이 더 많은 환각을 생성할 수 있습니다.
Jun 11, 2024 pm 03:57 PM
LLM(대형 언어 모델)은 대규모 텍스트 데이터베이스에서 훈련되어 대량의 실제 지식을 습득합니다. 이 지식은 매개변수에 내장되어 필요할 때 사용할 수 있습니다. 이러한 모델에 대한 지식은 훈련이 끝나면 "구체화"됩니다. 사전 훈련이 끝나면 모델은 실제로 학습을 중단합니다. 모델을 정렬하거나 미세 조정하여 이 지식을 활용하고 사용자 질문에 보다 자연스럽게 응답하는 방법을 알아보세요. 그러나 때로는 모델 지식만으로는 충분하지 않을 때도 있으며, 모델이 RAG를 통해 외부 콘텐츠에 접근할 수 있더라도 미세 조정을 통해 모델을 새로운 도메인에 적응시키는 것이 유익한 것으로 간주됩니다. 이러한 미세 조정은 인간 주석 작성자 또는 기타 LLM 생성자의 입력을 사용하여 수행됩니다. 여기서 모델은 추가적인 실제 지식을 접하고 이를 통합합니다.
 7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
7가지 멋진 GenAI 및 LLM 기술 인터뷰 질문
Jun 07, 2024 am 10:06 AM
AIGC에 대해 자세히 알아보려면 다음을 방문하세요. 51CTOAI.x 커뮤니티 https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou는 인터넷 어디에서나 볼 수 있는 전통적인 문제 은행과 다릅니다. 고정관념에서 벗어나 생각해야 합니다. LLM(대형 언어 모델)은 데이터 과학, 생성 인공 지능(GenAI) 및 인공 지능 분야에서 점점 더 중요해지고 있습니다. 이러한 복잡한 알고리즘은 인간의 기술을 향상시키고 많은 산업 분야에서 효율성과 혁신을 촉진하여 기업이 경쟁력을 유지하는 데 핵심이 됩니다. LLM은 자연어 처리, 텍스트 생성, 음성 인식 및 추천 시스템과 같은 분야에서 광범위하게 사용될 수 있습니다. LLM은 대량의 데이터로부터 학습하여 텍스트를 생성할 수 있습니다.
 대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
대형 모델에 대한 새로운 과학적이고 복잡한 질문 답변 벤치마크 및 평가 시스템을 제공하기 위해 UNSW, Argonne, University of Chicago 및 기타 기관이 공동으로 SciQAG 프레임워크를 출시했습니다.
Jul 25, 2024 am 06:42 AM
편집자 |ScienceAI 질문 응답(QA) 데이터 세트는 자연어 처리(NLP) 연구를 촉진하는 데 중요한 역할을 합니다. 고품질 QA 데이터 세트는 모델을 미세 조정하는 데 사용될 수 있을 뿐만 아니라 LLM(대형 언어 모델)의 기능, 특히 과학적 지식을 이해하고 추론하는 능력을 효과적으로 평가하는 데에도 사용할 수 있습니다. 현재 의학, 화학, 생물학 및 기타 분야를 포괄하는 과학적인 QA 데이터 세트가 많이 있지만 이러한 데이터 세트에는 여전히 몇 가지 단점이 있습니다. 첫째, 데이터 형식이 비교적 단순하고 대부분이 객관식 질문이므로 평가하기 쉽지만 모델의 답변 선택 범위가 제한되고 모델의 과학적 질문 답변 능력을 완전히 테스트할 수 없습니다. 이에 비해 개방형 Q&A는
 당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
당신이 모르는 머신러닝의 5가지 학교
Jun 05, 2024 pm 08:51 PM
머신 러닝은 명시적으로 프로그래밍하지 않고도 컴퓨터가 데이터로부터 학습하고 능력을 향상시킬 수 있는 능력을 제공하는 인공 지능의 중요한 분야입니다. 머신러닝은 이미지 인식, 자연어 처리, 추천 시스템, 사기 탐지 등 다양한 분야에서 폭넓게 활용되며 우리의 삶의 방식을 변화시키고 있습니다. 기계 학습 분야에는 다양한 방법과 이론이 있으며, 그 중 가장 영향력 있는 5가지 방법을 "기계 학습의 5개 학교"라고 합니다. 5개 주요 학파는 상징학파, 연결주의 학파, 진화학파, 베이지안 학파, 유추학파이다. 1. 상징주의라고도 알려진 상징주의는 논리적 추론과 지식 표현을 위해 상징을 사용하는 것을 강조합니다. 이 사고 학교는 학습이 기존을 통한 역연역 과정이라고 믿습니다.
 SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
SOTA 성능, 샤먼 다중 모드 단백질-리간드 친화성 예측 AI 방법, 최초로 분자 표면 정보 결합
Jul 17, 2024 pm 06:37 PM
Editor | KX 약물 연구 및 개발 분야에서 단백질과 리간드의 결합 친화도를 정확하고 효과적으로 예측하는 것은 약물 스크리닝 및 최적화에 매우 중요합니다. 그러나 현재 연구에서는 단백질-리간드 상호작용에서 분자 표면 정보의 중요한 역할을 고려하지 않습니다. 이를 기반으로 Xiamen University의 연구자들은 처음으로 단백질 표면, 3D 구조 및 서열에 대한 정보를 결합하고 교차 주의 메커니즘을 사용하여 다양한 양식 특징을 비교하는 새로운 다중 모드 특징 추출(MFE) 프레임워크를 제안했습니다. 조정. 실험 결과는 이 방법이 단백질-리간드 결합 친화도를 예측하는 데 있어 최첨단 성능을 달성한다는 것을 보여줍니다. 또한 절제 연구는 이 프레임워크 내에서 단백질 표면 정보와 다중 모드 기능 정렬의 효율성과 필요성을 보여줍니다. 관련 연구는 "S"로 시작된다
 AI와 같은 시장을 개척하는 GlobalFoundries는 Tagore Technology의 질화 갈륨 기술 및 관련 팀을 인수합니다.
Jul 15, 2024 pm 12:21 PM
AI와 같은 시장을 개척하는 GlobalFoundries는 Tagore Technology의 질화 갈륨 기술 및 관련 팀을 인수합니다.
Jul 15, 2024 pm 12:21 PM
7월 5일 이 웹사이트의 소식에 따르면 글로벌파운드리는 올해 7월 1일 보도자료를 통해 타고르 테크놀로지(Tagore Technology)의 전력질화갈륨(GaN) 기술 및 지적재산권 포트폴리오 인수를 발표하고 자동차와 인터넷 시장 점유율 확대를 희망하고 있다고 밝혔다. 더 높은 효율성과 더 나은 성능을 탐구하기 위한 사물 및 인공 지능 데이터 센터 응용 분야입니다. 생성 AI와 같은 기술이 디지털 세계에서 계속 발전함에 따라 질화갈륨(GaN)은 특히 데이터 센터에서 지속 가능하고 효율적인 전력 관리를 위한 핵심 솔루션이 되었습니다. 이 웹사이트는 이번 인수 기간 동안 Tagore Technology의 엔지니어링 팀이 GLOBALFOUNDRIES에 합류하여 질화갈륨 기술을 더욱 개발할 것이라는 공식 발표를 인용했습니다. G
