

르쿤이 달에 가나요? Nankai와 Byte 오픈 소스 StoryDiffusion을 통해 다중 그림 만화와 긴 비디오를 더욱 일관되게 만듭니다.

이틀 전 튜링상 수상자 Yann LeCun이 장편 만화 "달에 가서 스스로 탐험해 보세요"를 다시 게시하여 네티즌들 사이에서 열띤 토론을 불러일으켰습니다.

연구팀은 "Story Diffusion: Concious Self-Attention for long-range image and video Generation"이라는 논문에서 일관된 이미지와 영상을 생성하기 위해 Story Diffusion이라는 새로운 방법을 제안했습니다. 복잡한 상황을 설명합니다. 이 만화에 대한 연구는 Nankai University 및 ByteDance와 같은 기관에서 이루어졌습니다.

- 논문 주소: https://arxiv.org/pdf/2405.01434v1
- 프로젝트 홈페이지: https://storydiffusion.github.io/
관련 프로젝트가 이미 진행 중입니다. GitHub는 1,000 스타 금액을 획득했습니다.
GitHub 주소: https://github.com/HVision-NKU/StoryDiffusion
프로젝트 시연에 따르면 StoryDiffusion은 캐릭터 일관성을 유지하면서 일관된 스토리를 전달하면서 다양한 스타일의 만화를 생성할 수 있습니다. 스타일과 의복.

StoryDiffusion은 여러 캐릭터의 정체성을 동시에 유지하고 일련의 이미지에서 일관된 캐릭터를 생성할 수 있습니다.

또한 StoryDiffusion은 생성된 일관된 이미지 또는 사용자가 입력한 이미지를 바탕으로 고품질 비디오를 생성할 수 있습니다.


우리는 생성된 일련의 이미지, 특히 복잡한 주제와 세부 사항이 포함된 이미지에서 콘텐츠 일관성을 유지하는 것이 확산 기반 생성 모델에 있어서 중요한 과제라는 것을 알고 있습니다.
따라서 연구팀은 이미지 생성 시 배치 내에서 이미지 간의 연결을 설정하여 훈련 없이도 주제별로 일관된 이미지를 생성하는 Concious Self-Attention이라는 새로운 self-attention 계산 방법을 제안했습니다.
이 방법을 긴 비디오 생성으로 확장하기 위해 연구팀은 이미지를 의미 공간으로 인코딩하고 의미 공간에서의 움직임을 예측하여 비디오를 생성하는 의미 모션 예측기(Semantic Motion Predictor)를 도입했습니다. 이는 잠재 공간에만 기반한 모션 예측보다 더 안정적입니다.
그런 다음 프레임워크 통합을 수행하여 일관된 self-attention과 의미론적 모션 예측기를 결합하여 일관된 비디오를 생성하고 복잡한 스토리를 전달합니다. StoryDiffusion은 기존 방식보다 더 부드럽고 일관성 있는 영상을 생성할 수 있습니다.

그림 1: 팀의 StroyDiffusion으로 생성된 이미지 및 비디오
방법 개요
연구팀의 방법은 그림 2와 3과 같이 두 단계로 나눌 수 있습니다.
첫 번째 단계에서 StoryDiffusion은 일관된 Self-Attention을 사용하여 훈련 없이 주제와 일치하는 이미지를 생성합니다. 이러한 일관된 이미지는 스토리텔링에 직접 사용될 수도 있고 두 번째 단계의 입력으로 사용될 수도 있습니다. 두 번째 단계에서 StoryDiffusion은 이러한 일관된 이미지를 기반으로 일관된 전환 비디오를 만듭니다.
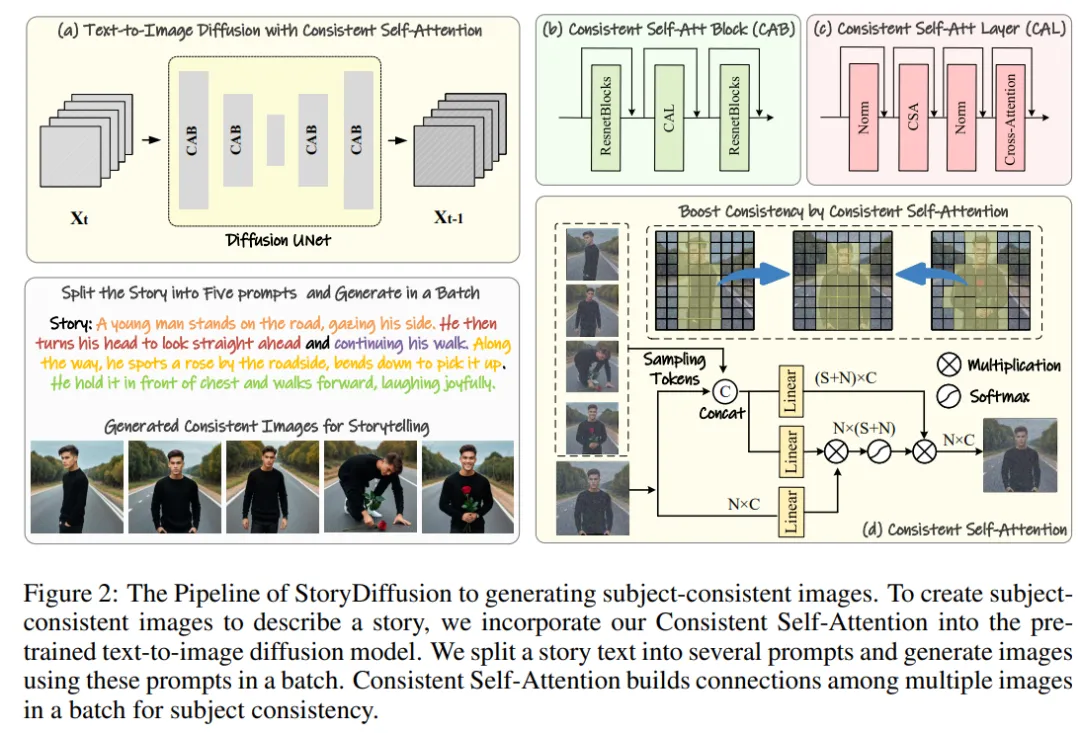
그림 2: 테마와 일치하는 이미지 생성을 위한 StoryDiffusion 프로세스 개요
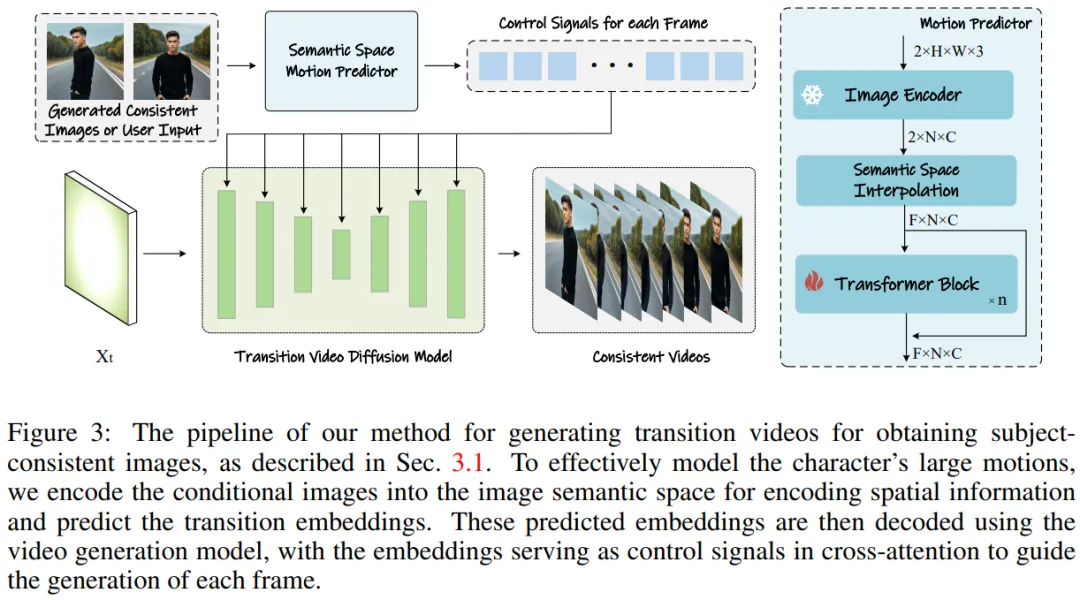 그림 3: 테마와 일치하는 이미지를 얻기 위해 전환 비디오를 생성하는 방법.
그림 3: 테마와 일치하는 이미지를 얻기 위해 전환 비디오를 생성하는 방법.
훈련 없이도 일관된 이미지 생성
연구팀은 "훈련 없이도 테마로 일관된 이미지를 생성하는 방법"이라는 방법을 소개했다. 위 문제를 해결하는 열쇠는 일련의 이미지에서 문자의 일관성을 유지하는 방법입니다. 이는 생성 프로세스 중에 이미지 배치 간에 연결을 설정해야 함을 의미합니다.
확산 모델에서 다양한 Attention 메커니즘의 역할을 재검토한 후, 그들은 이미지 배치 내에서 이미지의 일관성을 유지하기 위해 self-attention을 사용하는 방법을 탐구하고 일관된 Self-Attention -Attention을 제안했습니다. ).
연구팀은 기존 이미지 생성 모델의 U-Net 아키텍처에서 원래 self-attention 위치에 일관된 self-attention을 삽입하고, 원래 self-attention 가중치를 재사용하여 no training 및 플러그 앤 플레이를 유지합니다. 사용된 기능입니다.
쌍을 이루는 토큰이 주어지면 연구팀의 방법은 일련의 이미지에 대해 self-attention을 수행하여 다양한 이미지 기능 간의 상호 작용을 촉진합니다. 이러한 유형의 상호 작용은 생성 중에 캐릭터, 얼굴 및 의복에 대한 모델 수렴을 유도합니다. 일관된 셀프 어텐션 방법은 간단하고 훈련이 필요하지 않지만 주제별로 일관된 이미지를 효과적으로 생성할 수 있습니다.
좀 더 명확하게 설명하기 위해 연구팀은 알고리즘 1의 의사코드를 보여줍니다.

영상 생성을 위한 시맨틱 모션 예측기
연구팀은 이미지를 이미지 의미 공간으로 인코딩하여 공간 정보를 포착함으로써 보다 정확한 모션을 가능하게 하는 시맨틱 모션 예측기(Semantic Motion Predictor)를 제안했습니다. 주어진 시작 프레임과 끝 프레임으로부터 예측합니다.
보다 구체적으로 팀이 제안한 의미론적 모션 예측기에서는 먼저 함수 E를 사용하여 RGB 이미지에서 이미지 의미 공간 벡터로의 매핑을 설정하여 공간 정보를 인코딩합니다.
팀에서는 선형 레이어를 함수 E로 직접 사용하지 않았습니다. 대신 사전 학습된 CLIP 이미지 인코더를 함수 E로 사용하여 제로샷 기능을 활용하여 성능을 향상했습니다.
함수 E를 사용하여 주어진 시작 프레임 F_s와 끝 프레임 F_e는 이미지 의미 공간 벡터 K_s 및 K_e로 압축됩니다.

실험 결과
주제에 맞는 이미지 생성 측면에서 팀의 방법은 교육이 필요 없고 플러그 앤 플레이 방식이므로 Stable Diffusion XL과 Stable Diffusion 1.5의 두 가지 버전을 사용했습니다. All 이 방법을 구현했습니다. 비교된 모델과의 일관성을 유지하기 위해 비교를 위해 Stable-XL 모델에 동일한 사전 훈련된 가중치를 사용했습니다.
일관적인 비디오를 생성하기 위해 연구원들은 Stable Diffusion 1.5 특화된 모델을 기반으로 연구 방법을 구현하고 사전 훈련된 시간 모듈을 통합하여 비디오 생성을 지원했습니다. 비교된 모든 모델은 7.5 분류자 없는 안내 점수와 50단계 DDIM 샘플링을 사용합니다.
일관적인 이미지 생성 비교
팀은 주제별로 일관된 이미지를 생성하는 접근 방식을 두 가지 최첨단 ID 보존 방법인 IP-Adapter 및 Photo Maker와 비교하여 평가했습니다.
성능을 테스트하기 위해 GPT-4를 사용하여 특정 활동을 설명하는 20개의 역할 지침과 100개의 활동 지침을 생성했습니다.
정성적 결과는 그림 4에 나와 있습니다. "StoryDiffusion은 매우 일관된 이미지를 생성할 수 있지만 IP-Adapter 및 PhotoMaker와 같은 다른 방법은 일관되지 않은 의상 또는 감소된 텍스트 제어 가능성이 있는 이미지를 생성할 수 있습니다." 그림 4: 현재 방법과 일관된 이미지 생성 비교 연구원들은 정량적 비교 결과를 표 1에 표시합니다. 결과는 다음과 같습니다. "팀의 StoryDiffusion은 두 가지 정량적 지표 모두에서 최고의 성능을 달성했으며, 이는 해당 방법이 캐릭터 특성을 유지하면서 프롬프트 설명에 잘 부합하고 견고함을 보여줍니다. 전환 동영상 생성 비교 전환 동영상 생성 측면에서 연구팀은 두 가지 최신 방법인 SparseCtrl과 SEINE을 비교하여 성능을 평가했습니다. 전환 비디오 생성에 대한 질적 비교를 수행했으며 그 결과를 그림 5에 표시했습니다. 결과는 다음과 같습니다. "팀의 StoryDiffusion은 SEINE 및 SparseCtrl보다 훨씬 우수하며 생성된 전환 비디오는 부드럽고 물리적 원리와 일치합니다." 그림 5: 현재 다양한 상태를 사용하는 전환 -art 방법 비디오 생성 비교 또한 이 방법을 SEINE 및 SparseCtrl과 비교했으며 표 2와 같이 LPIPSfirst, LPIPS-frames, CLIPSIM-first 및 CLIPSIM-frames를 포함한 4가지 정량적 지표를 사용했습니다. 자세한 기술 및 실험 세부 사항은 원본 논문을 참조하세요. 
 표 1: 의 정량적 비교 결과." 일관된 이미지 생성
표 1: 의 정량적 비교 결과." 일관된 이미지 생성
 표 2: 현재 최첨단 전환 비디오 생성 모델과의 정량적 비교
표 2: 현재 최첨단 전환 비디오 생성 모델과의 정량적 비교
위 내용은 르쿤이 달에 가나요? Nankai와 Byte 오픈 소스 StoryDiffusion을 통해 다중 그림 만화와 긴 비디오를 더욱 일관되게 만듭니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7319
7319
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 Node.js 환경에서 403을 반환하는 타사 인터페이스 문제를 해결하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:27 PM
Node.js 환경에서 403을 반환하는 타사 인터페이스 문제를 해결하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:27 PM
Node.js 환경에서 403을 반환하는 타사 인터페이스의 문제를 해결하십시오. Node.js를 사용하여 타사 인터페이스를 호출 할 때 때때로 403을 반환하는 인터페이스에서 403의 오류가 발생합니다 ...
 Laravel에서는 이메일로 확인 코드를 보내지 못하는 상황을 처리하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:48 PM
Laravel에서는 이메일로 확인 코드를 보내지 못하는 상황을 처리하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:48 PM
Laravel의 이메일을 처리하지 않는 방법은 LaRavel을 사용하는 것입니다.
 시스템 재시작 후 UnixSocket의 권한을 자동으로 설정하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:54 PM
시스템 재시작 후 UnixSocket의 권한을 자동으로 설정하는 방법은 무엇입니까?
Mar 31, 2025 pm 11:54 PM
시스템이 다시 시작된 후 UnixSocket의 권한을 자동으로 설정하는 방법. 시스템이 다시 시작될 때마다 UnixSocket의 권한을 수정하려면 다음 명령을 실행해야합니다.
 PHP 2 차원 배열에서 정렬 및 순위를 추가하는 방법은 무엇입니까?
Apr 01, 2025 am 07:00 AM
PHP 2 차원 배열에서 정렬 및 순위를 추가하는 방법은 무엇입니까?
Apr 01, 2025 am 07:00 AM
PHP 2 차원 배열 분류 및 순위 구현에 대한 자세한 설명이 기사는 PHP 2 차원 배열을 정렬하고 정렬 결과에 따라 각 하위 배열을 사용하는 방법에 대해 자세히 설명합니다 ...
 Docker 환경에서 PECL을 사용하여 확장자를 설치할 때 오류가 발생하는 이유는 무엇입니까? 그것을 해결하는 방법?
Apr 01, 2025 pm 03:06 PM
Docker 환경에서 PECL을 사용하여 확장자를 설치할 때 오류가 발생하는 이유는 무엇입니까? 그것을 해결하는 방법?
Apr 01, 2025 pm 03:06 PM
Docker 환경을 사용할 때 Docker 환경에 Extensions를 설치하기 위해 PECL을 사용하여 오류의 원인 및 솔루션. 종종 일부 두통이 발생합니다 ...
 Laravel에서 이메일 전송이 실패 할 때 반환 코드를 얻는 방법은 무엇입니까?
Apr 01, 2025 pm 02:45 PM
Laravel에서 이메일 전송이 실패 할 때 반환 코드를 얻는 방법은 무엇입니까?
Apr 01, 2025 pm 02:45 PM
Laravel 이메일 전송이 실패 할 때 반환 코드를 얻는 방법. Laravel을 사용하여 응용 프로그램을 개발할 때 종종 확인 코드를 보내야하는 상황이 발생합니다. 그리고 실제로 ...
 Ouyi Okex 글로벌 웹 사이트 공식 웹 사이트 로그인 입구 2025
Mar 31, 2025 pm 03:45 PM
Ouyi Okex 글로벌 웹 사이트 공식 웹 사이트 로그인 입구 2025
Mar 31, 2025 pm 03:45 PM
Ouyi Okx (이전 Okex) Global Station은 2017 년에 설립되어 몰타에 본사를 둔 세계 최고의 디지털 자산 서비스 플랫폼입니다. 수천만 명의 사용자가 있습니다. 이 플랫폼은 150 개가 넘는 통화의 거래를 제공하며 엄격한 통화 감사 메커니즘과 시장 모니터링 및 진행중인 추적 메커니즘을 공식화했습니다. 미국 달러, 유로 및 파운드와 같은 20 개 이상의 주류 법적 통화 및 암호 화폐 거래를 지원합니다.

