
问个NLP领域问题。问题原话是这样的,"To what extent would syntactic parsing be useful in an opinion extraction system and an information retrieval system?"
题干里的opinion extraction system,information retrieval system是如何通过syntactic parsing实现的?求NLP大神讲解各自的细节和领域。
这个问题要怎么回答合适?
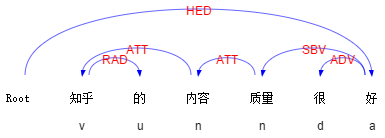
 (顺手插个广告,分析结果来自我们实验室的语言云:在线演示 | 语言云(语言技术平台云 LTP-Cloud))
(顺手插个广告,分析结果来自我们实验室的语言云:在线演示 | 语言云(语言技术平台云 LTP-Cloud))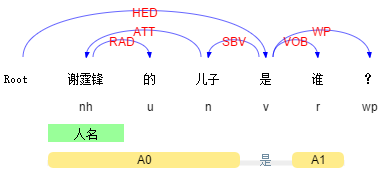
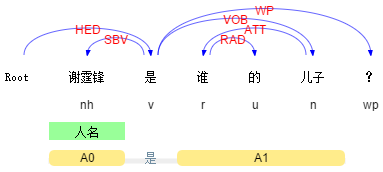
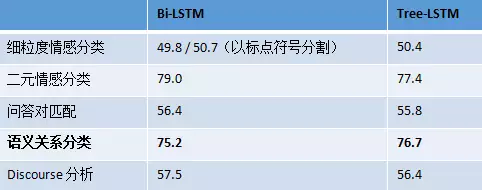
刚入手nlp不久,主要做的是文本情感分析方向,但并没有用句法分析做过研究,看到题主的问题,和所有答主的回答,并在近几日查阅了一些相关文献,针对题主所提问题做了整理,也对现有回答进行一些补充。
欢迎大家一起讨论^_^。
句法分析在opinion extraction(意见提取)中的应用:
1. What to do
首先对研究目标进行分析。
opinion extraction要解决的主要问题就是判断一句话或一段评论所蕴含的情感。如果仅以情感倾向性的判断作为唯一目标,那么就是一个分类问题,分类的结果可以为正向、负向、中性三类,或者加入强度,进行更细粒度的划分。当然,虽然情感倾向性的判断是一个值得研究的方向,但opinion extraction能挖掘出来的信息并不仅限于此。
上述的挖掘内容的差异,实际上引出了opinion extraction研究方向的两个大类。一个是sentiment classification,就是以情感倾向性判断的高正确率为目标的研究;另一个是sentiment related information extraction,更多地关注于对情感文本的组成元素进行分析。什么是组成元素?就是一段评论中,评论者,评论的主体,能体现评论者情感的情感词等等元素。
举个例子(取自[1])
I highly recommend the Canon SD500 to anybody looking for a compact camera that can take good pictures.
粗体字表示评论主体,斜体字划线字表示情感词
对于sentiment classification问题,对于上述数据,能够判断出它蕴含的情感是正向的,就够了。
而对于sentiment related information extraction问题,对于上述数据,要能够判断出Canon SD500的性能不错,如果有性能的分类,还应该将其分类到如“拍照性能”的类别中。
2.How to do and why is Syntactic Parsing important
说完要解决的问题,接下来说解决问题的方法,并分析句法分析在其中的关键作用
上面对opinion extraction的研究方向进行了一个分类。下面要说的是,句法分析在其中的应用。
句法分析对第一类问题的意义不大,这也是答主没有看到过用句法分析所做研究的原因。因为对于第一类问题,用统计的方法更为高效,效果也比较好。只需要对测试文本进行分词(英文的话根据空格分词就可以了),由文本中出现的所有词的情感倾向,对该文本的情感倾向进行预测就可以了。当然这是大致思路,若要提升准确率,还可以对文本的领域进行判断等等。
而在第二类问题中,句法分析的作用就大大的了。因为第一类问题可以将所有词平等看待,只需要根据标定数据,判断一个词在正向和负向评论中出现的概率。而要想知道一句话中哪个是评论的主题,哪个是修饰它的词,则必须要对语言规则有足够的设定,名词和形容词是存在本质差别的。另一方面,因为一句话中可能存在从句,所以可能形容词和其修饰的名词主体相距甚远,如果没有对句法规则有足够的判断,结果可能一塌糊涂。
关于句法分析,已有答主给出了很清晰的例子,在这里就不在赘述。在这里给出一个由规则进行情感词提取的例子(取自[2])
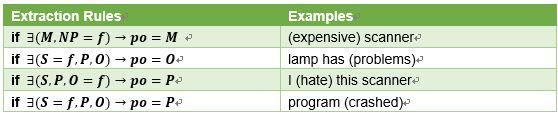
标志注释:
M: modifier,修饰词
NP: noun phrase,名词短语
S: subject,主语
P: predicate,谓语
O: object 宾语
f: feature 被评价的主体
这还不是全部的规则,由此也可以看出由句法结构来进行opinion extraction是麻烦而且准确率难以达到很高水准的,因为很难对所有的情况指定精确的规则。因此如何进行句法分析,在opinion extraction中也是一项研究内容。
句法分析在information retrieval中的应用:
1.what to do
答主之前没有接触过information retrieval,通过这段时间的调研,认为其解决的主要问题即为通过给定的查询输入,在一定范围内检索到相关的信息。一个重要的应用就是问答系统(question answering systems)。
2.How to do and why is Syntactic Parsing important
因为要通过对输入查询的分析,找到某一数据集(比如互联网)中与查询相关内容的信息,比如与查询语句相关的一段话,或针对所提问题直接给出一个简短的回答。
文献[6]将问答系统的任务大致分为三步,个人认为有参考意义:
(1)locating the relevant documents 定位相关文档
(2)retrieving passages that may contain the answer 在文档中找到可能包含答案的段落
(3)pinpointing the exact answer from candidate passages 在备选段落中精确定位,找到答案
由上可以看出,在进行information retrieval时,并非一步得到答案,而是不断缩小范围的。这就需要每一步都没有太大偏差,比如第(2)步,连可能包含答案的段落都找错了,那肯定不会找到正确的答案了。
因为查询实际上可以看为匹配操作,所以对输入语句的匹配和分析就会对查询结果起到决定性影响。下面用一个例子来进行说明(取自[7])
Q: What did George Washington call his house?
传统的方法,会在数据库(搜索范围)中对包含关键词的文档/段落进行匹配,毫无疑问,这个问题中的关键词是标绿的George Washington 和 house。于是找到了以下关键词:
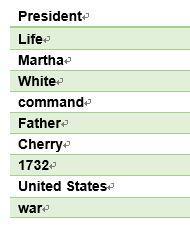
确实找到了一些相关的词语,但一个很大的问题就是,这样直接对关键词进行匹配,而不分析关键词之间的关系,就无法找到同时包含多个关键词的答案。也就是说,匹配出的词语仅与一个或少量关键词有关。但在问题中问的是George Washington的house,所以只匹配George Washington或之匹配house都是很难得到精确答案的。
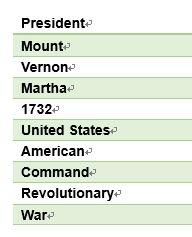
这是用句法分析,分析关键词之间的相关关系后,得到的相关结果。虽然有多个词语上面的结果相近,但后者会将与两个关键词都相关的结果排名提前,如”George’s Washington’s house, Mount Vernon.”这一搜索结果,其出现次数很少,在传统方法中,会被排到比较靠后的位置,但明显其与两个关键词同时相关,因此在句法分析的方法中,它会被排到很靠前的位置。
在文献[7]中还有更详细的举例说明,即如何通过句法分析建立parsing tree,对查询语句和搜索结果进行语法序列(因为每句话的词语之间存在相关关系,所以其可以看成是一个语法序列)的匹配,选择匹配得分高的结果作为答案。具体说明细节较多,就不在这里赘述了。
总结
上面说了句法分析如何解决opinion extraction和information retrieval的问题,有些琐碎。个人认为,总体来说,因为自然语言的词语词之间存在相关性,因此通过句法分析能够比仅用统计的方法挖掘出更多的信息量,当然统计的方法也可以在某些维度挖掘出句法分析所得不到的信息,所以这么说更准确一些:句法分析能够更直接地通过语法结构的规则约束筛选出对我们有用的结果,以这种方法来提升方法得准确性。
因为是看到题主的问题后于近期做了一些调研,回答可能有不完善之处,但答案中所举例子、所述理论均有文献依据,欢迎大家一起探讨^_^。
参考文献及pdf链接
Opinion extraction部分
[1] Wu Y, Zhang Q, Huang X, et al. Phrase dependency parsing for opinion mining[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3-Volume 3. Association for Computational Linguistics, 2009: 1533-1541.
链接:http://www.aclweb.org/anthology/D/D09/D09-1159.pdf
[2] Popescu A M, Etzioni O. Extracting product features and opinions from reviews[M]//Natural language processing and text mining. Springer London, 2007: 9-28.
链接: http://www.aclweb.org/old_anthology/H/H05/H05-1.pdf#page=375
[3] Poria S, Cambria E, Ku L W, et al. A rule-based approach to aspect extraction from product reviews[C]//Proceedings of the Second Workshop on Natural Language Processing for Social Media (SocialNLP). 2014: 28-37.
链接:http://www.anthology.aclweb.org/W/W14/W14-59.pdf#page=38
[4] Choi Y, Breck E, Cardie C. Joint extraction of entities and relations for opinion recognition[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2006: 431-439.
链接:http://www.aclweb.org/anthology/W/W06/W06-16.pdf#page=453
[5] Dave K, Lawrence S, Pennock D M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews[C]//Proceedings of the 12th international conference on World Wide Web. ACM, 2003: 519-528.
链接:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.13.2424&rep=rep1&type=pdf
Information extraction部分
[6] Cui H, Sun R, Li K, et al. Question answering passage retrieval using dependency relations[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2005: 400-407.
链接:http://www.comp.nus.edu.sg/~kanmy/papers/f66-cui.pdf
[7] Sun R, Ong C H, Chua T S. Mining dependency relations for query expansion in passage retrieval[C]//Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2006: 382-389.
链接:http://lms.comp.nus.edu.sg/sites/default/files/publication-attachments/sigir06-sunrenxu.pdf
[8] Carpineto C, Romano G. A survey of automatic query expansion in information retrieval[J]. ACM Computing Surveys (CSUR), 2012, 44(1): 1.
链接:
https://www.researchgate.net/profile/Claudio_Carpineto/publication/220566113_A_Survey_of_Automatic_Query_Expansion_in_Information_Retrieval/links/00b7d515aa3ac40767000000.pdf
【非常高兴看到大家喜欢并赞同我们的回答。应许多知友的建议,最近我们开通了同名公众号:PhDer,也会定期更新我们的文章,如果您不想错过我们的每篇回答,欢迎扫码关注~ 】
 我也来答一下好了,虽然没人邀_(:3」∠)
我也来答一下好了,虽然没人邀_(:3」∠)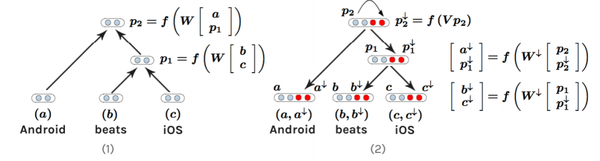 我是相信树的有效性的,或许只是我们没有提出更好的模型罢了
我本人是做文本情感分析的,经常用到句法依存分析,算是对这些有些了解,暂且发表一下个人的观点,不对之处希望指出,大家共同学习,共同进步。
我是相信树的有效性的,或许只是我们没有提出更好的模型罢了
我本人是做文本情感分析的,经常用到句法依存分析,算是对这些有些了解,暂且发表一下个人的观点,不对之处希望指出,大家共同学习,共同进步。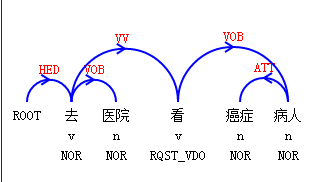
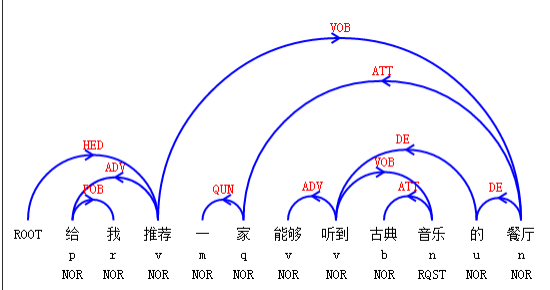
 类似的应用还有,不再一一列举。除此之外句法依存分析还是语义角色标注的基础。
类似的应用还有,不再一一列举。除此之外句法依存分析还是语义角色标注的基础。

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



