

Python 爬虫如何获取 JS 生成的 URL 和网页内容?

想尝试爬下北邮人的论坛,但是看到页面的源代码都是js,几乎没有我想要的信息。
回复内容:
今天偶然发现了PyV8这个东西,感觉就是你想要的。它直接搭建了一个js运行环境,这意味着你可以直接在python里面执行页面上的js代码来获取你需要的内容。
参考:
http://www.silverna.org/blog/?p=252
https://code.google.com/p/pyv8/ 我是直接看js源码,分析完,然后爬的。
例如看页面是用Ajax请求一个JSON文件,我就先爬那个页面,获取Ajax所需的参数,然后直接请求JSON页,然后解码,再处理数据并入库。
如果你直接运行页面上所有js(就像浏览器做的那样),然后获取最终的HTML DOM树,这样的性能非常地糟糕,不建议使用这样的方法。因为Python和js性能本身都很差,如果这样做,会消耗大量CPU资源并且最终只能获得极低的抓取效率。 js代码是需要js引擎运行的,Python只能通过HTTP请求获取到HTML、CSS、JS原始代码而已。
不知道有没有用Python编写的JS引擎,估计需求不大。
我一般用PhantomJS、CasperJS这些引擎来做浏览器抓取。
直接在其中写JS代码来做DOM操控、分析,以文件方式输出结果。
让Python去调用该程序,通过读文件方式获得内容。 去年还真爬过这样的数据,因为赶时间,我的方法就比较丑陋了。
PyQt有一个具体的库来模拟浏览器请求和行为(好像是webkit,忘记了,查一下就好。使用时就几行代码就够了),在一次运行程序中,第一次(只有第一次)的返回结果是js运行之后的代码。于是写了一个py脚本做一次访问解析,然后再写了windows脚本通过传递命令行参数循环这个py脚本,最后搞到数据。
方法dirty了些,不过数据拿到了就好~ 针对某网站的,可以自己看网络请求找到返回实际内容的那些有针对性地发。如果是通用的,得用 headless browser 了,比如 PhantomJS。 又一个爬北邮人论坛的。。
文艺的方法,上浏览器引擎,比如 PhantomJS ,用它导出 html,再对html用 python 解析。千万别直接 PhantomJS 解析,虽然我知道这很容易,为什么?
普通的方法,分析 AJAX 请求。即使它是 JS 渲染的,数据还是通过 HTTP 协议传输的。什么?你模拟不出来?
X-Requested-With:XMLHttpRequest
拉勾网的职位列表
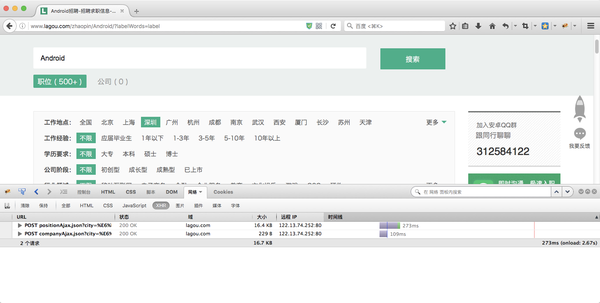

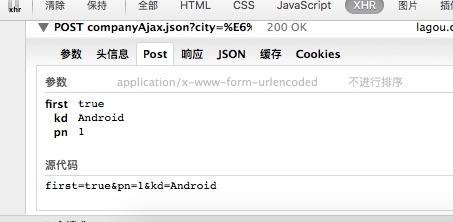
点击了Android之后 我们从浏览器上传了几个参数到拉勾的服务器
一个是 first =true, 一个是kd = android, (关键字) 一个是pn =1 (page number 页码)
所以我们就可以模仿这一个步骤来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
首先请一定记住,浏览器环境对内存和CPU的消耗都非常严重,模拟浏览器环境的爬虫代码要尽可能避免。请记住,对于一些前端渲染的网页,虽然在HTML源码中看不到我们需要的数据,但是更大的可能是它会通过另一个请求拿到纯数据(很大可能以JSON格式存在),我们不但不需要模拟浏览器,反而可以省去解析HTML的消耗。
然后,打开北邮人论坛的首页,发现它的首页HTML源码中确实没有页面所显示文章的内容,那么,很可能这是通过JS异步加载到页面的。通过浏览器开发工具(Chrome浏览器在OS X下通过command+option+i或Win/Linux下通过F12)分析在加载首页的时候请求,容易发现,如下截图中的请求:
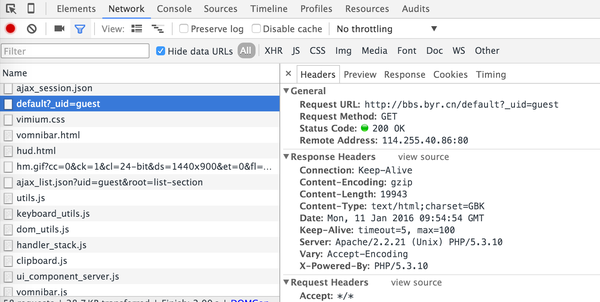 截图中选中的请求得到的response即是首页的文章链接,在preview选项中可以看到渲染后的预览图:
截图中选中的请求得到的response即是首页的文章链接,在preview选项中可以看到渲染后的预览图: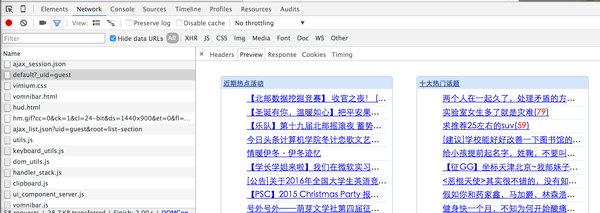 至此,我们确定这个链接可以拿到首页的文章及链接。
至此,我们确定这个链接可以拿到首页的文章及链接。在headers选项中,有这次请求的请求头及请求参数,我们通过Python模拟这次请求,即可拿到相同的响应。再配合BeautifulSoup等库解析HTML,即可得到相应的内容了。
对于如何模拟请求和如何解析HTML,请移步我的专栏,有详细的介绍,这里便不再赘述。
通过这样的方式可以不用模拟浏览器环境来抓取数据,对内存和CPU消耗、抓取速度都有很大的提升。在编写爬虫的时候,请务必记得,如非必要,不要模拟浏览器环境。 如果是在windows下,可以尝试调用windows系统中的webbrowser控件。另外ie本身也提供了接口。不过这两种方式都要渲染页面,性能上多少有点浪费,为了加快速度可以把ie的图片下载显示关闭掉,然后通过click等方法来模拟真实行为。 Google Phantom JS

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7504
7504
 15
1378
52
78
11
52
19
19
54
15
1378
52
78
11
52
19
19
54

 Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 볼 때 발생하는 권한 문제를 해결하는 방법은 무엇입니까?
Apr 01, 2025 pm 05:09 PM
Linux 터미널에서 Python 버전을 보려고 할 때 Linux 터미널에서 Python 버전을 볼 때 권한 문제에 대한 솔루션 ... Python을 입력하십시오 ...
 한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
한 데이터 프레임의 전체 열을 Python의 다른 구조를 가진 다른 데이터 프레임에 효율적으로 복사하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:15 PM
Python의 Pandas 라이브러리를 사용할 때는 구조가 다른 두 데이터 프레임 사이에서 전체 열을 복사하는 방법이 일반적인 문제입니다. 두 개의 dats가 있다고 가정 해
 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?
Apr 02, 2025 am 07:18 AM
10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?
 중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
중간 독서를 위해 Fiddler를 사용할 때 브라우저에서 감지되는 것을 피하는 방법은 무엇입니까?
Apr 02, 2025 am 07:15 AM
Fiddlerevery Where를 사용할 때 Man-in-the-Middle Reading에 Fiddlereverywhere를 사용할 때 감지되는 방법 ...
 Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 Serving_forever ()없이 HTTP 요청을 어떻게 지속적으로 듣습니까?
Apr 01, 2025 pm 10:51 PM
Uvicorn은 HTTP 요청을 어떻게 지속적으로 듣습니까? Uvicorn은 ASGI를 기반으로 한 가벼운 웹 서버입니다. 핵심 기능 중 하나는 HTTP 요청을 듣고 진행하는 것입니다 ...
 문자열을 통해 객체를 동적으로 생성하고 방법을 파이썬으로 호출하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:18 PM
문자열을 통해 객체를 동적으로 생성하고 방법을 파이썬으로 호출하는 방법은 무엇입니까?
Apr 01, 2025 pm 11:18 PM
파이썬에서 문자열을 통해 객체를 동적으로 생성하고 메소드를 호출하는 방법은 무엇입니까? 특히 구성 또는 실행 해야하는 경우 일반적인 프로그래밍 요구 사항입니다.
 인기있는 파이썬 라이브러리와 그 용도는 무엇입니까?
Mar 21, 2025 pm 06:46 PM
인기있는 파이썬 라이브러리와 그 용도는 무엇입니까?
Mar 21, 2025 pm 06:46 PM
이 기사는 Numpy, Pandas, Matplotlib, Scikit-Learn, Tensorflow, Django, Flask 및 요청과 같은 인기있는 Python 라이브러리에 대해 설명하고 과학 컴퓨팅, 데이터 분석, 시각화, 기계 학습, 웹 개발 및 H에서의 사용에 대해 자세히 설명합니다.
 정규 표현이란 무엇입니까?
Mar 20, 2025 pm 06:25 PM
정규 표현이란 무엇입니까?
Mar 20, 2025 pm 06:25 PM
정규 표현식은 프로그래밍의 패턴 일치 및 텍스트 조작을위한 강력한 도구이며 다양한 응용 프로그램에서 텍스트 처리의 효율성을 높입니다.
