

如何用爬虫下载中国土地市场网的土地成交数据?

作为毕业狗想研究下土地出让方面的信息,需要每一笔的土地出让数据。想从中国土地市场网的土地成交结果公告(http://www.landchina.com/default.aspx?tabid=263&ComName=default)中点击每一笔土地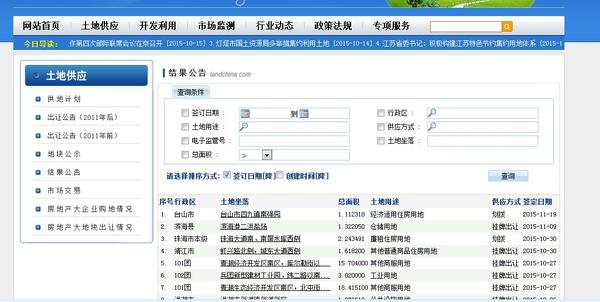 ,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,
,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,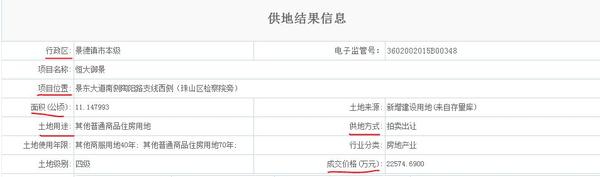 由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
回复内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import random
import sys
def get_post_data(url, headers):
# 访问一次网页,获取post需要的信息
data = {
'TAB_QuerySubmitSortData': '',
'TAB_RowButtonActionControl': '',
}
try:
req = requests.get(url, headers=headers)
except Exception, e:
print 'get baseurl failed, try again!', e
sys.exit(1)
try:
soup = BeautifulSoup(req.text, "html.parser")
TAB_QueryConditionItem = soup.find(
'input', id="TAB_QueryConditionItem270").get('value')
# print TAB_QueryConditionItem
data['TAB_QueryConditionItem'] = TAB_QueryConditionItem
TAB_QuerySortItemList = soup.find(
'input', id="TAB_QuerySort0").get('value')
# print TAB_QuerySortItemList
data['TAB_QuerySortItemList'] = TAB_QuerySortItemList
data['TAB_QuerySubmitOrderData'] = TAB_QuerySortItemList
__EVENTVALIDATION = soup.find(
'input', id='__EVENTVALIDATION').get('value')
# print __EVENTVALIDATION
data['__EVENTVALIDATION'] = __EVENTVALIDATION
__VIEWSTATE = soup.find('input', id='__VIEWSTATE').get('value')
# print __VIEWSTATE
data['__VIEWSTATE'] = __VIEWSTATE
except Exception, e:
print 'get post data failed, try again!', e
sys.exit(1)
return data
def get_info(url, headers):
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
items = soup.find(
'table', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1")
# 所需信息组成字典
info = {}
# 行政区
division = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl").get_text().encode('utf-8')
info['XingZhengQu'] = division
# 项目位置
location = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl").get_text().encode('utf-8')
info['XiangMuWeiZhi'] = location
# 面积(公顷)
square = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl").get_text().encode('utf-8')
info['MianJi'] = square
# 土地用途
purpose = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl").get_text().encode('utf-8')
info['TuDiYongTu'] = purpose
# 供地方式
source = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl").get_text().encode('utf-8')
info['GongDiFangShi'] = source
# 成交价格(万元)
price = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl").get_text().encode('utf-8')
info['ChengJiaoJiaGe'] = price
# print info
# 用唯一值的电子监管号当key, 所需信息当value的字典
all_info = {}
Key_ID = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl").get_text().encode('utf-8')
all_info[Key_ID] = info
return all_info
def get_pages(baseurl, headers, post_data, date):
print 'date', date
# 补全post data
post_data['TAB_QuerySubmitConditionData'] = post_data[
'TAB_QueryConditionItem'] + ':' + date
page = 1
while True:
print ' page {0}'.format(page)
# 休息一下,防止被网页识别为爬虫机器人
time.sleep(random.random() * 3)
post_data['TAB_QuerySubmitPagerData'] = str(page)
req = requests.post(baseurl, data=post_data, headers=headers)
# print req
soup = BeautifulSoup(req.text, "html.parser")
items = soup.find('table', id="TAB_contentTable").find_all(
'tr', onmouseover=True)
# print items
for item in items:
print item.find('td').get_text()
link = item.find('a')
if link:
print item.find('a').text
url = 'http://www.landchina.com/' + item.find('a').get('href')
print get_info(url, headers)
else:
print 'no content, this ten days over'
return
break
page += 1
if __name__ == "__main__":
# time.time()
baseurl = 'http://www.landchina.com/default.aspx?tabid=263'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36',
'Host': 'www.landchina.com'
}
post_data = (get_post_data(baseurl, headers))
date = '2015-11-21~2015-11-30'
get_pages(baseurl, headers, post_data, date)
之前帮老师爬过这个信息,从1995年-2015年有170多万条,算了下时间需要40多个小时才能爬完。我爬到2000年就没有继续爬了。当时写代码的时候刚学爬虫,不懂原理,发现这个网页点击下一页以及改变日期后,网址是不会变的,网址是不会变的,网址是不会变的Orz,对于新手来说根本不知道是为什么。后来就去找办法,学了点selenium,利用它来模拟浏览器操作,更改日期、点击下一页什么的都可以实现了。好处是简单粗暴,坏处是杀鸡用牛刀,占用了系统太多资源。再到后来,学会了一点抓包技术,知道了原来日期和换页都是通过post请求的。今天下午就把程序修改了一下,用post代替了原来的selenium。废话不说,上代码了。
# -*- coding: gb18030 -*-
'landchina 爬起来!'
import requests
import csv
from bs4 import BeautifulSoup
import datetime
import re
import os
class Spider():
def __init__(self):
self.url='http://www.landchina.com/default.aspx?tabid=263'
#这是用post要提交的数据
self.postData={ 'TAB_QueryConditionItem':'9f2c3acd-0256-4da2-a659-6949c4671a2a',
'TAB_QuerySortItemList':'282:False',
#日期
'TAB_QuerySubmitConditionData':'9f2c3acd-0256-4da2-a659-6949c4671a2a:',
'TAB_QuerySubmitOrderData':'282:False',
#第几页
'TAB_QuerySubmitPagerData':''}
self.rowName=[u'行政区',u'电子监管号',u'项目名称',u'项目位置',u'面积(公顷)',u'土地来源',u'土地用途',u'供地方式',u'土地使用年限',u'行业分类',u'土地级别',u'成交价格(万元)',u'土地使用权人',u'约定容积率下限',u'约定容积率上限',u'约定交地时间',u'约定开工时间',u'约定竣工时间',u'实际开工时间',u'实际竣工时间',u'批准单位',u'合同签订日期']
#这是要抓取的数据,我把除了分期约定那四项以外的都抓取了
self.info=[
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl',#0
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl',#1
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r17_c2_ctrl',#2
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl',#3
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl',#4
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c4_ctrl',#5
#这条信息是土地来源,抓取下来的是数字,它要经过换算得到土地来源,不重要,我就没弄了
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl',#6
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl',#7
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c2_ctrl', #8
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c4_ctrl',#9
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c2_ctrl',#10
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl',#11
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c1_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c2_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c3_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c4_0_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r9_c2_ctrl',#12
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r21_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c2',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c4_ctrl']
#第一步
def handleDate(self,year,month,day):
#返回日期数据
'return date format %Y-%m-%d'
date=datetime.date(year,month,day)
# print date.datetime.datetime.strftime('%Y-%m-%d')
return date #日期对象
def timeDelta(self,year,month):
#计算一个月有多少天
date=datetime.date(year,month,1)
try:
date2=datetime.date(date.year,date.month+1,date.day)
except:
date2=datetime.date(date.year+1,1,date.day)
dateDelta=(date2-date).days
return dateDelta
def getPageContent(self,pageNum,date):
#指定日期和页数,打开对应网页,获取内容
postData=self.postData.copy()
#设置搜索日期
queryDate=date.strftime('%Y-%m-%d')+'~'+date.strftime('%Y-%m-%d')
postData['TAB_QuerySubmitConditionData']+=queryDate
#设置页数
postData['TAB_QuerySubmitPagerData']=str(pageNum)
#请求网页
r=requests.post(self.url,data=postData,timeout=30)
r.encoding='gb18030'
pageContent=r.text
# f=open('content.html','w')
# f.write(content.encode('gb18030'))
# f.close()
return pageContent
#第二步
def getAllNum(self,date):
#1无内容 2只有1页 3 1—200页 4 200页以上
firstContent=self.getPageContent(1,date)
if u'没有检索到相关数据' in firstContent:
print date,'have','0 page'
return 0
pattern=re.compile(u'<td.*?class="pager".*?>共(.*?)页.*?</td>')
result=re.search(pattern,firstContent)
if result==None:
print date,'have','1 page'
return 1
if int(result.group(1))<=200:
print date,'have',int(result.group(1)),'page'
return int(result.group(1))
else:
print date,'have','200 page'
return 200
#第三步
def getLinks(self,pageNum,date):
'get all links'
pageContent=self.getPageContent(pageNum,date)
links=[]
pattern=re.compile(u'<a.*?href="default.aspx.*?tabid=386(.*?)".*?>',re.S)
results=re.findall(pattern,pageContent)
for result in results:
links.append('http://www.landchina.com/default.aspx?tabid=386'+result)
return links
def getAllLinks(self,allNum,date):
pageNum=1
allLinks=[]
while pageNum<=allNum:
links=self.getLinks(pageNum,date)
allLinks+=links
print 'scrapy link from page',pageNum,'/',allNum
pageNum+=1
print date,'have',len(allLinks),'link'
return allLinks
#第四步
def getLinkContent(self,link):
'open the link to get the linkContent'
r=requests.get(link,timeout=30)
r.encoding='gb18030'
linkContent=r.text
# f=open('linkContent.html','w')
# f.write(linkContent.encode('gb18030'))
# f.close()
return linkContent
def getInfo(self,linkContent):
"get every item's info"
data=[]
soup=BeautifulSoup(linkContent)
for item in self.info:
if soup.find(id=item)==None:
s=''
else:
s=soup.find(id=item).string
if s==None:
s=''
data.append(unicode(s.strip()))
return data
def saveInfo(self,data,date):
fileName= 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')+'/'+datetime.datetime.strftime(date,'%d')+'.csv'
if os.path.exists(fileName):
mode='ab'
else:
mode='wb'
csvfile=file(fileName,mode)
writer=csv.writer(csvfile)
if mode=='wb':
writer.writerow([name.encode('gb18030') for name in self.rowName])
writer.writerow([d.encode('gb18030') for d in data])
csvfile.close()
def mkdir(self,date):
#创建目录
path = 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')
isExists=os.path.exists(path)
if not isExists:
os.makedirs(path)
def saveAllInfo(self,allLinks,date):
for (i,link) in enumerate(allLinks):
linkContent=data=None
linkContent=self.getLinkContent(link)
data=self.getInfo(linkContent)
self.mkdir(date)
self.saveInfo(data,date)
print 'save info from link',i+1,'/',len(allLinks)
1. 多线程
2. 防止封IP
3. 用Mongdb存储大型非结构化数据
了解更多可以访问探码科技大数据介绍页面:http://www.tanmer.com/bigdata 我抓过这个网站的结束合同,还是比较好抓的。抓完生成表格,注意的就是选择栏的异步地区等内容,需要对他的js下载下来队形异步请求。提交数据即可。请求的时候在他的主页有一个id。好像是这么个东西,去年做的,记不清了,我有源码可以给你分享。用java写的 我是爬虫小白,请教下,不是说不能爬取asp的页面吗?
详细内容页的地址是”default.aspx?tabid=386&comname=default&wmguid=75c725。。。“,网站是在default.aspx页读取数据库显示详细信息,不是说读不到数据库里的数据吗?

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)
뜨거운 주제
 7393
7393
 15
1630
14
1358
52
1268
25
1217
29
15
1630
14
1358
52
1268
25
1217
29

 http 상태 코드 520은 무엇을 의미합니까?
Oct 13, 2023 pm 03:11 PM
http 상태 코드 520은 무엇을 의미합니까?
Oct 13, 2023 pm 03:11 PM
HTTP 상태 코드 520은 서버가 요청을 처리하는 동안 알 수 없는 오류가 발생하여 더 구체적인 정보를 제공할 수 없음을 의미합니다. 서버가 요청을 처리하는 동안 알 수 없는 오류가 발생했음을 나타내는 데 사용됩니다. 이는 서버 구성 문제, 네트워크 문제 또는 기타 알 수 없는 이유로 인해 발생할 수 있습니다. 이는 일반적으로 서버 구성 문제, 네트워크 문제, 서버 과부하 또는 코딩 오류로 인해 발생합니다. 상태 코드 520 오류가 발생하면 웹사이트 관리자나 기술 지원팀에 문의하여 자세한 정보와 지원을 받는 것이 가장 좋습니다.
 웹 페이지 리디렉션의 일반적인 애플리케이션 시나리오를 이해하고 HTTP 301 상태 코드를 이해합니다.
Feb 18, 2024 pm 08:41 PM
웹 페이지 리디렉션의 일반적인 애플리케이션 시나리오를 이해하고 HTTP 301 상태 코드를 이해합니다.
Feb 18, 2024 pm 08:41 PM
HTTP 301 상태 코드의 의미 이해: 웹 페이지 리디렉션의 일반적인 응용 시나리오 인터넷의 급속한 발전으로 인해 사람들은 웹 페이지 상호 작용에 대한 요구 사항이 점점 더 높아지고 있습니다. 웹 디자인 분야에서 웹 페이지 리디렉션은 HTTP 301 상태 코드를 통해 구현되는 일반적이고 중요한 기술입니다. 이 기사에서는 HTTP 301 상태 코드의 의미와 웹 페이지 리디렉션의 일반적인 응용 프로그램 시나리오를 살펴봅니다. HTTP301 상태 코드는 영구 리디렉션(PermanentRedirect)을 나타냅니다. 서버가 클라이언트의 정보를 받을 때
 Nginx 프록시 관리자를 사용하여 HTTP에서 HTTPS로 자동 점프를 구현하는 방법
Sep 26, 2023 am 11:19 AM
Nginx 프록시 관리자를 사용하여 HTTP에서 HTTPS로 자동 점프를 구현하는 방법
Sep 26, 2023 am 11:19 AM
NginxProxyManager를 사용하여 HTTP에서 HTTPS로의 자동 점프를 구현하는 방법 인터넷이 발전하면서 점점 더 많은 웹사이트가 HTTPS 프로토콜을 사용하여 데이터 전송을 암호화하여 데이터 보안과 사용자 개인 정보 보호를 향상시키기 시작했습니다. HTTPS 프로토콜에는 SSL 인증서 지원이 필요하므로 HTTPS 프로토콜 배포 시 특정 기술 지원이 필요합니다. Nginx는 강력하고 일반적으로 사용되는 HTTP 서버 및 역방향 프록시 서버이며 NginxProxy
 http 상태 코드 403이란 무엇입니까?
Oct 07, 2023 pm 02:04 PM
http 상태 코드 403이란 무엇입니까?
Oct 07, 2023 pm 02:04 PM
HTTP 상태 코드 403은 서버가 클라이언트의 요청을 거부했음을 의미합니다. http 상태 코드 403에 대한 해결 방법은 다음과 같습니다. 1. 서버에 인증이 필요한 경우 올바른 자격 증명이 제공되었는지 확인합니다. 2. 서버가 IP 주소를 제한한 경우 클라이언트의 IP 주소가 제한되어 있거나 블랙리스트에 없습니다. 3. 파일 권한 설정을 확인하십시오. 403 상태 코드가 파일 또는 디렉토리의 권한 설정과 관련되어 있으면 클라이언트가 해당 파일 또는 디렉토리에 액세스할 수 있는 권한이 있는지 확인하십시오. 등.
 빠른 적용: 여러 파일의 PHP 비동기 HTTP 다운로드에 대한 실제 개발 사례 분석
Sep 12, 2023 pm 01:15 PM
빠른 적용: 여러 파일의 PHP 비동기 HTTP 다운로드에 대한 실제 개발 사례 분석
Sep 12, 2023 pm 01:15 PM
빠른 적용: PHP의 실제 개발 사례 분석 여러 파일의 비동기 HTTP 다운로드 인터넷의 발전으로 파일 다운로드 기능은 많은 웹 사이트와 응용 프로그램의 기본 요구 사항 중 하나가 되었습니다. 여러 파일을 동시에 다운로드해야 하는 시나리오의 경우 기존 동기 다운로드 방법은 비효율적이고 시간이 많이 걸리는 경우가 많습니다. 이러한 이유로 PHP를 사용하여 HTTP를 통해 여러 파일을 비동기적으로 다운로드하는 것이 점점 더 일반적인 솔루션이 되었습니다. 본 글에서는 실제 개발 사례를 통해 PHP 비동기 HTTP를 활용하는 방법을 자세히 분석해 보겠습니다.
 http 요청 415 오류 해결 방법
Nov 14, 2023 am 10:49 AM
http 요청 415 오류 해결 방법
Nov 14, 2023 am 10:49 AM
해결 방법: 1. 요청 헤더에서 Content-Type을 확인합니다. 2. 요청 본문에서 데이터 형식을 확인합니다. 3. 적절한 인코딩 형식을 사용합니다. 4. 적절한 요청 방법을 사용합니다. 5. 서버측 지원을 확인합니다.
 C#의 일반적인 네트워크 통신 및 보안 문제와 솔루션
Oct 09, 2023 pm 09:21 PM
C#의 일반적인 네트워크 통신 및 보안 문제와 솔루션
Oct 09, 2023 pm 09:21 PM
C#의 일반적인 네트워크 통신 및 보안 문제와 해결 방법 오늘날 인터넷 시대에 네트워크 통신은 소프트웨어 개발에 없어서는 안 될 부분이 되었습니다. C#에서는 일반적으로 데이터 전송 보안, 네트워크 연결 안정성 등과 같은 일부 네트워크 통신 문제가 발생합니다. 이 문서에서는 C#의 일반적인 네트워크 통신 및 보안 문제에 대해 자세히 설명하고 해당 솔루션과 코드 예제를 제공합니다. 1. 네트워크 통신 문제 네트워크 연결 중단: 네트워크 통신 과정에서 네트워크 연결이 중단될 수 있으며, 이로 인해
 http.PostForm 함수를 사용하여 양식 데이터와 함께 POST 요청 보내기
Jul 25, 2023 pm 10:51 PM
http.PostForm 함수를 사용하여 양식 데이터와 함께 POST 요청 보내기
Jul 25, 2023 pm 10:51 PM
http.PostForm 함수를 사용하여 양식 데이터와 함께 POST 요청을 보낼 수 있습니다. Go 언어의 http 패키지에서는 http.PostForm 함수를 사용하여 양식 데이터와 함께 POST 요청을 보낼 수 있습니다. http.PostForm 함수의 프로토타입은 다음과 같습니다: funcPostForm(urlstring,dataurl.Values)(resp*http.Response,errerror)where, u
