
1, 오프닝 분석
지난 장에서는 NodeJS의 기본 이론적 지식을 배웠습니다. 이러한 이론적 지식을 이해하는 것이 중요합니다. 다음 장에서는 공식 문서에 따라 점차적으로 NodeJS에 포함된 다양한 모듈을 배워보겠습니다. 이번 글의 주인공이 무대에 오르기 위해 글로벌

공식 정의를 살펴보겠습니다.
전역 개체전역 개체이 개체는 모든 모듈에서 사용할 수 있습니다. 이러한 개체 중 일부는 실제로 전역 범위가 아니라 모듈 범위에 있습니다.
이러한 개체는 모든 모듈에서 사용할 수 있습니다. 실제로 일부 개체는 전역 범위에 있지 않지만 모듈 범위에 있습니다------이러한 내용은 식별됩니다.
브라우저에서 최상위 범위는 전역 범위입니다. 즉, 브라우저에서 전역 범위에 있으면 var something전역 변수가 정의됩니다.
Node에서는 최상위 범위가 전역 범위가 아닙니다. var somethingNode 모듈 내부는 해당 모듈에 대해 로컬입니다.
브라우저에서 가장 높은 수준의 범위는 Global Scope입니다. 즉, "var"를 사용하여 Global Scope에서 변수를 정의하면 이 변수는 다음과 같습니다. 전역 범위로 정의됩니다.
그러나 NodeJS에서는 다릅니다. 최상위 범위는 전역 범위가 아닙니다. 모듈에서 변수를 정의하려면 "var"을 사용하세요.
NodeJS에서 모듈에 정의된 변수, 함수 또는 메서드는 해당 모듈 내에서만 사용할 수 있지만 내보내기 개체를 사용하여 모듈 외부로 전달할 수 있습니다.
그러나 Node.js에는 여전히 전역 범위가 있습니다. 즉, 모듈을 로드하지 않고도 사용할 수 있는 일부 변수, 함수 또는 클래스를 정의할 수 있습니다.
동시에 일부 전역 메서드와 전역 클래스도 미리 정의되어 있습니다. Global 객체는 NodeJS의 전역 네임스페이스입니다. 모든 전역 변수, 함수 또는 객체는 객체의 속성 값입니다.
REPL 실행 환경에서는 아래 그림과 같이 다음 문을 통해 Global 객체의 세부 사항을 관찰할 수 있습니다.
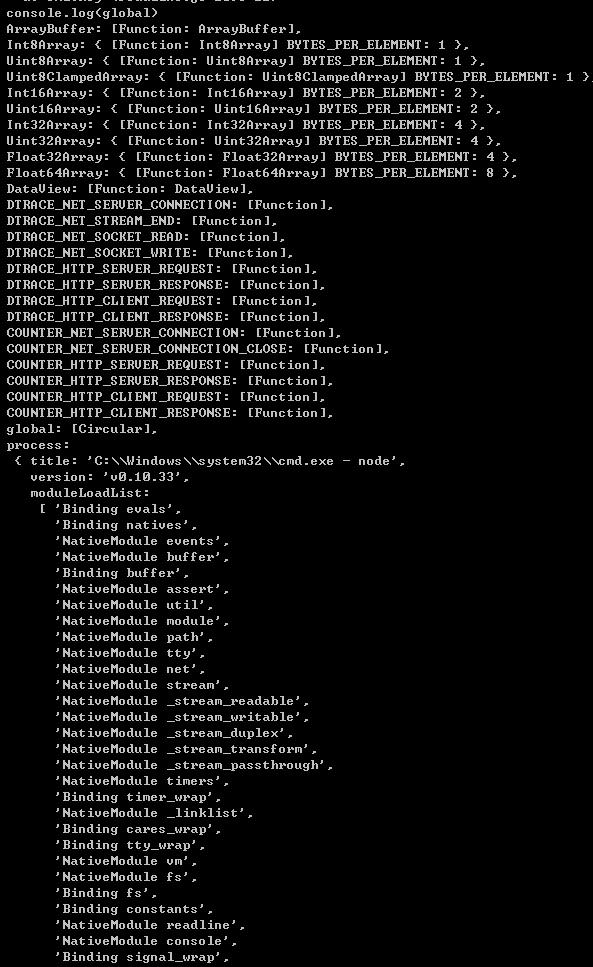
아래에서는 Global 객체에 탑재된 관련 속성값 객체에 대해 하나씩 이야기하겠습니다.
(1), 프로세스
프로세스 {Object} 프로세스 객체입니다. 프로세스 객체 섹션을 참조하세요.
프로세스 {object} 프로세스 개체입니다. 다음 장에서 자세히 설명하겠지만 여기서는 이에 대해 이야기하기 위해 API를 꺼내고 싶습니다.
Process.nextTick(콜백)
이벤트 루프 주변의 다음 루프에서 이 콜백을 호출합니다. 이는 setTimeout(fn, 0)에 대한 단순한 별칭이 아니며 일반적으로 다른 I/O 이벤트가 발생하기 전에 실행되는 것이 훨씬 더 효율적입니다. 예외는 아래 process.maxTickDepth를 참조하세요.
이벤트 루프의 다음 반복에서 콜백 콜백 함수를 호출합니다. 이는 훨씬 더 효율적이므로 setTimeout(fn, 0) 함수에 대한 단순한 별칭이 아닙니다.
이 함수는 I/O 전에 콜백 함수를 호출할 수 있습니다. 객체가 생성된 후 I/O 작업이 발생하기 전에 일부 작업을 수행하려는 경우 이 기능은 매우 중요합니다.
Node.js에서 process.nextTick()의 사용법을 이해하지 못하는 분들이 많습니다. process.nextTick()이 무엇인지, 어떻게 사용하는지 살펴보겠습니다.
Node.js는 시스템 IO 외에도 이벤트 폴링 프로세스 중에 하나의 이벤트만 동시에 처리됩니다. 이벤트 폴링은 각 시점에서 시스템이 하나의 이벤트만 처리하는 대규모 대기열로 생각할 수 있습니다.
컴퓨터에 CPU 코어가 여러 개 있더라도 동시에 여러 이벤트를 병렬로 처리할 수는 없습니다. 그러나 node.js가 I/O 유형 애플리케이션 처리에는 적합하지만 CPU 기반 컴퓨팅 애플리케이션에는 적합하지 않은 것이 바로 이러한 특성입니다.
모든 I/O 유형 애플리케이션에서는 각 입력 및 출력에 대한 콜백 함수만 정의하면 이벤트 폴링 처리 대기열에 자동으로 추가됩니다.
I/O 작업이 완료되면 이 콜백 함수가 트리거됩니다. 그런 다음 시스템은 다른 요청을 계속 처리합니다.
이 처리 모드에서 process.nextTick()은 작업을 정의하고 이 작업이 다음 이벤트 폴링 시점에 실행되도록 하는 것을 의미합니다. 예를 살펴보겠습니다. 예제에는 foo()가 있습니다. 다음 시점에 호출하려면 다음과 같이 하면 됩니다.
위 코드를 실행하면 아래 터미널에 인쇄된 정보에서 "bar"의 출력이 "foo" 앞에 오는 것을 볼 수 있습니다. 위의 문장을 확인하면 다음 시점에 foo()가 실행됩니다.
setTimeout() 함수를 사용하여 겉보기에 동일한 실행 효과를 얻을 수도 있습니다.
하지만 내부 처리 메커니즘 측면에서 process.nextTick()과 setTimeout(fn, 0)은 다릅니다. process.nextTick()은 단순한 지연이 아니라 기능이 더 많습니다.
더 정확하게 말하면 process.nextTick()에 의해 정의된 호출은 새로운 하위 스택을 생성합니다. 현재 스택에서는 원하는 만큼의 작업을 수행할 수 있습니다. 그러나 netxTick이 호출되면 함수는 상위 스택으로 반환되어야 합니다. 그런 다음 이벤트 폴링 메커니즘은 새 이벤트가 다시 처리될 때까지 기다립니다. nextTick에 대한 호출이 발견되면 새 스택이 생성됩니다.
process.nextTick()을 언제 사용해야 하는지 살펴보겠습니다.
여러 이벤트에 걸쳐 CPU 집약적인 작업을 교차 실행합니다.
다음 예에는 계산 집약적인 일부 작업을 수행하기 위해 이 함수가 최대한 지속적으로 실행되기를 바랍니다.
그러나 동시에 이 기능으로 인해 시스템이 차단되지 않고 다른 이벤트에 응답하고 처리할 수 있기를 바랍니다. 이 애플리케이션 모델은 단일 스레드 웹 서비스 서버와 같습니다. 여기서는 process.nextTick()을 사용하여 Compute()와 일반 이벤트 응답을 교차 실행할 수 있습니다.
이 모드에서는 계산()을 재귀적으로 호출할 필요가 없습니다. 이벤트 루프에서 process.nextTick()을 사용하여 다음 시점에 실행될 계산()을 정의하면 됩니다.
이 과정에서 새로운 http 요청이 들어오면 이벤트 루프 메커니즘은 먼저 새로운 요청을 처리한 다음 Compute()를 호출합니다.
반대로 재귀 호출에 계산()을 넣으면 시스템은 항상 계산()에서 차단되어 새로운 http 요청을 처리할 수 없습니다. 직접 시도해 볼 수 있습니다.
물론 process.nextTick()을 통해 여러 CPU에서 병렬 실행의 실제 이점을 얻을 수는 없습니다. 이는 CPU에서 동일한 애플리케이션의 분할 실행만 시뮬레이션합니다.
(2),콘솔
console {Object} stdout 및 stderr로 인쇄하는 데 사용됩니다. stdio 섹션을 참조하세요.
콘솔 {object}는 표준 출력 및 오류 출력으로 인쇄하는 데 사용됩니다. 아래 테스트를 참조하세요.
다음과 같은 결과가 출력됩니다.
재NodeJS中,有两种작동域,분할전체局작용域및模块작용域
而global.name='global-name';是为 전체局对象정义一个name 属性,
而 this.name = '모듈 이름';是为模块对象定义了一个name 属性
那么我们来验证一下,将下face保存成test2.js,运行
exports与module.exports의 一点区别
才是真정적 接口,수출只不过是它的一个辅助工具。最终返回给调用是
而不是export。
Module.exports 所有的exports收集到的属性属性層了Module.exports。当然,这有个前提,就是
Module.exportsModule.exports
本身不具备任何属性和方法。
如果,
Module.exports 举个栗子:已经具备一些属性和方法,那么exports收集来的信息将被忽略。
bb.js를 다시 참조하고 실행
모듈이 반드시 "인스턴스화된 객체"를 반환할 필요는 없다는 것을 알 수 있습니다. 모듈은 부울, 숫자, 날짜, JSON, 문자열, 함수, 배열 등 합법적인 JavaScript 개체일 수 있습니다.
(4), setTimeout, setInterval, process.nextTick, setImmediate
요약하면 다음과 같은 내용이 나옵니다
Nodejs의 특징은 비동기 I/O에 의해 생성되는 높은 동시성입니다. 이벤트는 유휴 관찰자 및 타이머 관찰자와 같은 해당 이벤트 관찰자로 분류됩니다. O 관찰자 등. 이벤트 루프의 각 주기를 Tick이라고 합니다. 각 Tick은 이벤트 관찰자로부터 이벤트를 순서대로 가져와서 처리합니다.
setTimeout() 또는 setInterval()을 호출할 때 생성된 타이머는 타이머 관찰자 내부의 레드-블랙 트리에 배치됩니다. 틱할 때마다 타이머가 레드-블랙 트리에서 시간 초과를 초과했는지 확인합니다. . 를 초과하면 해당 콜백 함수가 즉시 실행됩니다. setTimeout()과 setInterval() 모두 타이머로 사용되는데, 차이점은 후자가 반복적으로 트리거된다는 점이며, 시간이 너무 짧게 설정되어 있기 때문에 처리가 완료된 후 바로 이전 트리거 이후의 처리가 트리거됩니다.
타이머는 타임아웃에 의해 트리거되므로 트리거 정확도가 감소합니다. 예를 들어 이벤트 루프가 4초에 작업을 반복하고 실행 시간이 3초인 경우 setTimeout으로 설정된 타임아웃은 5초입니다. , 그러면 setTimeout 콜백 함수가 2초 후에 만료되므로 정확도가 감소합니다. 그리고 타이머를 절약하고 트리거를 결정하기 위해 레드-블랙 트리와 반복 방법을 사용하기 때문에 성능이 낭비됩니다.
process.nextTick()을 사용하여 설정된 모든 콜백 함수는 배열에 배치되며 모두 다음 Tick에서 즉시 실행됩니다. 이 작업은 비교적 가볍고 시간 정확도가 높습니다.
setImmediate()에 의해 설정된 콜백 함수는 다음 Tick에서도 호출됩니다. 이 함수와 process.nextTick()의 차이점은 두 가지 점에 있습니다.
1. 그들이 속한 관찰자는 서로 다른 우선순위로 실행됩니다. process.nextTick()은 유휴 관찰자에 속하고, setImmediate()는 검사 관찰자에 속하며, 유휴 > 검사의 우선순위가 있습니다.
2. setImmediate()로 설정된 콜백 함수는 연결된 목록에 배치됩니다. 각 Tick은 연결된 목록에서 하나의 콜백만 실행합니다. 이는 각 Tick이 빠르게 실행될 수 있도록 하기 위한 것입니다.
둘째, 요약
1. Global 객체의 존재 의미를 이해합니다
2. 내보내기와 module.exports의 약간의 차이점
3. 콘솔의 기본 구조는 무엇입니까(프로세스 개체의 상위 수준 캡슐화)
4. setTimeout, setInterval, process.nextTick, setImmediate의 차이점
5. NodeJS의 두 가지 유형의 범위

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



