
강의 중급 11382
코스소개:"IT 네트워크 리눅스 로드밸런싱 자습 영상 튜토리얼"은 nagin 하에서 web, lvs, Linux에서 스크립트 연산을 수행하여 Linux 로드밸런싱을 주로 구현합니다.

강의 고급의 17696
코스소개:"Shangxuetang MySQL 비디오 튜토리얼"은 MySQL 데이터베이스 설치부터 사용까지의 과정을 소개하고, 각 링크의 구체적인 작동 방법을 자세히 소개합니다.

강의 고급의 11395
코스소개:"Band of Brothers 프런트엔드 예제 디스플레이 비디오 튜토리얼"은 HTML5 및 CSS3 기술의 예를 모든 사람에게 소개하여 모든 사람이 HTML5 및 CSS3 사용에 더욱 능숙해질 수 있도록 합니다.
문제 2003(HY000) 해결 방법: MySQL 서버 'db_mysql:3306'에 연결할 수 없습니다(111).
2023-09-05 11:18:47 0 1 884
2023-09-05 14:46:42 0 1 769
CSS 그리드: 하위 콘텐츠가 열 너비를 초과할 때 새 행 생성
2023-09-05 15:18:28 0 1 650
AND, OR 및 NOT 연산자를 사용한 PHP 전체 텍스트 검색 기능
2023-09-05 15:06:32 0 1 620
2023-09-05 15:34:44 0 1 1035

코스소개:심층 강화 학습(DeepReinforcementLearning)은 딥 러닝과 강화 학습을 결합한 고급 기술로 음성 인식, 이미지 인식, 자연어 처리 등의 분야에서 널리 사용됩니다. 빠르고 효율적이며 안정적인 프로그래밍 언어인 Go 언어는 심층 강화 학습 연구에 도움을 줄 수 있습니다. 이 기사에서는 Go 언어를 사용하여 심층 강화 학습 연구를 수행하는 방법을 소개합니다. 1. Go 언어 및 관련 라이브러리를 설치하고 심층 강화 학습을 위해 Go 언어 사용을 시작합니다.
2023-06-10 논평 0 1220
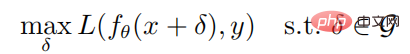
코스소개:01 서문 본 논문은 공격에 대한 심층 강화 학습 작업에 관한 것입니다. 본 논문에서 저자는 강력한 최적화의 관점에서 적대적 공격에 대한 심층 강화 학습 전략의 견고성을 연구합니다. 강력한 최적화 프레임워크에서는 전략의 예상 수익을 최소화하여 최적의 적대 공격이 제공되며, 이에 따라 최악의 시나리오에 대처할 때 전략의 성능을 향상시켜 우수한 방어 메커니즘이 달성됩니다. 공격자는 일반적으로 훈련 환경에서 공격할 수 없다는 점을 고려하여, 저자는 환경과 상호 작용하지 않고 전략의 예상 수익을 최소화하려고 시도하는 탐욕적 공격 알고리즘을 제안하고, 또한 공격자 훈련을 수행하는 방어 알고리즘도 제안합니다. 최대 최소 게임을 이용한 심층 강화 학습 알고리즘. Atari 게임 환경에서의 실험 결과는 다음과 같습니다.
2023-04-08 논평 0 1326
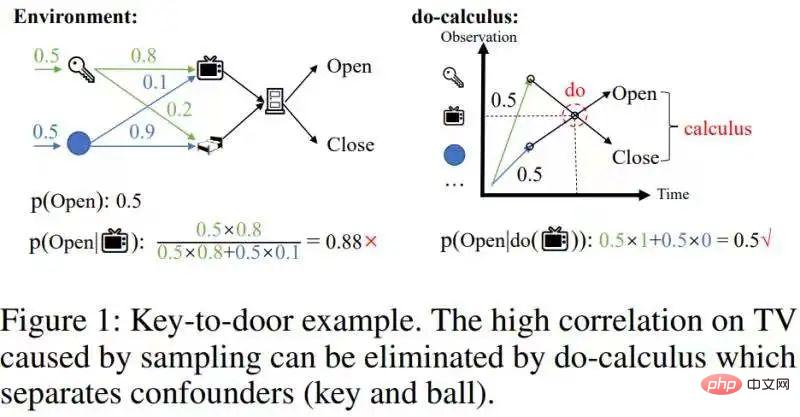
코스소개:이 기사 "역사 기반 강화 학습을 위한 빠른 반사실 추론"에서는 인과 추론의 계산 복잡성을 온라인 강화 학습과 결합할 수 있는 수준으로 크게 줄이는 빠른 인과 추론 알고리즘을 제안합니다. 이 논문의 이론적 기여는 주로 두 가지 사항을 포함합니다: 1. 시간 평균 인과 효과의 개념을 제안했습니다. 2. 유명한 백도어 기준을 단변량 개입 효과 추정에서 단계 백도어 기준이라고 하는 다변량 개입 효과 추정으로 확장했습니다. 배경지식은 부분적으로 관찰 가능한 강화학습과 인과추론에 대한 기본 지식의 준비가 필요합니다. 여기서는 너무 많은 소개를 하지 않고 몇 가지 포털을 제공하겠습니다. 부분적으로 관찰 가능한 향상
2023-04-15 논평 0 1081

코스소개:역 강화 학습(IRL)은 관찰된 행동을 사용하여 그 뒤에 있는 근본적인 동기를 추론하는 기계 학습 기술입니다. 기존 강화 학습과 달리 IRL은 명시적인 보상 신호를 요구하지 않지만 대신 행동을 통해 잠재적인 보상 기능을 추론합니다. 이 방법은 인간의 행동을 이해하고 시뮬레이션하는 효과적인 방법을 제공합니다. IRL의 작동 원리는 MDP(Markov Decision Process) 프레임워크를 기반으로 합니다. MDP에서 에이전트는 다양한 작업을 선택하여 환경과 상호 작용합니다. 환경은 에이전트의 행동에 따라 보상 신호를 제공합니다. IRL의 목표는 에이전트의 행동을 설명하기 위해 관찰된 에이전트 행동으로부터 알려지지 않은 보상 함수를 추론하는 것입니다. IRL은 에이전트가 다양한 상태에서 선택하는 작업을 분석하여 에이전트의 행동을 모델링할 수 있습니다.
2024-01-22 논평 0 885

코스소개:AB 테스트는 온라인 실험에 널리 사용되는 기술입니다. 주요 목적은 두 개 이상의 페이지 또는 애플리케이션 버전을 비교하여 어떤 버전이 더 나은 비즈니스 목표를 달성하는지 결정하는 것입니다. 이러한 목표는 클릭률, 전환율 등이 될 수 있습니다. 이에 비해 강화학습은 시행착오 학습을 통해 의사결정 전략을 최적화하는 기계학습 방법이다. 정책 경사 강화학습(Policy Gradient Reinforcement Learning)은 최적의 정책을 학습하여 누적 보상을 극대화하는 것을 목표로 하는 특별한 강화학습 방법입니다. 둘 다 비즈니스 목표를 최적화하는 데 서로 다른 응용 프로그램을 가지고 있습니다. AB 테스트에서는 서로 다른 페이지 버전을 서로 다른 행동으로 생각하며, 비즈니스 목표는 보상 신호의 중요한 지표로 생각할 수 있습니다. 최대의 비즈니스 목표를 달성하기 위해서는 선택할 수 있는 전략을 설계해야 합니다.
2024-01-24 논평 0 995
