인덱스를 사용하지 않기 때문에 collscan에서는 전체 컬렉션 스캔임을 나타내므로 인덱스 생성을 고려해 볼 수 있습니다
2. 두 번째 실행 계획:
여전히 전체 컬렉션 스캔이며 조건을 충족하는 문서가 메모리로 스캔되고 메모리에서 프로젝션이 완료되어 지정된 필드가 선택되고 해당 필드가 반환됩니다. 이렇게 되면 시간이 더 걸릴 것 같습니다.
지정된 필드만 반환되지만, 저장소를 읽거나 전체 모음을 스캔하는 경우 전체 문서만 반환될 수 있습니다. 이것은 아마도 데이터베이스의 몇 가지 기본 원칙일 것입니다. 또한 일부 열 형식 데이터베이스는 상상했던 상황이지만 많은 데이터베이스는 행 또는 문서에 따라 저장됩니다.
지정된 필드에 포함된 인덱스를 생성하고 지정된 필드만 반환하는 경우 인덱스를 스캔해야만 지정된 필드를 반환할 수 있으므로 이것이 가장 효율적입니다.


















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




귀하가 게시한 실행 계획에는 주로 다음 정보가 공개됩니다.
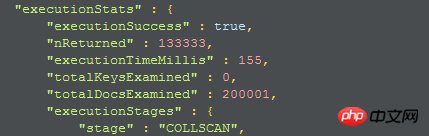
1. 첫 번째 실행 계획:
인덱스를 사용하지 않기 때문에 collscan에서는 전체 컬렉션 스캔임을 나타내므로 인덱스 생성을 고려해 볼 수 있습니다
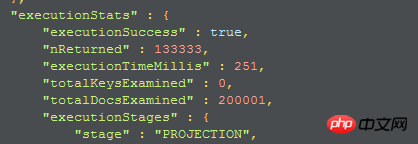
2. 두 번째 실행 계획:
여전히 전체 컬렉션 스캔이며 조건을 충족하는 문서가 메모리로 스캔되고 메모리에서 프로젝션이 완료되어 지정된 필드가 선택되고 해당 필드가 반환됩니다. 이렇게 되면 시간이 더 걸릴 것 같습니다.
지정된 필드만 반환되지만, 저장소를 읽거나 전체 모음을 스캔하는 경우 전체 문서만 반환될 수 있습니다. 이것은 아마도 데이터베이스의 몇 가지 기본 원칙일 것입니다. 또한 일부 열 형식 데이터베이스는 상상했던 상황이지만 많은 데이터베이스는 행 또는 문서에 따라 저장됩니다.
지정된 필드에 포함된 인덱스를 생성하고 지정된 필드만 반환하는 경우 인덱스를 스캔해야만 지정된 필드를 반환할 수 있으므로 이것이 가장 효율적입니다.
참고로.
MongoDB를 사랑해주세요! 재미있게 보내세요!