1. 이러한 문제가 발생하면 내 해결책은 통계용 playfrom_count와 같은 새 테이블을 만드는 것입니다. 프레임워크에서 after_insert 및 after_delete와 같은 메서드를 사용하는 것이 더 좋습니다. 2 .. 이러한 쿼리 비즈니스의 양이 많지 않거나 정확하지 않은 경우 가끔씩 업데이트하여 작업을 수행할 수 있습니다. 3. innodb이든 myisam이든 상관없습니다. 어디에 추가하면 전체 테이블을 스캔하므로 기본 키를 추가하여 검색 속도를 높일 수 있습니다.
비즈니스 시나리오의 요구 사항을 먼저 고려하는 것이 좋습니다. 순수 기술 솔루션은 비용이 너무 높으며 많은 경우 기본적으로 구현이 불가능합니다. 가능한 해결 방법은 다음과 같습니다. 1. 테이블 분할: 스토리지 엔진은 MyISAM입니다. 쿼리 문은 총 행 수를 저장합니다. 테이블에 포함되므로 쿼리 효율성이 크게 향상됩니다. MyISAM은 트랜잭션을 지원하지 않기 때문에 하위 테이블로 인한 시스템 변환 작업량과 MyISAM이 시스템 요구 사항을 충족할 수 있는지 여부를 고려해야 합니다.
2. 중복된 테이블이나 필드를 생성하고, 변경 시 요약해야 하는 데이터를 다시 계산합니다. 많은 업데이트 작업으로 인해 시스템 부하가 증가하는지 고려해야 합니다.
3. 쿼리 결과가 완전히 정확할 필요가 없으면 정기적으로 결과를 계산하여 저장할 수 있습니다. 쿼리 시 원본 테이블을 직접 쿼리하지 않습니다.















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




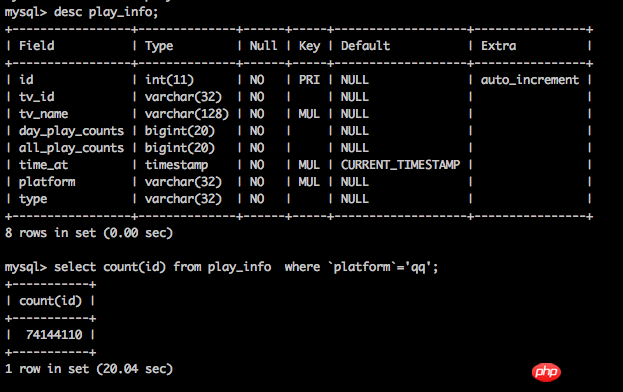
count(*)는 (null인지 여부에 관계없이) 각 열의 값을 계산하지 않고 행 수를 직접 계산하므로 더 효율적입니다.
제거 방법을 사용할 수도 있습니다. 예를 들어 플랫폼이 qq이고 데이터가 많으면 전체 데이터를 사용하여 platform=other;
의 데이터를 뺄 수 있습니다.비즈니스 관점에서 보면 정확한 값을 얻는 데 드는 비용은 매우 높지만, 요구 사항이 엄격하지 않은 경우 대략적인 값을 대신 사용할 수 있습니다.
또한 이러한 시간 소모적인 데이터 수집을 유지하기 위해 redis와 같은 "메모리 데이터베이스"를 사용하는 것도 고려할 수 있습니다.1. 이러한 문제가 발생하면 내 해결책은 통계용 playfrom_count와 같은 새 테이블을 만드는 것입니다.
프레임워크에서 after_insert 및 after_delete와 같은 메서드를 사용하는 것이 더 좋습니다.
2 .. 이러한 쿼리 비즈니스의 양이 많지 않거나 정확하지 않은 경우 가끔씩 업데이트하여 작업을 수행할 수 있습니다.
3. innodb이든 myisam이든 상관없습니다. 어디에 추가하면 전체 테이블을 스캔하므로 기본 키를 추가하여 검색 속도를 높일 수 있습니다.
Option 1. 플랫폼에 대한 파티션 테이블 생성
Option 2. 플랫폼별로 테이블 분할
Option 3. 플랫폼에 대한 별도의 인덱스를 생성하지만, 플랫폼의 값 세트가 너무 크지 않아야 한다는 점을 고려하면 그렇지 않습니다. 이 색인을 수행하기에 적합합니다
이 문제는 기존 관계형 데이터베이스에서 발생합니다. 일반적인 해결 방법은 각 테이블의 데이터 행 수를 포함하는 시스템 테이블에 액세스하는 것입니다. 이는 COUNT(*)보다 훨씬 빠릅니다.
머신 업그레이드는 간단한 계산에도 20초가 소요됩니다. 파티션 테이블 등 다양한 방법이 있지만 투자할만한 가치가 없다고 느껴집니다.
비즈니스 시나리오의 요구 사항을 먼저 고려하는 것이 좋습니다. 순수 기술 솔루션은 비용이 너무 높으며 많은 경우 기본적으로 구현이 불가능합니다.
가능한 해결 방법은 다음과 같습니다.
1. 테이블 분할: 스토리지 엔진은 MyISAM입니다. 쿼리 문은 총 행 수를 저장합니다. 테이블에 포함되므로 쿼리 효율성이 크게 향상됩니다. MyISAM은 트랜잭션을 지원하지 않기 때문에 하위 테이블로 인한 시스템 변환 작업량과 MyISAM이 시스템 요구 사항을 충족할 수 있는지 여부를 고려해야 합니다.
2. 중복된 테이블이나 필드를 생성하고, 변경 시 요약해야 하는 데이터를 다시 계산합니다. 많은 업데이트 작업으로 인해 시스템 부하가 증가하는지 고려해야 합니다.
3. 쿼리 결과가 완전히 정확할 필요가 없으면 정기적으로 결과를 계산하여 저장할 수 있습니다. 쿼리 시 원본 테이블을 직접 쿼리하지 않습니다.
이 경우에는 월별 또는 분기별로 여러 개의 통계 테이블로 나눌 수 있습니다. 예를 들어 800만 개의 데이터가 있는 경우 새 테이블을 만들고 각 행은 한 달의 총 기록을 나타냅니다. 이렇게 하면 통계가 훨씬 빨라집니다.