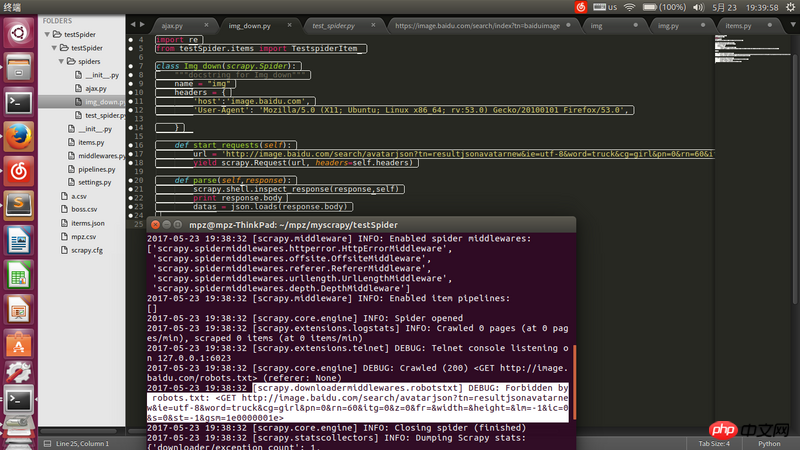
요청 주소 URL은 Firefox를 통해 얻은 json의 주소입니다. 브라우저로 열 수 있지만, scrapy로 크롤링할 때 금지되어 있습니다.
https://image.baidu.com/searc...
settings.py 将 ROBOTSTXT_OBEY = False에서 사용해 보세요.
settings.py
ROBOTSTXT_OBEY = False
청취자를 추가하지 않고 사용해 보세요
벽이 여전히 남아 있다면 위층에 동의합니다. scrapy+selenium+phantomjs 방법을 사용할 수 있습니다.














![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




settings.py将ROBOTSTXT_OBEY = False에서 사용해 보세요.청취자를 추가하지 않고 사용해 보세요
벽이 여전히 남아 있다면 위층에 동의합니다. scrapy+selenium+phantomjs 방법을 사용할 수 있습니다.