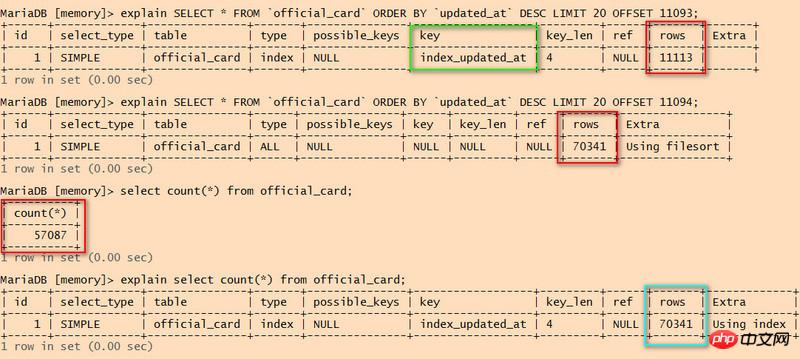
처음 두 문을 비교해 보면 두 번째 문은 인덱스를 사용하지 않는데, 스캔된 행 수가 특정 수에 도달하면 인덱스가 포기된다는 것을 기억합니다.
전체 테이블 스캔을 보면 스캔된 행 수가 70341개인데, 전체 데이터 행 수가 57087개에 불과하다고요?
select count(*)는 인덱스를 사용하지만 70341개 행도 검색합니다. 이 문으로 인해 성능 문제가 발생합니까?
CBO 최적화 메커니즘의 데이터베이스에는 인덱스 사용 여부에 대한 명확한 임계값이 없습니다. 실행 계획의 최소 COST를 기준으로 사용하는 경우는 인덱스를 사용하는 것이 더 적합하다는 것입니다. 테이블의 총 행 수가 5% 미만입니다.
두 번째 문은 테이블의 통계 데이터를 사용하는 것으로 알고 있습니다. 테이블이 최근에 크게 변경되었고 통계 데이터가 제때 업데이트되지 않은 경우 둘 사이에 큰 차이가 있을 것입니다.
count(*)는 인덱스를 사용합니다. 이는 update_at 필드에 NOT NULL 정의가 있음을 의미합니다. 전체 테이블 스캔에 비해 인덱스 스캔 비용이 더 낮습니다.














![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




CBO 최적화 메커니즘의 데이터베이스에는 인덱스 사용 여부에 대한 명확한 임계값이 없습니다. 실행 계획의 최소 COST를 기준으로 사용하는 경우는 인덱스를 사용하는 것이 더 적합하다는 것입니다. 테이블의 총 행 수가 5% 미만입니다.
두 번째 문은 테이블의 통계 데이터를 사용하는 것으로 알고 있습니다. 테이블이 최근에 크게 변경되었고 통계 데이터가 제때 업데이트되지 않은 경우 둘 사이에 큰 차이가 있을 것입니다.
count(*)는 인덱스를 사용합니다. 이는 update_at 필드에 NOT NULL 정의가 있음을 의미합니다. 전체 테이블 스캔에 비해 인덱스 스캔 비용이 더 낮습니다.