
这个目的说来有点不忍启齿....不过抱着解决问题的态度,我还是提了这个问题:
这个是原网页
https://movie.douban.com/tag/%E6%83%85%E8%89%B2?start=0&type=T
这个网页有20个电影,但我抓取的结果只有17个,我调试发现的问题是出在刚开始urlopen.read()就没读全整个网页,不知道是不是因为标签使用不合法导致的没读到。
这是测试的代码:
import sys
import time
import urllib2
import random
import requests
from bs4 import BeautifulSoup
page_num=0
movie_list=[]
try_times = 0
url="https://movie.douban.com/tag/%E6%83%85%E8%89%B2?start="+str(page_num*20)+"&type=T"
time.sleep(random.uniform(1, 2))
try:
source_code = urllib2.urlopen(url).read()
plain_text=str(source_code)
print plain_text
except (urllib2.HTTPError, urllib2.URLError), e:
print e
soup = BeautifulSoup(plain_text)
list_soup=soup.find('p',{'class':['']})
请问该如何解决?并且这个问题的原因到底是什么?
请你们注意,
https://movie.douban.com/tag/%E6%83%85%E8%89%B2?start=0&type=T
这个URL里start也从0开始,第二页是20,第三页是40,以20递增,我自己也数过,每页是有20本电影,但是读取的时候只有17.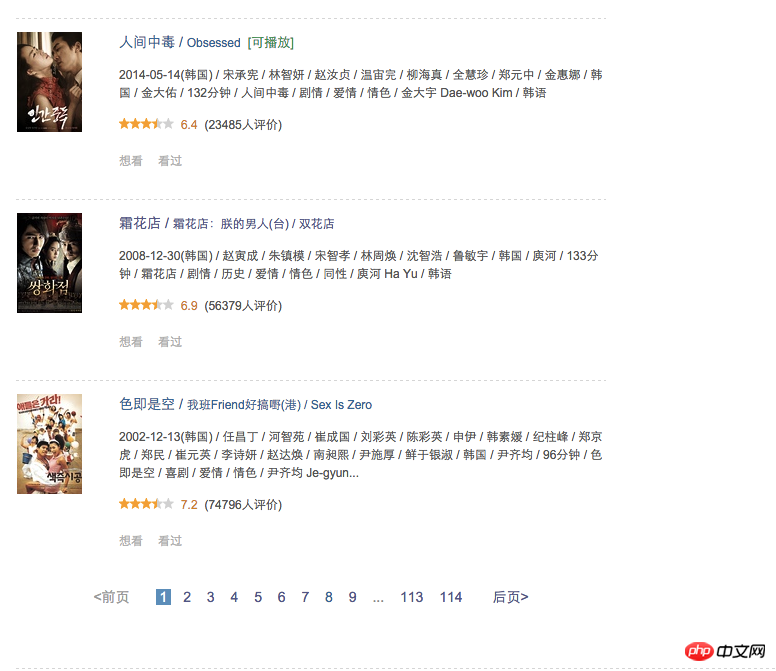















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




이 페이지에는 17개의 영화만 있습니다.
보충:
로그인하지 않은 경우 결과는 17입니다.
로그인하면 결과가 20개 입니다.
이 논리에 따르면 로그인을 시뮬레이션하면 이 문제를 해결할 수 있습니다.
https://movie.douban.com/tag/%E6%83%85%E8%89%B2?start=0&type=T
이 페이지에는 17개의 영화만 있습니다
크롬의 xpath 복사 기능을 이용하여 마지막 영화인 17번째 영화의 xpath를 복사하세요.
//*[@id="content"]/p/p[1]/p[2]/ 테이블 [17]