
根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




으아악
위 오류를 다시 보니
를 발견했습니다. 으아악byte 0xa3이라 터미널에서 여러번 시도해보니 콜론 gb2312 encode
그러므로 Python은 기본 utf-8을 사용하여 gb2312의 본문을 디코딩해야 합니다. 따라서 제가 생각할 수 있는 한 가지 방법은 첫 번째 줄에 있는 명령문인 기본 인코딩 값을 수정하는 것입니다.
# -*- coding: gb2312 -*-그럼 수술 성공인데 다른 방법은 없나요?
파이썬3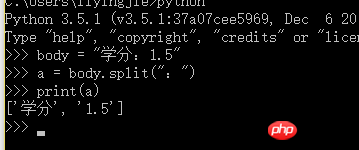
디코딩 후 본문은 유니코드로 인코딩되어야 하며 다음 방법을 사용하세요.
으아악또 다른 인코딩 문제는 인간-컴퓨터 상호 작용을 위한 문자 인코딩 및 5분 안에 Python 문자 인코딩 패배를 참조할 수 있습니다.
으아악