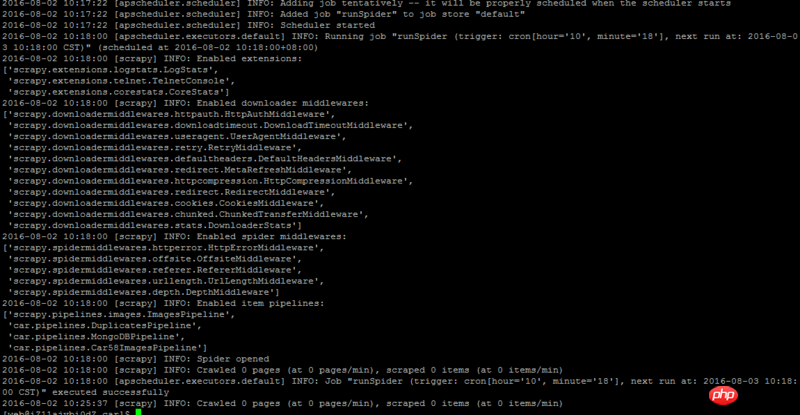
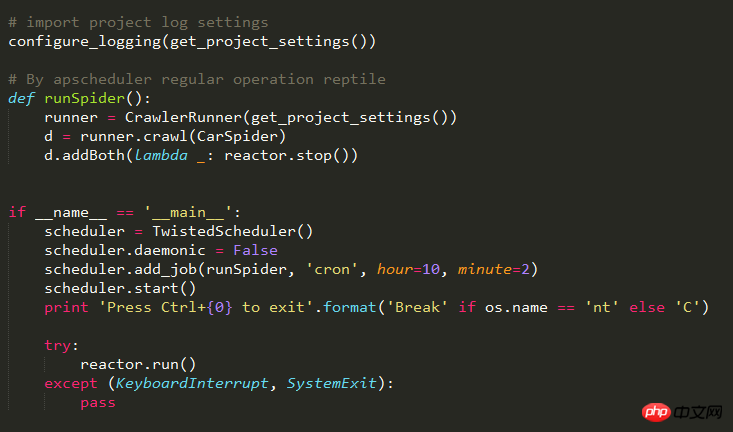
많은 고민과 검색 끝에 마침내 Linux에서 실행하게 되었습니다. 처음 크롤러 작업을 예약했을 때 켜졌으나 웹 페이지를 구문 분석하지 않았습니다. 두 번째로 구문 분석을 시작하고 정상적으로 작동했습니다. 내 추측으로는 React.run()과 관련이 있는 것 같습니다. apscheduler 작업 스케줄링 프레임워크를 Scrapy와 함께 사용할 때는 Twisted 프레임워크에서 사용해야 합니다. 크롤러 작업이 정기적으로 실행될 경우 처음으로 구문 분석이 수행되지 않고 두 번째로 구문 분석됩니다.















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




많은 고민과 검색 끝에 마침내 Linux에서 실행하게 되었습니다. 처음 크롤러 작업을 예약했을 때 켜졌으나 웹 페이지를 구문 분석하지 않았습니다. 두 번째로 구문 분석을 시작하고 정상적으로 작동했습니다. 내 추측으로는 React.run()과 관련이 있는 것 같습니다. apscheduler 작업 스케줄링 프레임워크를 Scrapy와 함께 사용할 때는 Twisted 프레임워크에서 사용해야 합니다. 크롤러 작업이 정기적으로 실행될 경우 처음으로 구문 분석이 수행되지 않고 두 번째로 구문 분석됩니다.