
我在爬取凤凰网却出现
UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position 151120: illegal multibyte sequence
这是我的代码
__author__ = 'my'
import urllib.request
url = 'http://www.ifeng.com/'
req = urllib.request.urlopen(url)
req = req.read()
req = req.decode('utf-8')
print(req)
为什么utf8却报错GBK?














![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




이것은 cmd.exe의 문제이며, 다른 소프트웨어에서는 올바르게 디코딩할 수 있습니다. 예를 들어 메모장, 브라우저. . . .
으아악추가됨:
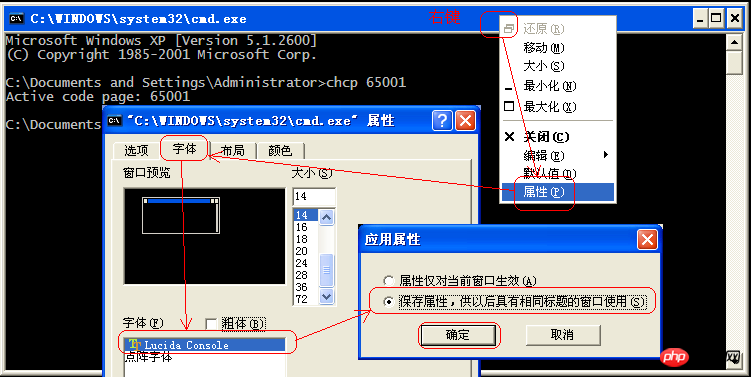
실제로 cmd.exe의 인코딩을 utf-8(cp65001)로 수정할 수도 있습니다.
단계:
1. CMD.exe 실행
2, chcp 65001
3. 창 속성 글꼴 수정
CMD 창 제목 표시줄을 마우스 오른쪽 버튼으로 클릭하고 "속성"->"글꼴"을 선택한 다음 글꼴을 트루타입 글꼴 "Lucida Console"로 변경합니다
표시된 바와 같이:
4. 파이썬 실행
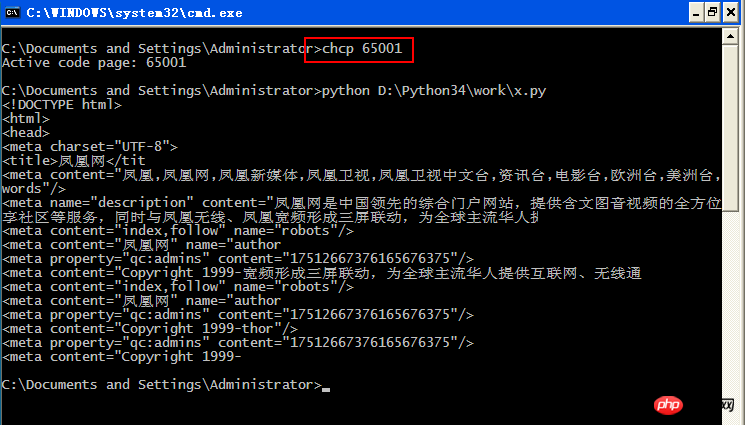
x.py의 내용:
으아악질문의 코드를 pycharm에 넣었더니 이런 문제는 발생하지 않았습니다. 그런 다음 Windows 명령 프롬프트를 사용하여 한 줄씩 입력했는데 이 문제가 발생했습니다. Windows 명령 프롬프트는 gbk 인코딩을 사용하고 웹 페이지 자체는 인코딩에 utf-8을 사용합니다. 명령줄에서 실행하려면 다음과 같이 작성해야 합니다.
으아악여기
req = req.decode('gbk', 'ignore')설명하겠습니다. Windows 명령 프롬프트에 표시하려면 gbk로 디코딩해야 하지만 utf-8 자체의 일부 문자는 을 사용합니다. >gbk디코딩이 다시 실패하므로 두 번째 매개변수인 ignore가 필요합니다. 이 매개변수는 디코딩할 수 없는 문자를 삭제한다는 의미입니다.여담으로, 인코딩에서도 이 문제가 발생할 수 있습니다. 예를 들어 요청 라이브러리를 사용하여 요청하면 바이트 유형 대신 요청된 문자열이 됩니다. 인코딩에 문제가 발생하면 str을 사용할 수도 있습니다. .encode('encoding', 'ingore').decode('decoding') 유사한 문제를 해결합니다.
이해가 안 되시면 제 블로그를 읽어보세요
주제에 대한 질문에 답변하자면, 일부 웹페이지는 GBK 인코딩을 사용하거나 텍스트가 GBK 및 UTF-8과 모두 호환될 수 있습니다.
시스템의 기본 인코딩은 gbk인 것으로 추정됩니다. 시도해 볼 수 있습니다.
으아악Windows 콘솔을 사용하여 실행하고 있나요? 콘솔의 기본 인코딩은 gbk이기 때문입니다.
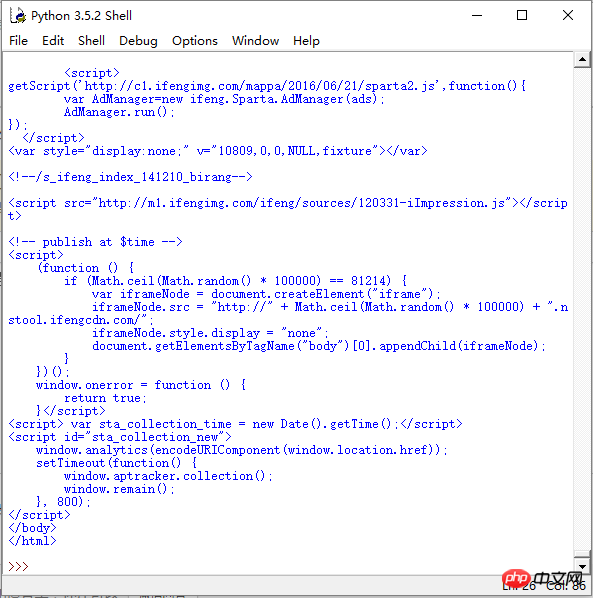
파이썬과 함께 제공되는 인터프리터를 사용해도 괜찮습니다.
아니면 콘솔 대신 다른 도구를 사용해도 됩니다.
으아악# _*_ coding: utf-8 _*_파일 인코딩 지정
프로그램 인코딩을 명시하세요.