- 프런트엔드
- HTML| CSS| JavaScript| Vue.js
최신 권장사항
-

Php8, 나도 갈게
84669인 학습
- 네이티브 파운데이션
- HTML| CSS| HTML5| CSS3| JavaScript
최신 권장사항
-

30분 안에 웹사이트 레이아웃 배우기
152542인 학습
- 기초 소개
- MySQL| SQL Server
최신 권장사항
-

Shangguan Oracle 초보자부터 능숙한 비디오 튜토리얼까지
20005인 학습
최신 권장사항
-

UNI-APP 코드의 첫 번째 줄
5487인 학습
-

처음부터 앱 실행까지 Flutter
7821인 학습

최신 권장사항
-

-

Zero 기본 숙련도 PS 비디오 튜토리얼
180660인 학습
-

시작하는 데 도움이 되는 16일 UI 비디오 튜토리얼
48569인 학습
-

PS 기술 및 슬라이싱 기술 비디오 튜토리얼
18603인 학습
최신 권장사항
-

Alibaba Cloud 환경 구축 및 프로젝트 출시 비디오 튜토리얼
40936인 학습
-

컴퓨터 네트워크 개요 - 프로그래머가 마스터해야 하는 기본 지식
1549인 학습
-

프로그래머를 위한 필수 튜토리얼 - HTTP 프로토콜 설명
1183인 학습
-

웹소켓 비디오 튜토리얼
32909인 학습















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




일반적인 GC 알고리즘
참조 횟수
마크-클리어
세대별 수집
Python의 메모리 관리
CPython에서는 대부분의 개체의 수명 주기가 개체의 참조 카운트를 통해 관리됩니다. 참조 카운팅은 다른 주류 GC 알고리즘과 비교할 때 가장 직관적이고 간단한 가비지 컬렉션 카운트이며, 가장 큰 장점은 실시간 성능입니다. 즉, 참조가 없는 메모리는 즉시 재활용됩니다.
그러나 참조 카운팅에는 두 가지 골치 아픈 결함이 있습니다.
프로그램에서 순환 참조가 발생하면 참조 카운트가 이를 감지할 수 없으며, 순환에서 참조하는 메모리 개체는 재활용할 수 없는 메모리가 되어 메모리 누수가 발생합니다. 예:으아악
은 두 번째 줄이 실행된 후
메모리 객체가 참조되거나 참조가 파괴될 때마다 참조 횟수를 수정해야 합니다. 이러한 유형의 작업을list1의 GC가 2가 됩니다.list1작업이 실행된 후del의 참조 횟수는 1이 되며 0으로 재설정되지 않습니다. . , list1의 메모리 공간이 해제되지 않아 메모리 누수가 발생합니다.list1참조 횟수를 유지하려면 추가 작업이 필요합니다.이라고 합니다. 참조 횟수
footprint가 매우 높아 프로그램 전체 성능에 큰 영향을 미칩니다.footprint순환 참조 문제를 해결하기 위해 CPython은
GC module모듈을 특별히 설계했습니다. 이 모듈의 주요 기능은 순환 참조가 있는 가비지 객체를 확인하고 지우는 것입니다. 이 모듈을 구현하면 실제로 앞서 언급한 두 가지 주요 가비지 수집 기술인 마크 지우기와 세대별 수집이 도입됩니다.참조 카운팅의 성능 문제를 해결하고 메모리 할당 및 해제에서 최고의 효율성을 얻기 위해 Python은 또한 다수의 메모리 풀 메커니즘을 설계했습니다.
Python의 가비지 수집은 참조 계산 방법을 사용합니다. 참조 계산의 원리는 다음 Python 할당자 수준에서 확인할 수 있습니다.
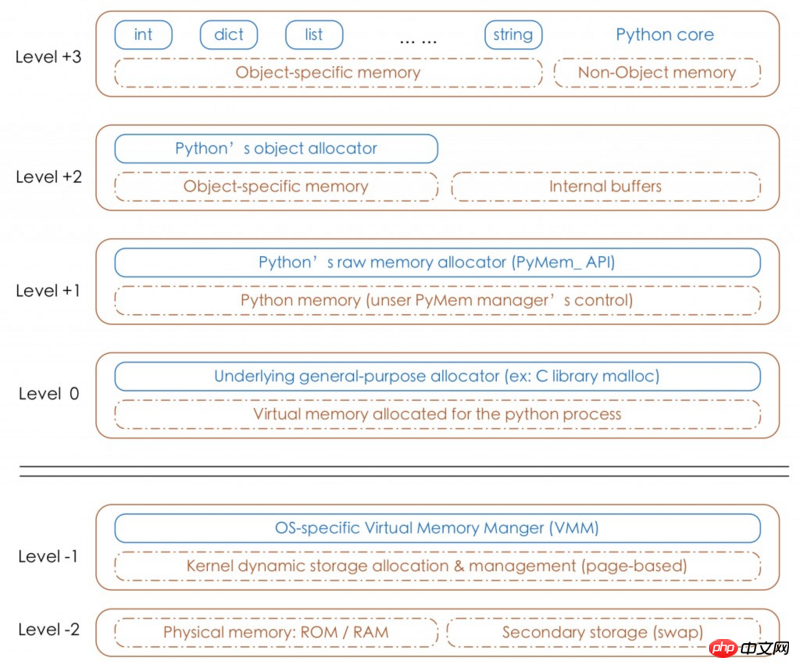
사실 참조 계산뿐만 아니라 마크 스윕 및 세대별 재활용도 이 블로그 게시물에 잘 요약되어 있습니다.
http://hbprotoss.github.io/po...
Python GC는 주로 참조 카운팅을 사용하여 가비지를 추적하고 재활용합니다. 참조 카운팅을 기반으로 컨테이너 객체에서 발생할 수 있는 순환 참조 문제를 해결하기 위해 "마크 앤 스윕"을 사용하고, 시간과 공간을 교환하여 가비지 수집 효율성을 향상시키기 위해 "세대별 수집"을 사용합니다.
참조 횟수 1개
PyObject는
ob_refcnt가 참조 횟수로 사용되는 모든 객체에 필수 콘텐츠입니다. 객체에 새로운 참조가 있으면 해당ob_refcnt이 증가하고, 이를 참조하는 객체가 삭제되면 해당ob_refcnt이 감소합니다. 참조 횟수가 0에 도달하면 객체의 수명이 종료됩니다.장점:
간단
실시간
단점:
참조 카운팅을 유지하면 리소스가 소모됩니다
참고자료
2 마크 클리어 메커니즘
기본 아이디어는 요청 시 먼저 할당하고 여유 메모리가 없을 때 프로그램 스택의 레지스터와 참조에서 시작하여 노드인 객체와 에지인 참조로 구성된 그래프를 순회하고 접근 가능한 모든 객체를 표시하는 것입니다. , 그런 다음 메모리 공간을 정리하고 표시되지 않은 모든 개체를 해제합니다.
3세대 기술
세대별 재활용의 전반적인 아이디어는 시스템의 모든 메모리 블록을 생존 시간에 따라 서로 다른 컬렉션으로 나누는 것입니다. 각 컬렉션은 "세대"의 생존 시간에 따라 가비지 컬렉션 빈도가 증가합니다. 세대". 증가하고 감소하며, 생존 시간은 일반적으로 얼마나 많은 가비지 수집이 필요한지 측정됩니다.
Python은 기본적으로 3세대 객체 컬렉션을 정의합니다. 인덱스 번호가 클수록 객체 생존 시간이 길어집니다.