
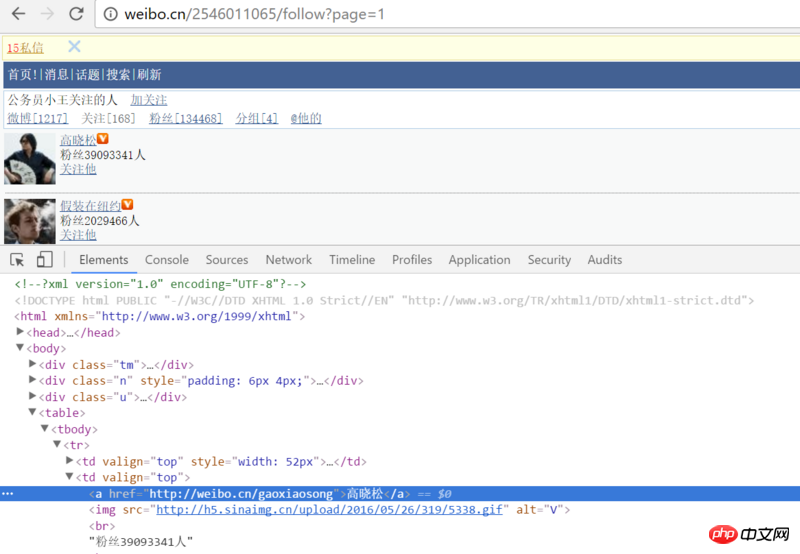
第一次用xpath写的爬虫,想获取某人关注列表的每位博主的昵称,但是用下面的代码得到的li永远是空的,为什么捏?
for i in range(1, pagenum + 1):
urli = "http://weibo.cn/%d/follow?page=%d"%(uid,i)
html_sample = requests.get(urli, cookies=cookie).content
# 使用xpath获取所有昵称
selector = etree.HTML(html_sample)
list = selector.xpath('//table/tbody/tr/td[2]/a[1]/text()')
for li in list:
print nums,li
nums += 1













![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




해당 페이지의 소스코드를 열어서 살펴보면, 캡쳐한 스크린샷과 구조가 살짝 다른 것을 알 수 있는데요,
으아악BeautifulSoup을 사용하는 것도 매우 편리합니다
으아악