&a 결과는 배열에 대한 포인터가 되므로 &a+1은 실제로 배열의 길이에 따라 이동합니다. 배열의 두 번째 요소만 가져오려면 *(&a[0]+1)을 사용하세요. &a[0]의 데이터 유형이 int*이기 때문입니다. 먼저 그림을 그립니다:
다음과 같은 배열이 있다고 가정합니다
으아아아
위 프로그램을 컴파일하고 전달할 수 있지만 x와 a의 유형이 일치하지 않기 때문에 컴파일러에서 경고를 표시합니다.
1. 강제형 변환을 통해
으아아아
2. &a의 유형은 int (*)[5]
입니다.
으아아아
여기에는 적절한 데이터 유형을 작성하는 방법이 포함되며 이는 할당 및 매개변수 전달에서 매우 중요합니다!
그러므로 먼저 a, &a 및 &a[0]의 데이터 유형을 요약해야 합니다.
a는 배열의 첫 번째 요소에 대한 포인터인 배열의 이름입니다. 여기서 배열의 첫 번째 요소의 데이터 유형은 int이므로 의심의 여지가 없습니다. a의 데이터 유형은 int*입니다.
&a는 1차원 배열의 주소를 취하고 결과는 배열에 대한 포인터(이 경우 int 배열에 대한 포인터), 즉
int(*)[5입니다. ] .
&a[0]은 매우 간단합니다. 먼저 a[0]은 정수 int를 가져온 다음 해당 주소를 가져오므로 해당 데이터 유형은
int*입니다.
이제 데이터 유형을 알았으니 포인터 연산이 훨씬 더 명확해졌습니다!
먼저 강제 유형 변환을 통과한 코드 부분을 살펴보세요. 어떤 숫자가 출력될까요?
정답은 5입니다!
지금까지의 데이터 유형 요약을 통해 &a의 데이터 유형이
int (*)[5]임을 알 수 있으므로 &a+1은 실제로 5*sizeof(int)바이트만큼 이동했습니다.
이제 포인터는 배열의 마지막 요소(그림 1) 뒤의 요소를 가리킵니다. 즉, 경계를 넘었습니다! 하지만 x의 데이터 유형은 실제로 int *이기 때문에
따라서 x-1의 경우 실제로 1*sizeof(int) 바이트만큼 왼쪽으로 이동합니다. 이는 마지막 요소를 가리킨다는 의미이므로 *(x-1)을 얻습니다.
값은 배열의 마지막 요소입니다: 5
자, 이제 두 번째 부분을 살펴보겠습니다. 어떤 숫자가 출력될까요? 대답에 대해 먼저 이야기하지 말자. 방금 여기서 말했다.
데이터 유형
Sizeof(int)*5바이트가 단위로 이동하므로 실제로는 x-1이 sizeof(int)*5바이트만큼 왼쪽으로 이동됩니다.
20바이트, 이는 배열의 첫 번째 요소로 돌아가므로 답은 다음과 같습니다. 1
위는 1차원 배열입니다. 이제 2차원 배열의 상황에 대해 이야기하고 싶습니다. 으아악
먼저 a, a[0], &a, &a[0], &a[0][0]의 데이터 유형을 살펴보겠습니다.
위의 굵은 텍스트에 주의하세요. 배열 이름은 배열의 첫 번째 요소에 대한 포인터입니다!
a의 데이터 유형은 무엇입니까? ? int *? 아니요, 이 굵은 텍스트의 핵심은 다섯 단어 첫 번째 요소입니다.
a의 첫 번째 요소는 단지 a[0][0]이 아닌가? 엄밀히 말하면, 아니, a의 첫 번째 요소는 실제로 a[0]인데, a[0]의 데이터 유형은 무엇입니까? 에[0]
은 세 개의 int 요소를 포함하는 배열이므로 a[0]의 유형은 첫 번째 요소의 데이터 유형이므로 int t[3]의 t 유형과 동일합니다. ~이다
int*, 이 2차원 배열을 1차원 배열로 간주하면 실제로는 세 개의 int* 요소를 포함하는 배열입니다.
배열은 포인터의 배열이므로 a의 데이터 유형은 int (*)[3]입니다.
&a를 다시 살펴보겠습니다. 1차원 배열에 대해 이야기할 때 언급했듯이 배열 이름의 주소를 가져와 얻은 주소는 배열에 대한 포인터이므로 &a의 데이터 유형은
입니다. int (*)[3] [3]
&a[0] 조금 괴로운 것 같지만 이전 단락에서 언급했듯이 a[0]은 세 개의 int 요소를 포함하는 배열이고
int t[3]
t의 데이터 유형은 int*입니다. 당연히 &a[0]의 데이터 유형은 &t의 데이터 유형, 즉 int(*)와 같습니다. [3]
이제 2차원 배열의 데이터 유형에 대해 거의 다 썼습니다. 이제 데이터 유형을 알았으니 계산 후 포인터가 어디로 이동할지 정확하게 알 수 있습니다!
다음 코드를 살펴보세요.
으아악
x의 데이터 유형은
int (*)[3]
이므로 그림에 표시된 대로 x+1은 실제로 3*sizeof(int) 바이트만큼 이동됩니다.
k의 데이터 유형은
int *
이므로 k+1은 실제로 sizeof(int)바이트만큼 이동됩니다.
y의 데이터 유형은
int입니다.
(*)[3][3]
, 따라서 y+1은 실제로 3*3*sizeof(int) 바이트만큼 이동합니다. 이는 배열의 마지막 바이트입니다.
요소 다음의 요소입니다. 그림과 같이:
q의 데이터 유형은
int (*)[3]
이므로 q+1은 실제로 3*sizeof(int) 바이트만큼 이동됩니다.
z의 데이터 유형은
int *
이므로 z+1은 실제로 sizeof(int)바이트만큼 이동됩니다.
그래서 배열 포인터를 더하고 뺄 때 가장 중요한 것은 스텝 크기를 아는 것이고, 스텝 크기는 데이터 유형에 따라 결정됩니다!
오래된 글을 다시 올려서 죄송합니다. 우연히 보게 된 이유는 예전에 임베디드 프로그래밍을 할 때 포인터 변수에 메모리 주소를 직접 할당하는 것을 포함하여 배열과 포인터를 자주 사용했는데(일반적으로 일반 응용 프로그램에서는 사용하지 않음) &arr를 발견한 적이 없었기 때문입니다. arr과의 차이점은 무엇입니까? 오늘 구체적으로 확인해보니 이것이 컴파일러에 따라 다르다는 것을 알았습니다. 일부 컴파일러는 배열과 포인터를 별도로 취급합니다. 배열 이름에 대한 주소를 취하는 것은 전체 배열 메모리에 대한 것입니다. 일부 컴파일러는 배열을 포인터의 특정 형태로 간주합니다. 배열 요소이지만 전체 배열 메모리와 같은 것은 없습니다.
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




&a 결과는 배열에 대한 포인터가 되므로 &a+1은 실제로 배열의 길이에 따라 이동합니다. 배열의 두 번째 요소만 가져오려면 *(&a[0]+1)을 사용하세요. &a[0]의 데이터 유형이 int*이기 때문입니다. 먼저 그림을 그립니다: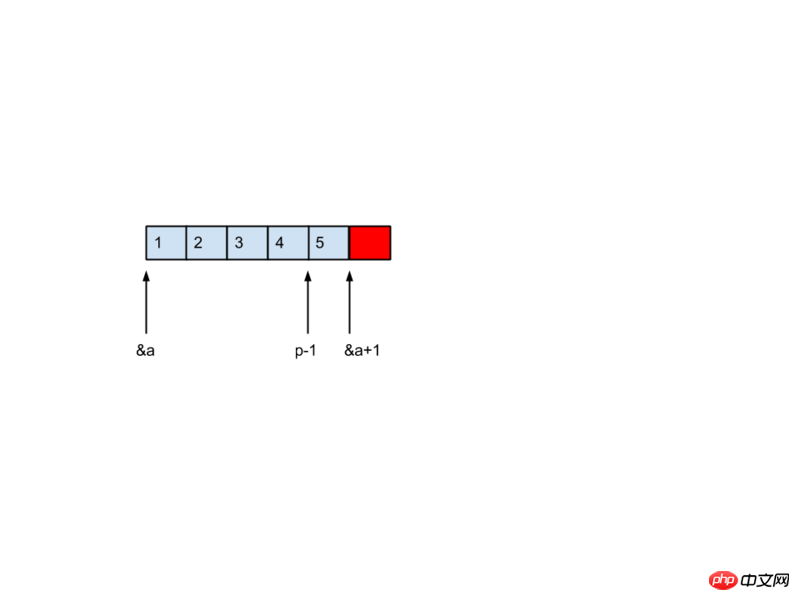
다음과 같은 배열이 있다고 가정합니다
으아아아위 프로그램을 컴파일하고 전달할 수 있지만 x와 a의 유형이 일치하지 않기 때문에 컴파일러에서 경고를 표시합니다.
1. 강제형 변환을 통해
으아아아2. &a의 유형은 int (*)[5]
입니다. 으아아아여기에는 적절한 데이터 유형을 작성하는 방법이 포함되며 이는 할당 및 매개변수 전달에서 매우 중요합니다!
그러므로 먼저 a, &a 및 &a[0]의 데이터 유형을 요약해야 합니다.
-
- &a는 1차원 배열의 주소를 취하고 결과는 배열에 대한 포인터(이 경우 int 배열에 대한 포인터), 즉
- &a[0]은 매우 간단합니다. 먼저 a[0]은 정수 int를 가져온 다음 해당 주소를 가져오므로 해당 데이터 유형은
이제 데이터 유형을 알았으니 포인터 연산이 훨씬 더 명확해졌습니다!a는 배열의 첫 번째 요소에 대한 포인터인 배열의 이름입니다. 여기서 배열의 첫 번째 요소의 데이터 유형은 int이므로 의심의 여지가 없습니다. a의 데이터 유형은 int*입니다.
int(*)[5입니다. ] .
int*입니다.
먼저 강제 유형 변환을 통과한 코드 부분을 살펴보세요. 어떤 숫자가 출력될까요?
정답은 5입니다! 지금까지의 데이터 유형 요약을 통해 &a의 데이터 유형이int (*)[5]임을 알 수 있으므로 &a+1은 실제로 5*sizeof(int)바이트만큼 이동했습니다. 이제 포인터는 배열의 마지막 요소(그림 1) 뒤의 요소를 가리킵니다. 즉, 경계를 넘었습니다! 하지만 x의 데이터 유형은 실제로 int *이기 때문에 따라서 x-1의 경우 실제로 1*sizeof(int) 바이트만큼 왼쪽으로 이동합니다. 이는 마지막 요소를 가리킨다는 의미이므로 *(x-1)을 얻습니다. 값은 배열의 마지막 요소입니다: 5
자, 이제 두 번째 부분을 살펴보겠습니다. 어떤 숫자가 출력될까요? 대답에 대해 먼저 이야기하지 말자. 방금 여기서 말했다. 데이터 유형 Sizeof(int)*5바이트가 단위로 이동하므로 실제로는 x-1이 sizeof(int)*5바이트만큼 왼쪽으로 이동됩니다. 20바이트, 이는 배열의 첫 번째 요소로 돌아가므로 답은 다음과 같습니다. 1먼저 a, a[0], &a, &a[0], &a[0][0]의 데이터 유형을 살펴보겠습니다.
위의 굵은 텍스트에 주의하세요. 배열 이름은 배열의 첫 번째 요소에 대한 포인터입니다!
a의 데이터 유형은 무엇입니까? ? int *? 아니요, 이 굵은 텍스트의 핵심은 다섯 단어 첫 번째 요소입니다. a의 첫 번째 요소는 단지 a[0][0]이 아닌가? 엄밀히 말하면, 아니, a의 첫 번째 요소는 실제로 a[0]인데, a[0]의 데이터 유형은 무엇입니까? 에[0] 은 세 개의 int 요소를 포함하는 배열이므로 a[0]의 유형은 첫 번째 요소의 데이터 유형이므로 int t[3]의 t 유형과 동일합니다. ~이다 int*, 이 2차원 배열을 1차원 배열로 간주하면 실제로는 세 개의 int* 요소를 포함하는 배열입니다. 배열은 포인터의 배열이므로 a의 데이터 유형은 int (*)[3]입니다.
t의 데이터 유형은 int*입니다. 당연히 &a[0]의 데이터 유형은 &t의 데이터 유형, 즉 int(*)와 같습니다. [3]
다음 코드를 살펴보세요.
으아악x의 데이터 유형은- int (*)[3]
k의 데이터 유형은 - int *
y의 데이터 유형은 - int입니다.
(*)[3][3]
q의 데이터 유형은 - int (*)[3]
z의 데이터 유형은 - int *
그래서 배열 포인터를 더하고 뺄 때 가장 중요한 것은 스텝 크기를 아는 것이고, 스텝 크기는 데이터 유형에 따라 결정됩니다!
이므로 그림에 표시된 대로 x+1은 실제로 3*sizeof(int) 바이트만큼 이동됩니다.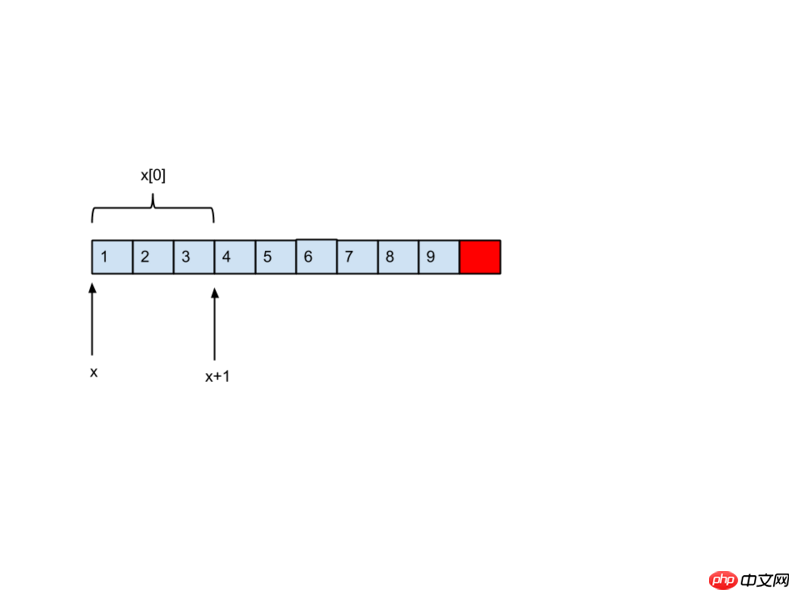
이므로 k+1은 실제로 sizeof(int)바이트만큼 이동됩니다.
, 따라서 y+1은 실제로 3*3*sizeof(int) 바이트만큼 이동합니다. 이는 배열의 마지막 바이트입니다. 요소 다음의 요소입니다. 그림과 같이: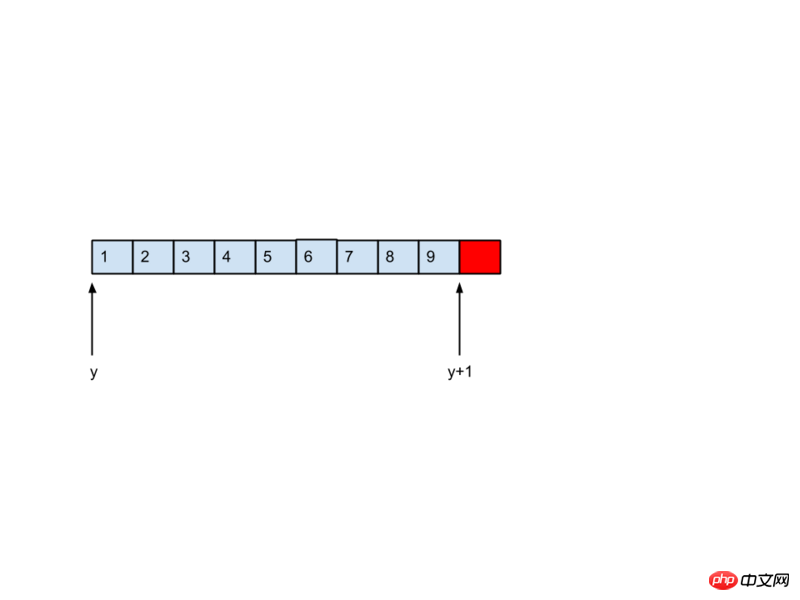
이므로 q+1은 실제로 3*sizeof(int) 바이트만큼 이동됩니다.
이므로 z+1은 실제로 sizeof(int)바이트만큼 이동됩니다.
1층 답변자님이 잘 적어주셨네요. 자세히 설명해주세요
포인터의 값은 배열의 주소입니다
int (* pa)[5];
pa++;pa 20바이트 뒤로 이동(5*4)
대조적으로, 배열의 요소는 포인터입니다(int*)
int *pa[5];
pa++;pa는 4바이트 뒤로 이동합니다
오래된 글을 다시 올려서 죄송합니다. 우연히 보게 된 이유는 예전에 임베디드 프로그래밍을 할 때 포인터 변수에 메모리 주소를 직접 할당하는 것을 포함하여 배열과 포인터를 자주 사용했는데(일반적으로 일반 응용 프로그램에서는 사용하지 않음) &arr를 발견한 적이 없었기 때문입니다. arr과의 차이점은 무엇입니까? 오늘 구체적으로 확인해보니 이것이 컴파일러에 따라 다르다는 것을 알았습니다. 일부 컴파일러는 배열과 포인터를 별도로 취급합니다. 배열 이름에 대한 주소를 취하는 것은 전체 배열 메모리에 대한 것입니다. 일부 컴파일러는 배열을 포인터의 특정 형태로 간주합니다. 배열 요소이지만 전체 배열 메모리와 같은 것은 없습니다.