

hive分区(partition)简介

网上有篇关于hive的partition的使用讲解的比较好,转载了: 一、背景 1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。 2、分区表指的是在创建表时指定
网上有篇关于hive的partition的使用讲解的比较好,转载了:
一、背景
1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、分区表指的是在创建表时指定的partition的分区空间。
3、如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
二、技术细节
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、表和列名不区分大小写。
3、分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table day_table (id int, content string) partitioned by (dt string);单分区表,按天分区,在表结构中存在id,content,dt三列。
b、双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
表文件夹目录示意图(多分区表):
6、添加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: : PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08') location '/path/pv1.txt' PARTITION (dt='2008-08-08', hour='09') location '/path/pv2.txt';
7、删除分区语法:
ALTER TABLE table_name DROP partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');
8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
LOAD DATA INPATH '/user/pv.txt' INTO TABLE day_hour_table PARTITION(dt='2008-08- 08', hour='08'); LOAD DATA local INPATH '/user/hua/*' INTO TABLE day_hour partition(dt='2010-07- 07');
当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。
9、基于分区的查询的语句:
SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';
10、查看分区语句:
hive> show partitions day_hour_table; OK dt=2008-08-08/hour=08 dt=2008-08-08/hour=09 dt=2008-08-09/hour=09
三、总结
1、在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在最字集的目录中。
2、总的说来partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
——————————————————————————————————————
hive中关于partition的操作:
hive> create table mp (a string) partitioned by (b string, c string);
OK
Time taken: 0.044 seconds
hive> alter table mp add partition (b='1', c='1');
OK
Time taken: 0.079 seconds
hive> alter table mp add partition (b='1', c='2');
OK
Time taken: 0.052 seconds
hive> alter table mp add partition (b='2', c='2');
OK
Time taken: 0.056 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.046 seconds
hive> explain extended alter table mp drop partition (b='1');
OK
ABSTRACT SYNTAX TREE:
(TOK_ALTERTABLE_DROPPARTS mp (TOK_PARTSPEC (TOK_PARTVAL b '1')))
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Drop Table Operator:
Drop Table
table: mp
Time taken: 0.048 seconds
hive> alter table mp drop partition (b='1');
FAILED: Error in metadata: table is partitioned but partition spec is not specified or tab: {b=1}
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.044 seconds
hive> alter table mp add partition ( b='1', c = '3') partition ( b='1' , c='4');
OK
Time taken: 0.168 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=1/c=3
b=1/c=4
b=2/c=2
b=2/c=3
Time taken: 0.066 seconds
hive>insert overwrite table mp partition (b='1', c='1') select cnt from tmp_et3 ;
hive>alter table mp add columns (newcol string);
location指定目录结构
hive> alter table alter2 add partition (insertdate='2008-01-01') location '2008/01/01';
hive> alter table alter2 add partition (insertdate='2008-01-02') location '2008/01/02';

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

![[Sistem Linux] arahan partition berkaitan fdisk.](https://img.php.cn/upload/article/000/887/227/170833682614236.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Sistem Linux] arahan partition berkaitan fdisk.
Feb 19, 2024 pm 06:00 PM
[Sistem Linux] arahan partition berkaitan fdisk.
Feb 19, 2024 pm 06:00 PM
fdisk ialah alat baris arahan Linux yang biasa digunakan untuk mencipta, mengurus dan mengubah suai partition cakera. Berikut adalah beberapa arahan fdisk yang biasa digunakan: Paparkan maklumat partition cakera: fdisk-l Perintah ini akan memaparkan maklumat partition semua cakera dalam sistem. Pilih cakera yang anda mahu kendalikan: fdisk/dev/sdX Gantikan /dev/sdX dengan nama peranti cakera sebenar yang anda mahu kendalikan, seperti /dev/sda. Cipta partition baharu:nIni akan membimbing anda untuk mencipta partition baharu. Ikuti arahan untuk memasukkan jenis partition, sektor permulaan, saiz dan maklumat lain. Padam Partition:d Ini akan membimbing anda untuk memilih partition yang anda ingin padamkan. Ikut gesaan untuk memilih nombor partition yang hendak dipadamkan. Ubah Suai Jenis Partition: Ini akan membimbing anda untuk memilih partition yang anda ingin ubah suai jenisnya. Mengikut sebutan
 Penyelesaian kepada masalah tidak dapat membahagikan selepas pemasangan win10
Jan 02, 2024 am 09:17 AM
Penyelesaian kepada masalah tidak dapat membahagikan selepas pemasangan win10
Jan 02, 2024 am 09:17 AM
Apabila kami memasang semula sistem pengendalian win10, apabila ia datang ke langkah pembahagian cakera, kami mendapati bahawa sistem menggesa bahawa partition baharu tidak boleh dibuat dan partition sedia ada tidak dapat ditemui. Dalam kes ini, saya fikir anda boleh cuba memformat semula keseluruhan cakera keras dan memasang semula sistem ke partition, atau memasang semula sistem melalui perisian, dsb. Mari lihat bagaimana editor melakukannya untuk kandungan tertentu~ Saya harap ia dapat membantu anda. Apa yang perlu dilakukan jika anda tidak boleh membuat partition baru selepas memasang win10 Kaedah 1: Formatkan keseluruhan cakera keras dan partisi semula atau cuba pasang dan cabut palam pemacu kilat USB beberapa kali dan muat semula jika tiada data penting pada cakera keras anda , apabila ia datang kepada langkah pembahagian, padamkan semua data pada cakera keras Pembahagian telah dipadamkan. Format semula keseluruhan cakera keras, kemudian partisi semula, dan kemudian pasangkannya seperti biasa. Kaedah 2: P
 Penanda Aras Prestasi ORM Python: Membandingkan Rangka Kerja ORM Berbeza
Mar 18, 2024 am 09:10 AM
Penanda Aras Prestasi ORM Python: Membandingkan Rangka Kerja ORM Berbeza
Mar 18, 2024 am 09:10 AM
Rangka kerja pemetaan hubungan objek (ORM) memainkan peranan penting dalam pembangunan ular sawa, ia memudahkan akses dan pengurusan data dengan membina jambatan antara objek dan pangkalan data hubungan. Untuk menilai prestasi rangka kerja ORM yang berbeza, artikel ini akan menanda aras terhadap rangka kerja popular berikut: sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM Kaedah Ujian Penanda aras menggunakan pangkalan data SQLite yang mengandungi 1 juta rekod. Ujian melakukan operasi berikut pada pangkalan data: Masukkan: Masukkan 10,000 rekod baharu ke dalam jadual Baca: Baca semua rekod dalam jadual Kemas kini: Kemas kini satu medan untuk semua rekod dalam jadual Padam: Padam semua rekod dalam jadual Setiap operasi
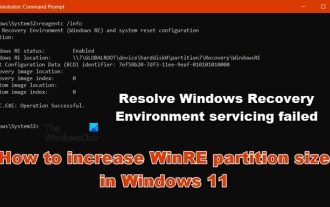 Bagaimana untuk meningkatkan saiz partition WinRE dalam Windows 11
Feb 19, 2024 pm 06:06 PM
Bagaimana untuk meningkatkan saiz partition WinRE dalam Windows 11
Feb 19, 2024 pm 06:06 PM
Dalam artikel ini, kami akan menunjukkan kepada anda cara menukar atau meningkatkan saiz partition WinRE dalam Windows 11/10. Microsoft kini akan mengemas kini Persekitaran Pemulihan Windows (WinRE) bersama kemas kini terkumpul bulanan, bermula dengan Windows 11 versi 22H2. Walau bagaimanapun, tidak semua komputer mempunyai partition pemulihan yang cukup besar untuk menampung kemas kini baharu, yang boleh menyebabkan mesej ralat muncul. Perkhidmatan Persekitaran Pemulihan Windows Gagal Cara Meningkatkan Saiz Partition WinRE dalam Windows 11 Untuk meningkatkan saiz partition WinRE secara manual pada komputer anda, ikut langkah yang dinyatakan di bawah. Semak dan lumpuhkan partition WinRE Shrink OS Cipta partition pemulihan baharu Sahkan partition dan dayakan WinRE
 Penjelasan terperinci tentang cara menyediakan partition Linux Opt
Mar 20, 2024 am 11:30 AM
Penjelasan terperinci tentang cara menyediakan partition Linux Opt
Mar 20, 2024 am 11:30 AM
Cara menyediakan contoh partition dan kod Linux Opt Dalam sistem Linux, partition Opt biasanya digunakan untuk menyimpan pakej perisian pilihan dan data aplikasi. Menetapkan partition Opt dengan betul boleh mengurus sumber sistem dengan berkesan dan mengelakkan masalah seperti ruang cakera yang tidak mencukupi. Artikel ini akan memperincikan cara menyediakan partition LinuxOpt dan memberikan contoh kod khusus. 1. Tentukan saiz ruang partition Pertama, kita perlu menentukan saiz ruang yang diperlukan untuk partition Opt. Secara amnya disyorkan untuk menetapkan saiz partition Opt kepada 5%-1 daripada jumlah ruang sistem.
 Bagaimana untuk membahagikan cakera keras dalam Win11? Tutorial cara membahagikan cakera keras dalam cakera win11
Feb 19, 2024 pm 06:01 PM
Bagaimana untuk membahagikan cakera keras dalam Win11? Tutorial cara membahagikan cakera keras dalam cakera win11
Feb 19, 2024 pm 06:01 PM
Ramai pengguna merasakan bahawa ruang partition lalai sistem terlalu kecil, jadi bagaimana untuk membahagikan cakera keras dalam Win11? Pengguna boleh terus klik pada pengurusan di bawah komputer ini, dan kemudian klik pada pengurusan cakera untuk melaksanakan tetapan operasi. Biarkan tapak ini memberi pengguna tutorial terperinci tentang cara membahagikan cakera keras dalam Win11. Tutorial cara membahagikan cakera keras dalam win11 1. Pertama, klik kanan komputer ini dan buka Pengurusan Komputer. 3. Kemudian semak status cakera di sebelah kanan untuk melihat sama ada terdapat ruang yang tersedia. (Jika ada ruang kosong, langkau ke langkah 6). 5. Kemudian pilih jumlah ruang yang anda perlukan untuk mengosongkan dan klik Compress. 7. Masukkan saiz volum mudah yang dikehendaki dan klik Seterusnya. 9. Akhir sekali, klik Selesai untuk mencipta partition baharu.
 Aplikasi Python ORM dalam projek data besar
Mar 18, 2024 am 09:19 AM
Aplikasi Python ORM dalam projek data besar
Mar 18, 2024 am 09:19 AM
Pemetaan hubungan objek (ORM) ialah teknologi pengaturcaraan yang membolehkan pembangun menggunakan bahasa pengaturcaraan objek untuk memanipulasi pangkalan data tanpa menulis pertanyaan SQL secara langsung. Alat ORM dalam python (seperti SQLAlchemy, Peewee dan DjangoORM) memudahkan interaksi pangkalan data untuk projek data besar. Kelebihan Kesederhanaan Kod: ORM menghapuskan keperluan untuk menulis pertanyaan SQL yang panjang, yang meningkatkan kesederhanaan dan kebolehbacaan kod. Abstraksi data: ORM menyediakan lapisan abstraksi yang mengasingkan kod aplikasi daripada butiran pelaksanaan pangkalan data, meningkatkan fleksibiliti. Pengoptimuman prestasi: ORM sering menggunakan operasi caching dan kelompok untuk mengoptimumkan pertanyaan pangkalan data, dengan itu meningkatkan prestasi. Mudah alih: ORM membenarkan pembangun untuk
 Bagaimana untuk membahagikan cakera
Feb 25, 2024 pm 03:33 PM
Bagaimana untuk membahagikan cakera
Feb 25, 2024 pm 03:33 PM
Bagaimana untuk membahagikan pengurusan cakera Dengan perkembangan teknologi komputer yang berterusan, pengurusan cakera telah menjadi bahagian yang sangat diperlukan dalam penggunaan komputer kita. Sebagai bahagian penting dalam pengurusan cakera, pembahagian cakera boleh membahagikan cakera keras kepada beberapa bahagian, membolehkan kami menyimpan dan mengurus data dengan lebih fleksibel. Jadi, bagaimana untuk membahagikan pengurusan cakera? Di bawah, saya akan memberi anda pengenalan terperinci. Pertama sekali, kita perlu menjelaskan bahawa tidak hanya ada satu cara untuk membahagikan cakera Kita boleh memilih kaedah pembahagian cakera yang sesuai mengikut keperluan dan tujuan yang berbeza. selalunya
