

Oracle压缩功能小结2—预估表压缩的效果

在使用压缩之前,我们可以估算一下使用压缩能够拥有多大的效果。 11gr2以前可以使用dbms_comp_advisor,具体代码已经在附件中给出。只需要执行两个文件dbmscomp.sql和prvtcomp.plb,然后使用DBMS_COMP_ADVISOR.getratio存储过程即可。不再详细描述。 SQL set
在使用压缩之前,我们可以估算一下使用压缩能够拥有多大的效果。
11gr2以前可以使用dbms_comp_advisor,具体代码已经在附件中给出。只需要执行两个文件dbmscomp.sql和prvtcomp.plb,然后使用DBMS_COMP_ADVISOR.getratio存储过程即可。不再详细描述。
SQL> set serveroutput on
SQL> execdbms_comp_advisor.getratio('SH','SALES',10)
Sampling table: SH.SALES
Sampling percentage: 10%
Estimated compression ratio for the advancedcompression option is : 2.9611gr2以后系统会自带一个dbms_compression的包,用来代替dbms_comp_advisor提供服务。
_sys@FAKE> desc dbms_compression PROCEDURE GET_COMPRESSION_RATIO ArgumentName Type In/Out Default? ----------------------------------------------------- ------ -------- SCRATCHTBSNAME VARCHAR2 IN OWNNAME VARCHAR2 IN TABNAME VARCHAR2 IN PARTNAME VARCHAR2 IN COMPTYPE NUMBER IN BLKCNT_CMP BINARY_INTEGER OUT BLKCNT_UNCMP BINARY_INTEGER OUT ROW_CMP BINARY_INTEGER OUT ROW_UNCMP BINARY_INTEGER OUT CMP_RATIO NUMBER OUT COMPTYPE_STR VARCHAR2 OUT SUBSET_NUMROWS NUMBER IN DEFAULT FUNCTION GET_COMPRESSION_TYPE RETURNS NUMBER ArgumentName Type In/Out Default? ----------------------------------------------------- ------ -------- OWNNAME VARCHAR2 IN TABNAME VARCHAR2 IN ROW_ID ROWID IN PROCEDURE INCREMENTAL_COMPRESS ArgumentName Type In/Out Default? ----------------------------------------------------- ------ -------- OWNNAME VARCHAR2(30) IN TABNAME VARCHAR2(128) IN PARTNAME VARCHAR2(30) IN COLNAME VARCHAR2 IN DUMP_ON NUMBER IN DEFAULT AUTOCOMPRESS_ON NUMBER IN DEFAULT WHERE_CLAUSE VARCHAR2 IN DEFAULT
重点看GET_COMPRESSION_RATIO这个存储过程,它可以预估表的压缩比例。
可以使用以下的匿名块执行。
DECLARE
blkcnt_comp PLS_INTEGER;
blkcnt_uncm PLS_INTEGER;
row_comp PLS_INTEGER;
row_uncm PLS_INTEGER;
comp_ratio number;
comp_type VARCHAR2(30);
username varchar2(30) := '&USER';
tablename varchar2(30) := '&TB' ;
BEGIN
dbms_compression.get_compression_ratio('&Usedtbs',
username,
tablename,
NULL,
dbms_compression.COMP_FOR_OLTP,
blkcnt_comp,
blkcnt_uncm,
row_comp,
row_uncm,
comp_ratio,
comp_type);
dbms_output.put_line('Sampling table: '||username||'.'||tablename);
dbms_output.put_line('Estimated compression ratio: ' ||TO_CHAR(comp_ratio));
dbms_output.put_line('Compression Type: ' || comp_type);
END;
/执行效果:
/
Enter value for user: DEXTER
old 8: username varchar2(30) :='&USER';
new 8: username varchar2(30) :='DEXTER';
Enter value for tb: ACCOUNT
old 9: tablename varchar2(30) :='&TB' ;
new 9: tablename varchar2(30) :='ACCOUNT' ;
Enter value for usedtbs: USERS
old 11: dbms_compression.get_compression_ratio('&Usedtbs',
new 11: dbms_compression.get_compression_ratio('USERS',
Sampling table: DEXTER.ACCOUNT
Estimated compression ratio: 1
Compression Type: "Compress For OLTP"
PL/SQL procedure successfully completed.
因为表中的重复值非常少,上文中Estimated compression ratio: 1,表示没有任何压缩效果。
高级压缩,基于块内的压缩。所以就算有重复值,但是没有在一个块中,那么高级压缩还是无法起作用。
这里重点介绍一个参数 COMPTYPE,它一共有6个选项,分别是
COMP_NOCOMPRESS CONSTANT NUMBER := 1; COMP_FOR_OLTP CONSTANT NUMBER := 2; COMP_FOR_QUERY_HIGH CONSTANT NUMBER := 4; COMP_FOR_QUERY_LOW CONSTANT NUMBER := 8; COMP_FOR_ARCHIVE_HIGH CONSTANT NUMBER := 16; COMP_FOR_ARCHIVE_LOW CONSTANT NUMBER := 32;
Query high 以下都是HCC(HybridColumnar Compression)的内容,因为与Exadata的存储节点相关,所以在非Exadata一体机环境无法使用。不过有意思的是,你可以在普通环境下使用get_compression_ratio来预估压缩的比例。
11gr2以前compression-advisor存储过程下载地址:
http://download.csdn.net/detail/renfengjun/7514723

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Berapa lama log pangkalan data Oracle akan disimpan?
May 10, 2024 am 03:27 AM
Berapa lama log pangkalan data Oracle akan disimpan?
May 10, 2024 am 03:27 AM
Tempoh pengekalan log pangkalan data Oracle bergantung pada jenis log dan konfigurasi, termasuk: Buat semula log: ditentukan oleh saiz maksimum yang dikonfigurasikan dengan parameter "LOG_ARCHIVE_DEST". Log buat semula yang diarkibkan: Ditentukan oleh saiz maksimum yang dikonfigurasikan oleh parameter "DB_RECOVERY_FILE_DEST_SIZE". Log buat semula dalam talian: tidak diarkibkan, hilang apabila pangkalan data dimulakan semula dan tempoh pengekalan adalah konsisten dengan masa berjalan contoh. Log audit: Dikonfigurasikan oleh parameter "AUDIT_TRAIL", dikekalkan selama 30 hari secara lalai.
 Urutan langkah permulaan pangkalan data oracle ialah
May 10, 2024 am 01:48 AM
Urutan langkah permulaan pangkalan data oracle ialah
May 10, 2024 am 01:48 AM
Urutan permulaan pangkalan data Oracle ialah: 1. Semak prasyarat 2. Mulakan pendengar 3. Mulakan contoh pangkalan data 5. Sambungkan ke pangkalan data; . Dayakan perkhidmatan (jika perlu );
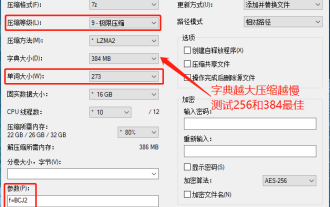 Tetapan kadar mampatan maksimum 7-zip, bagaimana untuk memampatkan 7zip kepada minimum
Jun 18, 2024 pm 06:12 PM
Tetapan kadar mampatan maksimum 7-zip, bagaimana untuk memampatkan 7zip kepada minimum
Jun 18, 2024 pm 06:12 PM
Saya mendapati bahawa pakej termampat yang dimuat turun dari laman web muat turun tertentu akan lebih besar daripada pakej termampat asal selepas penyahmampatan Perbezaannya ialah berpuluh-puluh Kb dan berpuluh-puluh Mb jika fail kecil, jika terdapat banyak fail, kos penyimpanan akan meningkat dengan banyak. Saya telah membuat beberapa kajian mengenainya dan boleh belajar daripadanya jika perlu. Tahap mampatan: 9-mampatan melampau Saiz kamus: 256 atau 384, semakin dimampatkan kamus, semakin perlahan perbezaan kadar mampatan lebih besar sebelum 256MB dan tiada perbezaan dalam kadar mampatan selepas 384MB: maksimum 273 Parameter: f=BCJ2, uji dan tambah kadar mampatan parameter akan lebih tinggi
 Bagaimana untuk melihat bilangan kemunculan watak tertentu dalam Oracle
May 09, 2024 pm 09:33 PM
Bagaimana untuk melihat bilangan kemunculan watak tertentu dalam Oracle
May 09, 2024 pm 09:33 PM
Untuk mencari bilangan kemunculan aksara dalam Oracle, lakukan langkah-langkah berikut: Dapatkan jumlah panjang rentetan Dapatkan panjang subrentetan di mana aksara berlaku; daripada jumlah panjang.
 Keperluan konfigurasi perkakasan pelayan pangkalan data Oracle
May 10, 2024 am 04:00 AM
Keperluan konfigurasi perkakasan pelayan pangkalan data Oracle
May 10, 2024 am 04:00 AM
Keperluan konfigurasi perkakasan pelayan pangkalan data Oracle: Pemproses: berbilang teras, dengan frekuensi utama sekurang-kurangnya 2.5 GHz Untuk pangkalan data yang besar, 32 teras atau lebih disyorkan. Memori: Sekurang-kurangnya 8GB untuk pangkalan data kecil, 16-64GB untuk saiz sederhana, sehingga 512GB atau lebih untuk pangkalan data yang besar atau beban kerja yang berat. Storan: Cakera SSD atau NVMe, tatasusunan RAID untuk lebihan dan prestasi. Rangkaian: Rangkaian berkelajuan tinggi (10GbE atau lebih tinggi), kad rangkaian khusus, rangkaian kependaman rendah. Lain-lain: Bekalan kuasa yang stabil, komponen berlebihan, sistem pengendalian dan perisian yang serasi, pelesapan haba dan sistem penyejukan.
 Berapa banyak memori yang diperlukan oleh oracle?
May 10, 2024 am 04:12 AM
Berapa banyak memori yang diperlukan oleh oracle?
May 10, 2024 am 04:12 AM
Jumlah memori yang diperlukan oleh Oracle bergantung pada saiz pangkalan data, tahap aktiviti dan tahap prestasi yang diperlukan: untuk menyimpan penimbal data, penimbal indeks, melaksanakan pernyataan SQL dan mengurus cache kamus data. Jumlah yang tepat dipengaruhi oleh saiz pangkalan data, tahap aktiviti dan tahap prestasi yang diperlukan. Amalan terbaik termasuk menetapkan saiz SGA yang sesuai, saiz komponen SGA, menggunakan AMM dan memantau penggunaan memori.
 Tugas berjadual Oracle melaksanakan langkah penciptaan sekali sehari
May 10, 2024 am 03:03 AM
Tugas berjadual Oracle melaksanakan langkah penciptaan sekali sehari
May 10, 2024 am 03:03 AM
Untuk mencipta tugas berjadual dalam Oracle yang dilaksanakan sekali sehari, anda perlu melakukan tiga langkah berikut: Buat kerja. Tambahkan subkerja pada kerja dan tetapkan ungkapan jadualnya kepada "INTERVAL 1 HARI". Dayakan kerja.
 Berapa banyak memori yang diperlukan untuk menggunakan pangkalan data oracle
May 10, 2024 am 03:42 AM
Berapa banyak memori yang diperlukan untuk menggunakan pangkalan data oracle
May 10, 2024 am 03:42 AM
Jumlah memori yang diperlukan untuk pangkalan data Oracle bergantung pada saiz pangkalan data, jenis beban kerja dan bilangan pengguna serentak. Cadangan am: Pangkalan data kecil: 16-32 GB, Pangkalan data sederhana: 32-64 GB, Pangkalan data besar: 64 GB atau lebih. Faktor lain yang perlu dipertimbangkan termasuk versi pangkalan data, pilihan pengoptimuman memori, virtualisasi dan amalan terbaik (pantau penggunaan memori, laraskan peruntukan).
