

cvKMeans2均值聚类分析+代码解析+灰度彩色图像聚类

1 K-均聚类算法的基本思想 K-均聚类算法 是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,KN。而且这K个分组满足下列条件:(1) 每一个分组至少包含一个数据纪录;(
1 K-均值聚类算法的基本思想
K-均值聚类算法是著名的划分聚类分割方法。划分方法的基本思想是:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K K-means算法的工作原理:算法首先随机从数据集中选取 K个点作为初始聚类中心,然后计算各个样本到聚类中心的距离,把样本归到离它最近的那个聚类中心所在的类。计算新形成的每一个聚类的数据对象的平均值来得到新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束,聚类准则函数 已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改聚类中心,进入下一次迭代。这个过程将不断重复直到满足某个终止条件,终止条件可以是以下任何一个: (1)没有对象被重新分配给不同的聚类。 (2)聚类中心再发生变化。 (3)误差平方和局部最小。 K-means聚类算法的一般步骤: (1)从 n个数据对象任意选择 k 个对象作为初始聚类中心; (2)循环(3)到(4)直到每个聚类不再发生变化为止; (3)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; (4)重新计算每个(有变化)聚类的均值(中心对象),直到聚类中心不再变化。这种划分使得下式最小 K-均值聚类法的缺点: (1)在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。 (2)在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。 (3) K-means算法需要不断地进行样本分类调整不断地计算调整后的新的聚类中心因此当数据量非常大时算法的时间开销是非常大的。 (4)K-means算法对一些离散点和初始k值敏感,不同的距离初始值对同样的数据样本可能得到不同的结果。
2 OpenCV中K均值函数分析:
CV_IMPL int
cvKMeans2( const CvArr* _samples, intcluster_count, CvArr* _labels,
CvTermCriteria termcrit, int attempts, CvRNG*,
intflags, CvArr* _centers, double* _compactness )
_samples:输入样本的浮点矩阵,每个样本一行,如对彩色图像进行聚类,每个通道一行,CV_32FC3
cluster_count:所给定的聚类数目
_labels:输出整数向量:每个样本对应的类别标识,其范围为0- (cluster_count-1),必须满足以下条件:
cv::Mat data = cv::cvarrToMat(_samples),labels = cv::cvarrToMat(_labels);
CV_Assert(labels.isContinuous() && labels.type() == CV_32S &&
(labels.cols == 1 || labels.rows == 1)&&
labels.cols + labels.rows - 1 ==data.rows );
termcrit:指定聚类的最大迭代次数和/或精度(两次迭代引起的聚类中心的移动距离),其执行 k-means 算法搜索 cluster_count 个类别的中心并对样本进行分类,输出 labels(i) 为样本i的类别标识。其中CvTermCriteria为OpenCV中的迭代算法的终止准则,其结构如下:
#define CV_TERMCRIT_ITER 1
#define CV_TERMCRIT_NUMBER CV_TERMCRIT_ITER
#define CV_TERMCRIT_EPS 2
typedef struct CvTermCriteria
{
int type; int max_iter; double epsilon;
} CvTermCriteria;
max_iter:最大迭代次数。 epsilon:结果的精确性 。
attempts:
flags: 与labels和centers相关
_centers: 输出聚类中心,可以不用设置输出聚类中心,但如果想输出聚类中心必须满足以下条件:
CV_Assert(!centers.empty() );
CV_Assert( centers.rows == cluster_count );
CV_Assert( centers.cols ==data.cols );
CV_Assert( centers.depth() == data.depth() );
聚类中心的获得方式:(以三类为例)
double cent0 = centers->data.fl[0];
double cent1 = centers->data.fl[1];
double cent2 = centers->data.fl[2];
CV_IMPL int
cvKMeans2( const CvArr* _samples,int cluster_count,CvArr* _labels,
CvTermCriteriatermcrit, intattempts, CvRNG*,
int flags, CvArr* _centers, double* _compactness )
{
cv::Mat data = cv::cvarrToMat(_samples), labels= cv::cvarrToMat(_labels), centers;
if( _centers )
{
centers= cv::cvarrToMat(_centers);
// 将centers和data转换为行向量
centers= centers.reshape(1);
data= data.reshape(1);
// centers必须满足的条件
CV_Assert(!centers.empty());
CV_Assert(centers.rows== cluster_count );
CV_Assert(centers.cols== data.cols);
CV_Assert(centers.depth()== data.depth());
}
// labels必须满足的条件
CV_Assert(labels.isContinuous()&& labels.type()== CV_32S &&
(labels.cols == 1 || labels.rows == 1) &&
labels.cols + labels.rows - 1 == data.rows );
// 调用kmeans实现聚类,如果定义了输出聚类中心矩阵,那么输出centers
double compactness = cv::kmeans(data, cluster_count, labels,termcrit, attempts,
flags, _centers? cv::_OutputArray(centers) : cv::_OutputArray() );
if( _compactness )
*_compactness= compactness;
return 1;
}
double cv::kmeans( InputArray_data, int K,
InputOutputArray_bestLabels,
TermCriteriacriteria, intattempts,
intflags, OutputArray_centers )
{
const int SPP_TRIALS =3;
Mat data = _data.getMat();
// 判断data是否为行向量
bool isrow = data.rows == 1 && data.channels() > 1;
int N = !isrow ? data.rows : data.cols;
int dims = (!isrow? data.cols: 1)*data.channels();
int type = data.depth();
attempts= std::max(attempts, 1);
CV_Assert(data.dimstype == CV_32F && K> 0 );
CV_Assert(N >= K);
_bestLabels.create(N, 1, CV_32S, -1, true);
Mat _labels, best_labels = _bestLabels.getMat();
// 使用已初始化的labels
if( flags & CV_KMEANS_USE_INITIAL_LABELS)
{
CV_Assert((best_labels.cols== 1 || best_labels.rows== 1) &&
best_labels.cols*best_labels.rows == N&&
best_labels.type() == CV_32S&&
best_labels.isContinuous());
best_labels.copyTo(_labels);
}
else
{
if( !((best_labels.cols== 1 || best_labels.rows== 1) &&
best_labels.cols*best_labels.rows == N&&
best_labels.type() == CV_32S&&
best_labels.isContinuous()))
best_labels.create(N, 1, CV_32S);
_labels.create(best_labels.size(), best_labels.type());
}
int* labels = _labels.ptrint>();
Mat centers(K, dims, type), old_centers(K, dims, type), temp(1, dims, type);
vectorint> counters(K);
vectorVec2f> _box(dims);
Vec2f* box = &_box[0];
double best_compactness = DBL_MAX,compactness = 0;
RNG&rng = theRNG();
int a, iter, i, j, k;
// 对终止条件进行修改
if( criteria.type& TermCriteria::EPS)
criteria.epsilon = std::max(criteria.epsilon, 0.);
else
criteria.epsilon = FLT_EPSILON;
criteria.epsilon *= criteria.epsilon;
if( criteria.type& TermCriteria::COUNT)
criteria.maxCount = std::min(std::max(criteria.maxCount, 2), 100);
else
criteria.maxCount = 100;
// 聚类数目为1类的时候
if( K == 1 )
{
attempts= 1;
criteria.maxCount = 2;
}
const float* sample = data.ptrfloat>(0);
for( j = 0; j dims; j++ )
box[j] = Vec2f(sample[j], sample[j]);
for( i = 1; i N; i++ )
{
sample= data.ptrfloat>(i);
for( j = 0; j dims; j++ )
{
floatv = sample[j];
box[j][0] = std::min(box[j][0], v);
box[j][1] = std::max(box[j][1], v);
}
}
for( a = 0; a attempts; a++ )
{
double max_center_shift = DBL_MAX;
for( iter = 0;; )
{
swap(centers, old_centers);
/*enum
{
KMEANS_RANDOM_CENTERS=0, // Chooses random centers for k-Meansinitialization
KMEANS_PP_CENTERS=2, // Usesk-Means++ algorithm for initialization
KMEANS_USE_INITIAL_LABELS=1 // Uses the user-provided labels for K-Meansinitialization
};*/
if(iter == 0 && (a > 0 || !(flags& KMEANS_USE_INITIAL_LABELS)) )
{
if(flags & KMEANS_PP_CENTERS)
generateCentersPP(data, centers, K, rng, SPP_TRIALS);
else
{
for(k = 0; kK; k++)
generateRandomCenter(_box, centers.ptrfloat>(k), rng);
}
}
else
{
if(iter == 0 && a == 0 && (flags& KMEANS_USE_INITIAL_LABELS) )
{
for(i = 0; iN; i++)
CV_Assert( (unsigned)labels[i] unsigned)K);
}
//compute centers
centers= Scalar(0);
for(k = 0; kK; k++)
counters[k] = 0;
for(i = 0; iN; i++)
{
sample= data.ptrfloat>(i);
k= labels[i];
float*center = centers.ptrfloat>(k);
j=0;
#ifCV_ENABLE_UNROLLED
for(;j dims- 4; j += 4 )
{
float t0 = center[j] + sample[j];
float t1 = center[j+1] + sample[j+1];
center[j] = t0;
center[j+1] = t1;
t0 = center[j+2] + sample[j+2];
t1 = center[j+3] + sample[j+3];
center[j+2] = t0;
center[j+3] = t1;
}
#endif
for(; j dims;j++ )
center[j] += sample[j];
counters[k]++;
}
if(iter > 0 )
max_center_shift= 0;
for(k = 0; kK; k++)
{
if(counters[k]!= 0 )
continue;
// if somecluster appeared to be empty then:
// 1. find the biggest cluster
// 2. find the farthest from the center pointin the biggest cluster
// 3. exclude the farthest point from thebiggest cluster and form a new 1-point cluster.
intmax_k = 0;
for(int k1 = 1; k1 K; k1++ )
{
if( counters[max_k] counters[k1] )
max_k = k1;
}
doublemax_dist = 0;
intfarthest_i = -1;
float*new_center = centers.ptrfloat>(k);
float*old_center = centers.ptrfloat>(max_k);
float*_old_center = temp.ptrfloat>();// normalized
floatscale = 1.f/counters[max_k];
for(j = 0; jdims; j++)
_old_center[j] = old_center[j]*scale;
for(i = 0; iN; i++)
{
if(labels[i]!= max_k )
continue;
sample = data.ptrfloat>(i);
double dist = normL2Sqr_(sample,_old_center, dims);
if( max_dist dist )
{
max_dist = dist;
farthest_i = i;
}
}
counters[max_k]--;
counters[k]++;
labels[farthest_i] = k;
sample= data.ptrfloat>(farthest_i);
for(j = 0; jdims; j++)
{
old_center[j] -= sample[j];
new_center[j] += sample[j];
}
}
for(k = 0; kK; k++)
{
float*center = centers.ptrfloat>(k);
CV_Assert(counters[k]!= 0 );
floatscale = 1.f/counters[k];
for(j = 0; jdims; j++)
center[j] *= scale;
if(iter > 0 )
{
double dist = 0;
const float* old_center = old_centers.ptrfloat>(k);
for( j = 0; j dims; j++ )
{
double t = center[j] - old_center[j];
dist += t*t;
}
max_center_shift= std::max(max_center_shift, dist);
}
}
}
if(++iter == MAX(criteria.maxCount,2) || max_center_shift criteria.epsilon)
break;
// assignlabels
Matdists(1, N,CV_64F);
double*dist = dists.ptrdouble>(0);
parallel_for_(Range(0, N),
KMeansDistanceComputer(dist,labels, data,centers));
compactness= 0;
for(i = 0; iN; i++)
{
compactness+= dist[i];
}
}
if( compactness best_compactness)
{
best_compactness= compactness;
if(_centers.needed())
centers.copyTo(_centers);
_labels.copyTo(best_labels);
}
}
return best_compactness;
}
3 采用cvKMeans2对灰度图像进行聚类分析
//灰度图像聚类分析
BOOL GrayImageSegmentByKMeans2(const IplImage* pImg, IplImage*pResult, intsortFlag)
{
assert(pImg != NULL&& pImg->nChannels== 1);
//创建样本矩阵,CV_32FC1代表位浮点通道(灰度图像)
CvMat*samples = cvCreateMat((pImg->width)* (pImg->height),1, CV_32FC1);
//创建类别标记矩阵,CV_32SF1代表位整型通道
CvMat*clusters = cvCreateMat((pImg->width)* (pImg->height),1, CV_32SC1);
//创建类别中心矩阵
CvMat*centers = cvCreateMat(nClusters, 1, CV_32FC1);
// 将原始图像转换到样本矩阵
{
intk = 0;
CvScalars;
for(int i = 0; i pImg->width; i++)
{
for(int j=0;j pImg->height; j++)
{
s.val[0] = (float)cvGet2D(pImg, j, i).val[0];
cvSet2D(samples,k++, 0, s);
}
}
}
//开始聚类,迭代次,终止误差.0
cvKMeans2(samples, nClusters,clusters, cvTermCriteria(CV_TERMCRIT_ITER + CV_TERMCRIT_EPS,100, 1.0), 1, 0, 0, centers);
// 无需排序直接输出时
if (sortFlag == 0)
{
intk = 0;
intval = 0;
floatstep = 255 / ((float)nClusters - 1);
CvScalars;
for(int i = 0; i pImg->width; i++)
{
for(int j = 0;j pImg->height; j++)
{
val = (int)clusters->data.i[k++];
s.val[0] = 255- val * step;//这个是将不同类别取不同的像素值,
cvSet2D(pResult,j, i, s); //将每个像素点赋值
}
}
returnTRUE;
}
4 利用OpenCV对彩色图像进行颜色聚类:
BOOL ColorImageSegmentByKMeans2(const IplImage* img, IplImage* pResult, int sortFlag)
{
assert(img != NULL&& pResult != NULL);
assert(img->nChannels== 3 && pResult->nChannels == 1);
int i,j;
CvMat*samples=cvCreateMat((img->width)*(img->height),1,CV_32FC3);//创建样本矩阵,CV_32FC3代表位浮点通道(彩色图像)
CvMat*clusters=cvCreateMat((img->width)*(img->height),1,CV_32SC1);//创建类别标记矩阵,CV_32SF1代表位整型通道
int k=0;
for (i=0;iimg->width;i++)
{
for(j=0;jimg->height;j++)
{
CvScalars;
//获取图像各个像素点的三通道值(RGB)
s.val[0]=(float)cvGet2D(img,j,i).val[0];
s.val[1]=(float)cvGet2D(img,j,i).val[1];
s.val[2]=(float)cvGet2D(img,j,i).val[2];
cvSet2D(samples,k++,0,s);//将像素点三通道的值按顺序排入样本矩阵
}
}
cvKMeans2(samples,nClusters,clusters,cvTermCriteria(CV_TERMCRIT_ITER,100,1.0));//开始聚类,迭代次,终止误差.0
k=0;
int val=0;
float step=255/(nClusters-1);
for (i=0;iimg->width;i++)
{
for(j=0;jimg->height;j++)
{
val=(int)clusters->data.i[k++];
CvScalars;
s.val[0]=255-val*step;//这个是将不同类别取不同的像素值,
cvSet2D(pResult,j,i,s); //将每个像素点赋值
}
}
cvReleaseMat(&samples);
cvReleaseMat(&clusters);
return TRUE;
}

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Penjelasan terperinci tentang ralat Oracle 3114: Cara menyelesaikannya dengan cepat
Mar 08, 2024 pm 02:42 PM
Penjelasan terperinci tentang ralat Oracle 3114: Cara menyelesaikannya dengan cepat
Mar 08, 2024 pm 02:42 PM
Penjelasan terperinci tentang ralat Oracle 3114: Bagaimana untuk menyelesaikannya dengan cepat, contoh kod khusus diperlukan Semasa pembangunan dan pengurusan pangkalan data Oracle, kami sering menghadapi pelbagai ralat, antaranya ralat 3114 adalah masalah yang agak biasa. Ralat 3114 biasanya menunjukkan masalah dengan sambungan pangkalan data, yang mungkin disebabkan oleh kegagalan rangkaian, pemberhentian perkhidmatan pangkalan data atau tetapan rentetan sambungan yang salah. Artikel ini akan menerangkan secara terperinci punca ralat 3114 dan cara menyelesaikan masalah ini dengan cepat, dan melampirkan kod tertentu
 Analisis makna dan penggunaan titik tengah dalam PHP
Mar 27, 2024 pm 08:57 PM
Analisis makna dan penggunaan titik tengah dalam PHP
Mar 27, 2024 pm 08:57 PM
[Analisis makna dan penggunaan titik tengah dalam PHP] Dalam PHP, titik tengah (.) ialah operator yang biasa digunakan untuk menyambung dua rentetan atau sifat atau kaedah objek. Dalam artikel ini, kami akan menyelami makna dan penggunaan titik tengah dalam PHP, menggambarkannya dengan contoh kod konkrit. 1. Operator titik tengah rentetan Concatenate Penggunaan yang paling biasa dalam PHP adalah untuk menggabungkan dua rentetan. Dengan meletakkan . antara dua rentetan, anda boleh menyambungkannya untuk membentuk rentetan baharu. $string1=&qu
 Parsing Wormhole NTT: rangka kerja terbuka untuk sebarang Token
Mar 05, 2024 pm 12:46 PM
Parsing Wormhole NTT: rangka kerja terbuka untuk sebarang Token
Mar 05, 2024 pm 12:46 PM
Wormhole ialah peneraju dalam kebolehkendalian blockchain, memfokuskan pada mencipta sistem terdesentralisasi yang berdaya tahan, kalis masa hadapan yang mengutamakan pemilikan, kawalan dan inovasi tanpa kebenaran. Asas visi ini ialah komitmen terhadap kepakaran teknikal, prinsip etika dan penjajaran komuniti untuk mentakrifkan semula landskap kebolehoperasian dengan kesederhanaan, kejelasan dan rangkaian luas penyelesaian berbilang rantaian. Dengan peningkatan bukti pengetahuan sifar, penyelesaian penskalaan dan piawaian token yang kaya dengan ciri, rantaian blok menjadi lebih berkuasa dan kesalingoperasian menjadi semakin penting. Dalam persekitaran aplikasi yang inovatif ini, sistem tadbir urus baharu dan keupayaan praktikal membawa peluang yang belum pernah berlaku sebelum ini kepada aset merentas rangkaian. Pembina protokol kini bergelut dengan cara untuk beroperasi dalam pelbagai rantaian yang muncul ini
 Cipta dan jalankan fail '.a' Linux
Mar 20, 2024 pm 04:46 PM
Cipta dan jalankan fail '.a' Linux
Mar 20, 2024 pm 04:46 PM
Bekerja dengan fail dalam sistem pengendalian Linux memerlukan penggunaan pelbagai arahan dan teknik yang membolehkan pembangun mencipta dan melaksanakan fail, kod, program, skrip dan perkara lain dengan cekap. Dalam persekitaran Linux, fail dengan sambungan ".a" mempunyai kepentingan yang besar sebagai perpustakaan statik. Perpustakaan ini memainkan peranan penting dalam pembangunan perisian, membolehkan pembangun mengurus dan berkongsi fungsi biasa dengan cekap merentas berbilang program. Untuk pembangunan perisian yang berkesan dalam persekitaran Linux, adalah penting untuk memahami cara mencipta dan menjalankan fail ".a". Artikel ini akan memperkenalkan cara memasang dan mengkonfigurasi fail ".a" Linux secara menyeluruh Mari kita terokai definisi, tujuan, struktur dan kaedah mencipta dan melaksanakan fail ".a" Linux. Apa itu L
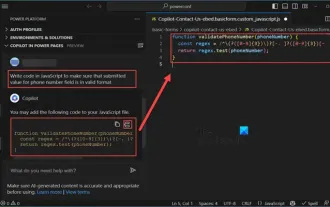 Cara menggunakan Copilot untuk menjana kod
Mar 23, 2024 am 10:41 AM
Cara menggunakan Copilot untuk menjana kod
Mar 23, 2024 am 10:41 AM
Sebagai seorang pengaturcara, saya teruja dengan alatan yang memudahkan pengalaman pengekodan. Dengan bantuan alat kecerdasan buatan, kami boleh menjana kod demo dan membuat pengubahsuaian yang diperlukan mengikut keperluan. Alat Copilot yang baru diperkenalkan dalam Visual Studio Code membolehkan kami mencipta kod yang dijana AI dengan interaksi sembang bahasa semula jadi. Dengan menerangkan kefungsian, kami dapat memahami dengan lebih baik maksud kod sedia ada. Bagaimana untuk menggunakan Copilot untuk menjana kod? Untuk bermula, kami terlebih dahulu perlu mendapatkan sambungan PowerPlatformTools yang terkini. Untuk mencapai ini, anda perlu pergi ke halaman sambungan, cari "PowerPlatformTool" dan klik butang Pasang
 Analisis ciri baharu Win11: Bagaimana untuk melangkau log masuk ke akaun Microsoft
Mar 27, 2024 pm 05:24 PM
Analisis ciri baharu Win11: Bagaimana untuk melangkau log masuk ke akaun Microsoft
Mar 27, 2024 pm 05:24 PM
Analisis ciri baharu Win11: Cara melangkau log masuk ke akaun Microsoft Dengan keluaran Windows 11, ramai pengguna mendapati ia membawa lebih banyak kemudahan dan ciri baharu. Walau bagaimanapun, sesetengah pengguna mungkin tidak suka sistem mereka terikat pada akaun Microsoft dan ingin melangkau langkah ini. Artikel ini akan memperkenalkan beberapa kaedah untuk membantu pengguna melangkau log masuk ke akaun Microsoft dalam Windows 11 dan mencapai pengalaman yang lebih peribadi dan autonomi. Mula-mula, mari kita fahami sebab sesetengah pengguna enggan log masuk ke akaun Microsoft mereka. Di satu pihak, sesetengah pengguna bimbang bahawa mereka
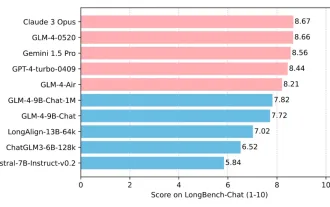 Universiti Tsinghua dan sumber terbuka Zhipu AI GLM-4: melancarkan revolusi baharu dalam pemprosesan bahasa semula jadi
Jun 12, 2024 pm 08:38 PM
Universiti Tsinghua dan sumber terbuka Zhipu AI GLM-4: melancarkan revolusi baharu dalam pemprosesan bahasa semula jadi
Jun 12, 2024 pm 08:38 PM
Sejak pelancaran ChatGLM-6B pada 14 Mac 2023, model siri GLM telah mendapat perhatian dan pengiktirafan yang meluas. Terutama selepas ChatGLM3-6B menjadi sumber terbuka, pembangun penuh dengan jangkaan untuk model generasi keempat yang dilancarkan oleh Zhipu AI. Jangkaan ini akhirnya telah berpuas hati sepenuhnya dengan keluaran GLM-4-9B. Kelahiran GLM-4-9B Untuk memberikan model kecil (10B dan ke bawah) keupayaan yang lebih berkuasa, pasukan teknikal GLM melancarkan model sumber terbuka siri GLM generasi keempat baharu ini: GLM-4-9B selepas hampir setengah tahun penerokaan. Model ini sangat memampatkan saiz model sambil memastikan ketepatan, dan mempunyai kelajuan inferens yang lebih pantas dan kecekapan yang lebih tinggi. Penerokaan pasukan teknikal GLM tidak
 Buat Ejen dalam satu ayat! Robin Li: Era akan datang apabila semua orang adalah pemaju
Apr 17, 2024 pm 02:28 PM
Buat Ejen dalam satu ayat! Robin Li: Era akan datang apabila semua orang adalah pemaju
Apr 17, 2024 pm 02:28 PM
Model besar mengubah segala-galanya, dan akhirnya sampai kepada ketua editor ini. Ia juga merupakan Agen yang dicipta hanya dalam satu ayat. Seperti ini, berikan dia artikel, dan dalam masa kurang dari 1 saat, cadangan tajuk baru akan keluar. Berbanding dengan saya, kecekapan ini hanya boleh dikatakan sepantas kilat dan lambat seperti kemalasan... Apa yang lebih luar biasa ialah mencipta Ejen ini hanya mengambil masa beberapa minit sahaja. Prompt adalah milik Mak Cik Jiang: Dan jika anda juga ingin mengalami perasaan subversif ini, kini, berdasarkan platform pintar Wenxin baharu yang dilancarkan oleh Baidu, semua orang boleh mencipta pembantu pintar mereka sendiri secara percuma. Anda boleh menggunakan enjin carian, platform perkakasan pintar, pengecaman pertuturan, peta, kereta dan saluran ekologi mudah alih Baidu yang lain untuk membolehkan lebih ramai orang menggunakan kreativiti anda! Robin Li sendiri
