

Redis源码分析(六)---ziplist压缩列表

ziplist和之前我解析过的adlist列表名字看上去的很像,但是作用却完全不同。之前的adlist主要针对的是普通的数据链表操作。而今天的ziplist指的是压缩链表,为什么叫压缩链表呢,因为链表中我们一般常用pre,next来指明当前的结点的前一个指针或当前的结点的
ziplist和之前我解析过的adlist列表名字看上去的很像,但是作用却完全不同。之前的adlist主要针对的是普通的数据链表操作。而今天的ziplist指的是压缩链表,为什么叫压缩链表呢,因为链表中我们一般常用pre,next来指明当前的结点的前一个指针或当前的结点的下一个指针,这其实是在一定程度上占据了比较多的内存空间,ziplist采用了长度的表示方法,整个ziplist其实是超级长的字符串,通过里面各个结点的长度,上一个结点的长度等信息,通过快速定位实现相关操作,而且编写者,在长度上也做了动态分配字节的方法,表示长度,避免了一定的内存耗费,比如一个结点的字符串长度每个都很短,而你使用好几个字节表示字符串的长度,显然造成大量浪费,所以在长度表示方面,ziplist 就做到了压缩,也体现了压缩的性能。ziplist 用在什么地方呢,ziplist 就是用在我们平常最常用的一个命令rpush,lpush等这些往链表添加数据的方法,这些数据就是存在ziplist 中的。之后我们会看到相应的实现方法。
在学习ziplist的开始,一定要理解他的结构,关于这一点,必须花一定时间想想,要不然不太容易明白人家的设计。下面是我的理解,帮助大家理解:
/* The ziplist is a specially encoded dually linked list that is designed * to be very memory efficient. It stores both strings and integer values, * where integers are encoded as actual integers instead of a series of * characters. It allows push and pop operations on either side of the list * in O(1) time. However, because every operation requires a reallocation of * the memory used by the ziplist, the actual complexity is related to the * amount of memory used by the ziplist. * * ziplist是一个编码后的列表,特殊的设计使得内存操作非常有效率,此列表可以同时存放 * 字符串和整数类型,列表可以在头尾各边支持推加和弹出操作在O(1)常量时间,但是,因为每次 * 操作设计到内存的重新分配释放,所以加大了操作的复杂性 * ---------------------------------------------------------------------------- * * ziplist的结构组成: * ZIPLIST OVERALL LAYOUT: * The general layout of the ziplist is as follows: * <zlbytes><zltail><zllen><entry><entry><zlend> * * <zlbytes> is an unsigned integer to hold the number of bytes that the * ziplist occupies. This value needs to be stored to be able to resize the * entire structure without the need to traverse it first. * <zipbytes>代表着ziplist占有的字节数,这方便当重新调整大小的时候不需要重新从头遍历 * * <zltail> is the offset to the last entry in the list. This allows a pop * operation on the far side of the list without the need for full traversal. * <zltail>记录了最后一个entry的位置在列表中,可以方便快速在列表末尾弹出操作 * * <zllen> is the number of entries.When this value is larger than 2**16-2, * we need to traverse the entire list to know how many items it holds. * <zllen>记录的是ziplist里面entry数据结点的总数 * * <zlend> is a single byte special value, equal to 255, which indicates the * end of the list. * <zlend>代表的是结束标识别,用单字节表示,值是255,就是11111111 * * ZIPLIST ENTRIES: * Every entry in the ziplist is prefixed by a header that contains two pieces * of information. First, the length of the previous entry is stored to be * able to traverse the list from back to front. Second, the encoding with an * optional string length of the entry itself is stored. * 每个entry数据结点主要包含2部分信息,第一个,上一个结点的长度,主要就可以可以从任意结点从后往前遍历整个列表 * 第二个,编码字符串的方式的类型保存 * * The length of the previous entry is encoded in the following way: * If this length is smaller than 254 bytes, it will only consume a single * byte that takes the length as value. When the length is greater than or * equal to 254, it will consume 5 bytes. The first byte is set to 254 to * indicate a larger value is following. The remaining 4 bytes take the * length of the previous entry as value. * 之前的数据结点的字符串长度的长度少于254个字节,他将消耗单个字节,一个字节8位,最大可表示长度为2的8次方 * 当字符串的长度大于254个字节,则用5个字节表示,第一个字节被设置成254,其余的4个字节占据的长度为之前的数据结点的长度 * * The other header field of the entry itself depends on the contents of the * entry. When the entry is a string, the first 2 bits of this header will hold * the type of encoding used to store the length of the string, followed by the * actual length of the string. When the entry is an integer the first 2 bits * are both set to 1. The following 2 bits are used to specify what kind of * integer will be stored after this header. An overview of the different * types and encodings is as follows: * 头部信息中的另一个值记录着编码的方式,当编码的是字符串,头部的前2位为00,01,10共3种 * 如果编码的是整型数字的时候,则头部的前2位为11,代表的是整数编码,后面2位代表什么类型整型值将会在头部后面被编码 * 00-int16_t, 01-int32_t, 10-int64_t, 11-24 bit signed,还有比较特殊的2个,11111110-8 bit signed, * 1111 0000 - 1111 1101,代表的是整型值0-12,头尾都已经存在,都不能使用,与传统的通过固定的指针表示长度,这么做的好处实现 * 可以更合理的分配内存 * * String字符串编码的3种形式 * |00pppppp| - 1 byte * String value with length less than or equal to 63 bytes (6 bits). * |01pppppp|qqqqqqqq| - 2 bytes * String value with length less than or equal to 16383 bytes (14 bits). * |10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes * String value with length greater than or equal to 16384 bytes. * |11000000| - 1 byte * Integer encoded as int16_t (2 bytes). * |11010000| - 1 byte * Integer encoded as int32_t (4 bytes). * |11100000| - 1 byte * Integer encoded as int64_t (8 bytes). * |11110000| - 1 byte * Integer encoded as 24 bit signed (3 bytes). * |11111110| - 1 byte * Integer encoded as 8 bit signed (1 byte). * |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer. * Unsigned integer from 0 to 12. The encoded value is actually from * 1 to 13 because 0000 and 1111 can not be used, so 1 should be * subtracted from the encoded 4 bit value to obtain the right value. * |11111111| - End of ziplist. * * All the integers are represented in little endian byte order. * * ----------------------------------------------------------------------------
/* 实际存放数据的数据结点 */
typedef struct zlentry {
//prevrawlen为上一个数据结点的长度,prevrawlensize为记录该长度数值所需要的字节数
unsigned int prevrawlensize, prevrawlen;
//len为当前数据结点的长度,lensize表示表示当前长度表示所需的字节数
unsigned int lensize, len;
//数据结点的头部信息长度的字节数
unsigned int headersize;
//编码的方式
unsigned char encoding;
//数据结点的数据(已包含头部等信息),以字符串形式保存
unsigned char *p;
} zlentry;
/* <zlentry>的结构图线表示 <pre_node_len>(上一结点的长度信息)<node_encode>(本结点的编码方式和编码数据的长度信息)<node>(本结点的编码数据) */
/* Insert item at "p". */
/* 插入操作的实现 */
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
//寻找插入的位置
if (p[0] != ZIP_END) {
//定位到指定位置
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
//如果插入的位置是尾结点,直接定位到尾结点,看第一个字节的就可以判断
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipPrevEncodeLength(NULL,prevlen);
reqlen += zipEncodeLength(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* Store offset because a realloc may change the address of zl. */
//调整大小,为新结点的插入预留空间
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
//如果插入的位置不是尾结点,则挪动位置
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
tail = zipEntry(p+reqlen);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
//如果是尾结点,直接设置新尾结点
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
//写入新的数据结点信息
p += zipPrevEncodeLength(p,prevlen);
p += zipEncodeLength(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
//更新列表的长度加1
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
/* Delete "num" entries, starting at "p". Returns pointer to the ziplist. */
/* 删除方法涉及p指针的滑动,后面的地址内容都需要滑动 */
static unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
first = zipEntry(p);
for (i = 0; p[0] != ZIP_END && i < num; i++) {
p += zipRawEntryLength(p);
deleted++;
}
totlen = p-first.p;
if (totlen > 0) {
if (p[0] != ZIP_END) {
/* Storing `prevrawlen` in this entry may increase or decrease the
* number of bytes required compare to the current `prevrawlen`.
* There always is room to store this, because it was previously
* stored by an entry that is now being deleted. */
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen);
p -= nextdiff;
zipPrevEncodeLength(p,first.prevrawlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
tail = zipEntry(p);
if (p[tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
/* Move tail to the front of the ziplist */
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
} else {
/* The entire tail was deleted. No need to move memory. */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
}
/* Resize and update length */
//调整列表大小
offset = first.p-zl;
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
ZIPLIST_INCR_LENGTH(zl,-deleted);
p = zl+offset;
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl,p);
}
return zl;
}
下面我们看看我们在redis命令行中输入的lpush或rpush调用的是什么方法呢?调用的形式:
zl = ziplistPush(zl, (unsigned char*)"foo", 3, ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)"quux", 4, ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)"hello", 5, ZIPLIST_HEAD);
/* 在列表2边插入数据的方法 */
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
//这里开始直接定位
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
//组后调用插入数据的insert方法
return __ziplistInsert(zl,p,s,slen);
}
/* zip列表的末尾值 */ #define ZIP_END 255 /* zip列表的最大长度 */ #define ZIP_BIGLEN 254 /* Different encoding/length possibilities */ /* 不同的编码 */ #define ZIP_STR_MASK 0xc0 #define ZIP_INT_MASK 0x30 #define ZIP_STR_06B (0 << 6) #define ZIP_STR_14B (1 << 6) #define ZIP_STR_32B (2 << 6) #define ZIP_INT_16B (0xc0 | 0<<4) #define ZIP_INT_32B (0xc0 | 1<<4) #define ZIP_INT_64B (0xc0 | 2<<4) #define ZIP_INT_24B (0xc0 | 3<<4) #define ZIP_INT_8B 0xfe /* 4 bit integer immediate encoding */ #define ZIP_INT_IMM_MASK 0x0f //后续的好多运算都需要与掩码进行位运算 #define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */ #define ZIP_INT_IMM_MAX 0xfd /* 11111101 */ //最大值不能为11111111,这跟最末尾的结点重复了 #define ZIP_INT_IMM_VAL(v) (v & ZIP_INT_IMM_MASK) #define INT24_MAX 0x7fffff #define INT24_MIN (-INT24_MAX - 1) /* Macro to determine type */ #define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK) /* Utility macros */ /* 下面是一些用来到时能够直接定位的数值偏移量 */ #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
/* * Copyright (c) 2009-2012, Pieter Noordhuis <pcnoordhuis at gmail dot com> * Copyright (c) 2009-2012, Salvatore Sanfilippo <antirez at gmail dot com> * All rights reserved. * * Redistribution and use in source and binary forms, with or without * modification, are permitted provided that the following conditions are met: * * * Redistributions of source code must retain the above copyright notice, * this list of conditions and the following disclaimer. * * Redistributions in binary form must reproduce the above copyright * notice, this list of conditions and the following disclaimer in the * documentation and/or other materials provided with the distribution. * * Neither the name of Redis nor the names of its contributors may be used * to endorse or promote products derived from this software without * specific prior written permission. * * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE * ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE * LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR * CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF * SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS * INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN * CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) * ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE * POSSIBILITY OF SUCH DAMAGE. */ /* 标记列表头节点和尾结点的标识 */ #define ZIPLIST_HEAD 0 #define ZIPLIST_TAIL 1 unsigned char *ziplistNew(void); //创建新列表 unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where); //像列表中推入数据 unsigned char *ziplistIndex(unsigned char *zl, int index); //索引定位到列表的某个位置 unsigned char *ziplistNext(unsigned char *zl, unsigned char *p); //获取当前列表位置的下一个值 unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p); //获取当期列表位置的前一个值 unsigned int ziplistGet(unsigned char *p, unsigned char **sval, unsigned int *slen, long long *lval); //获取列表的信息 unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen); //向列表中插入数据 unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p); //列表中删除某个结点 unsigned char *ziplistDeleteRange(unsigned char *zl, unsigned int index, unsigned int num); //从index索引对应的结点开始算起,删除num个结点 unsigned int ziplistCompare(unsigned char *p, unsigned char *s, unsigned int slen); //列表间的比较方法 unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip); //在列表中寻找某个结点 unsigned int ziplistLen(unsigned char *zl); //返回列表的长度 size_t ziplistBlobLen(unsigned char *zl); //返回列表的二进制长度,返回的是字节数

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Penyelesaian kepada ralat 0x80242008 semasa memasang Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
Penyelesaian kepada ralat 0x80242008 semasa memasang Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
1. Mulakan menu [Start], masukkan [cmd], klik kanan [Command Prompt], dan pilih Run as [Administrator]. 2. Masukkan arahan berikut mengikut turutan (salin dan tampal dengan teliti): SCconfigwuauservstart=auto, tekan Enter SCconfigbitsstart=auto, tekan Enter SCconfigcryptsvcstart=auto, tekan Enter SCconfigtrustedinstallerstart=auto, tekan Enter SCconfigwuauservtype=share, tekan Enter netstopwuauserv , tekan enter netstopcryptS
 Tetapan kadar mampatan maksimum 7-zip, bagaimana untuk memampatkan 7zip kepada minimum
Jun 18, 2024 pm 06:12 PM
Tetapan kadar mampatan maksimum 7-zip, bagaimana untuk memampatkan 7zip kepada minimum
Jun 18, 2024 pm 06:12 PM
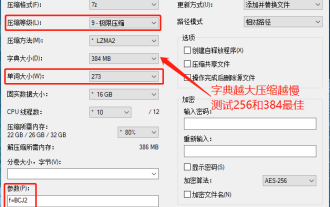
Saya mendapati bahawa pakej termampat yang dimuat turun dari laman web muat turun tertentu akan lebih besar daripada pakej termampat asal selepas penyahmampatan Perbezaannya ialah berpuluh-puluh Kb dan berpuluh-puluh Mb jika fail kecil, jika terdapat banyak fail, kos penyimpanan akan meningkat dengan banyak. Saya telah membuat beberapa kajian mengenainya dan boleh belajar daripadanya jika perlu. Tahap mampatan: 9-mampatan melampau Saiz kamus: 256 atau 384, semakin dimampatkan kamus, semakin perlahan perbezaan kadar mampatan lebih besar sebelum 256MB dan tiada perbezaan dalam kadar mampatan selepas 384MB: maksimum 273 Parameter: f=BCJ2, uji dan tambah kadar mampatan parameter akan lebih tinggi
 Strategi dan pengoptimuman caching API Golang
May 07, 2024 pm 02:12 PM
Strategi dan pengoptimuman caching API Golang
May 07, 2024 pm 02:12 PM
Strategi caching dalam GolangAPI boleh meningkatkan prestasi dan mengurangkan beban pelayan Strategi yang biasa digunakan ialah: LRU, LFU, FIFO dan TTL. Teknik pengoptimuman termasuk memilih storan cache yang sesuai, caching hierarki, pengurusan ketidaksahihan dan pemantauan dan penalaan. Dalam kes praktikal, cache LRU digunakan untuk mengoptimumkan API untuk mendapatkan maklumat pengguna daripada pangkalan data Data boleh diambil dengan cepat daripada cache Jika tidak, cache boleh dikemas kini selepas mendapatkannya daripada pangkalan data.
 Mekanisme caching dan amalan aplikasi dalam pembangunan PHP
May 09, 2024 pm 01:30 PM
Mekanisme caching dan amalan aplikasi dalam pembangunan PHP
May 09, 2024 pm 01:30 PM
Dalam pembangunan PHP, mekanisme caching meningkatkan prestasi dengan menyimpan sementara data yang kerap diakses dalam memori atau cakera, dengan itu mengurangkan bilangan akses pangkalan data. Jenis cache terutamanya termasuk memori, fail dan cache pangkalan data. Caching boleh dilaksanakan dalam PHP menggunakan fungsi terbina dalam atau perpustakaan pihak ketiga, seperti cache_get() dan Memcache. Aplikasi praktikal biasa termasuk caching hasil pertanyaan pangkalan data untuk mengoptimumkan prestasi pertanyaan dan caching halaman output untuk mempercepatkan pemaparan. Mekanisme caching berkesan meningkatkan kelajuan tindak balas laman web, meningkatkan pengalaman pengguna dan mengurangkan beban pelayan.
 Bagaimana untuk menaik taraf Win11 English 21996 kepada Simplified Chinese 22000_Cara untuk menaik taraf Win11 English 21996 kepada Simplified Chinese 22000
May 08, 2024 pm 05:10 PM
Bagaimana untuk menaik taraf Win11 English 21996 kepada Simplified Chinese 22000_Cara untuk menaik taraf Win11 English 21996 kepada Simplified Chinese 22000
May 08, 2024 pm 05:10 PM
Mula-mula anda perlu menetapkan bahasa sistem kepada paparan Bahasa Cina Mudah dan mulakan semula. Sudah tentu, jika anda telah menukar bahasa paparan kepada Bahasa Cina Ringkas sebelum ini, anda boleh melangkau langkah ini sahaja. Seterusnya, mula mengendalikan pendaftaran, regedit.exe, navigasi terus ke HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage dalam bar navigasi kiri atau bar alamat atas, dan kemudian ubah suai nilai kunci InstallLanguage dan nilai kunci Lalai kepada 0804 (jika anda ingin menukarnya ke Bahasa Inggeris en- kami, anda perlu Mula-mula tetapkan bahasa paparan sistem kepada en-us, mulakan semula sistem dan kemudian tukar semuanya kepada 0409) Anda mesti memulakan semula sistem pada ketika ini.
 Bagaimana untuk mencari fail kemas kini yang dimuat turun oleh Win11_Share lokasi fail kemas kini yang dimuat turun oleh Win11
May 08, 2024 am 10:34 AM
Bagaimana untuk mencari fail kemas kini yang dimuat turun oleh Win11_Share lokasi fail kemas kini yang dimuat turun oleh Win11
May 08, 2024 am 10:34 AM
1. Mula-mula, klik dua kali ikon [PC ini] pada desktop untuk membukanya. 2. Kemudian klik dua kali butang tetikus kiri untuk memasuki [pemacu C]. 3. Kemudian cari folder [windows] dalam pemacu C dan klik dua kali untuk masuk. 4. Selepas memasukkan folder [windows], cari folder [SoftwareDistribution]. 5. Selepas masuk, cari folder [muat turun], yang mengandungi semua fail muat turun dan kemas kini win11. 6. Jika kita ingin memadam fail-fail ini, hanya padamkannya terus dalam folder ini.
 Aplikasi caching PHP Redis dan amalan terbaik
May 04, 2024 am 08:33 AM
Aplikasi caching PHP Redis dan amalan terbaik
May 04, 2024 am 08:33 AM
Redis ialah cache nilai kunci berprestasi tinggi. Sambungan PHPRedis menyediakan API untuk berinteraksi dengan pelayan Redis. Gunakan langkah berikut untuk menyambung ke Redis, menyimpan dan mendapatkan semula data: Sambung: Gunakan kelas Redis untuk menyambung ke pelayan. Penyimpanan: Gunakan kaedah yang ditetapkan untuk menetapkan pasangan nilai kunci. Retrieval: Gunakan kaedah get untuk mendapatkan nilai kunci.
 Panduan komprehensif untuk mempelajari dan menggunakan kod sumber rangka kerja golang
Jun 01, 2024 pm 10:31 PM
Panduan komprehensif untuk mempelajari dan menggunakan kod sumber rangka kerja golang
Jun 01, 2024 pm 10:31 PM
Dengan memahami kod sumber rangka kerja Golang, pembangun boleh menguasai intipati bahasa dan mengembangkan fungsi rangka kerja. Mula-mula, dapatkan kod sumber dan biasakan diri dengan struktur direktorinya. Kedua, baca kod, jejak aliran pelaksanaan, dan fahami kebergantungan. Contoh praktikal menunjukkan cara menggunakan pengetahuan ini: cipta perisian tengah tersuai dan lanjutkan sistem penghalaan. Amalan terbaik termasuk pembelajaran langkah demi langkah, mengelakkan penampalan salin tanpa fikiran, menggunakan alatan dan merujuk kepada sumber dalam talian.
