

mongoDB入门需要了解的基本知识

MongoDB是一个开源的,高性能,无模式(或者说是模式自由),使用C++语言编写的面向文档的数据库。正因为MongoDB是面向文档的,所以它可以管理类似JSON的文档集合。又因为数据可以被嵌套到复杂的体系中并保持可以查询可索引,这样一来,应用程序便可以以一种
MongoDB是一个开源的,高性能,无模式(或者说是模式自由),使用C++语言编写的面向文档的数据库。正因为MongoDB是面向文档的,所以它可以管理类似JSON的文档集合。又因为数据可以被嵌套到复杂的体系中并保持可以查询可索引,这样一来,应用程序便可以以一种更加自然的方式来为数据建模。
下面介绍MongoDB的特点:
- 统一的UTF-8编码:不是UTF-8编码集合的数据也可以通过使用一种特殊的二进制数据类型来保存,查询。
- 跨平台支持:二进制文件可以在Windows,Linux,OS X和Solaris平台上使用。MongoDB可以在大多数小端系统上编译通过。
- 支持丰富的类型:支持 dates, regular expressions, code, binary data 等类型。
- 查询结果支持Cursor操作。
- 支持Ad hoc queries(Ad hoc query:即席查询,数据库应用最普遍的一种查询,利用数据仓库技术,可以让用户随时可以面对数据库,获取所希望的数据。在MongoDB中,可以在任何时候查询任何一个field。它支持 range queries,regular expression searches 和其他特殊的查询类型。同时查询也可以包含用户定义的javascript函数。
- 支持嵌套域的查询:查询可以深入到嵌套的对象和数组中,如果下面的对象被插入到users集合。
- 支持索引:支持二级索引包括 single-key, compound, unique, non-unique, geospatial indexes.嵌套的域同样也可以被索引。如果我们对一个数组类型进行索引,那么数组中所有元素也会自动被索引。当一个查询执行时,MongoDB的查询优化器会尝试多个不同的query plan,并选择执行速度最快的。开发者可以通过explain功能看到索引被使用的过程,然后可以通过hint功能来选择另一个不同的索引。可以在任何时候创建和删除索引。
- aggregation:除了ad hoc queries外,MongoDB还支持一系列工具来支持聚合,例如MapReduce和其他类似于SQL的GROUP BY的函数集合。
- 文件存储:该软件实现了一个称为GridFS的协议,这个协议是用来帮助从数据库中存储和获取文件的。
- 支持服务器端javascript执行:javaScript是MongoDB的一种通用语言,它可以被用在查询,聚集函数,直接由数据库执行。
- capped collection:MongoDB支持被称为capped collections(定量集合)的定长集合。Capped collections是唯一一种维持插入顺序的集合,其中,如果达到容量最大值,那么就会覆盖第一个元素,也就是说capped collection的行为类似于一个环形队列。一种特殊的cursor类型,称为tailable cursor,可以被用在capped collection上,当完成结果返回时,这种cursor不会关闭,而是会继续等待更多的结果来返回。也就是说如果有新的记录插入到capped collection的话,cursor会自动返回。
- 目前提供多种语言的driver。
- 部署:MongoDB使用的是memory-mapped files(内存映射文件),所以在32位机器上限制数据的最大大小为2GB,同时MongoDB服务器只能在小端系统上运行。
- Replication:MongoDB不应被部署到少于两台的服务器上,也就是说至少有一台作为master,另一台作为slave。Master可以用来执行读写,而slave可以从master上复制数据,但是它只能执行读操作或备份操作。开发者可以根据情况让一个operation可以被replicate到多个servers上。
{
"username" : "bob",
"address" : {
"street" : "123 Main Street",
"city" : "Springfield",
"state" : "NY"
}
}
我们可以这样查询嵌套在里层的域:db.users.find({“address.state”:"NY”})
数组元素则可以被这样查询:> db.food.insert({"fruit" : ["peach", "plum", "pear"]})或> db.food.find({"fruit" : "pear"})
下面是一个使用javascript的查询例子:db.foo.find({$where:function(){return this.x==this.y;}})
发送代码到数据库执行:db.eval(function(name){return “Hello, ”+name;},[“Joe”])
javaScript的变量可以被存储在数据库中并被其他javas作为全局变量使用。任何合法的javascript类型包括函数和对象,都可以被存储在MongoDB中,所以javascript可以被用来写<存储过程>
下面的代码是启动一个master服务器和对应的slave服务器:
$ mkdir –p ~/dbs/master ~/dbs/slave $ ./mongod –master –port 10000 –dbpath ~/dbs/master $ ./mongod –slave --port10001 –dbpath ~/dbs/slave -- source localhost:10000
补充知识
所谓“面向集合”(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
MongoDB把数据存储在文件中(默认路径为:/data/db),为提高效率使用内存映射文件进行管理。MongoDB的主要目标是在键/值存储方式(提供了高性能和高度伸缩性)以及传统的RDBMS系统(丰富的功能)架起一座桥梁,集两者的优势于一身。
根据官方网站的描述,Mongo适合用于以下场景:
- 网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
- 缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载。
- 大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
- 高伸缩性的场景:Mongo非常适合由数十或数百台服务器组成的数据库。Mongo的路线图中已经包含对MapReduce引擎的内置支持。
- 用于对象及JSON数据的存储:Mongo的BSON数据格式非常适合文档化格式的存储及查询。
自然,MongoDB的使用也会有一些限制,例如它不适合:
- 高度事务性的系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
- 传统的商业智能应用:针对特定问题的BI数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
- 需要SQL的问题

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 AI sedang digunakan |. AI mencipta vlog kehidupan seorang gadis yang tinggal bersendirian, yang menerima berpuluh ribu suka dalam masa 3 hari
Aug 07, 2024 pm 10:53 PM
AI sedang digunakan |. AI mencipta vlog kehidupan seorang gadis yang tinggal bersendirian, yang menerima berpuluh ribu suka dalam masa 3 hari
Aug 07, 2024 pm 10:53 PM
Editor Laporan Kuasa Mesin: Yang Wen Gelombang kecerdasan buatan yang diwakili oleh model besar dan AIGC telah mengubah cara kita hidup dan bekerja secara senyap-senyap, tetapi kebanyakan orang masih tidak tahu cara menggunakannya. Oleh itu, kami telah melancarkan lajur "AI dalam Penggunaan" untuk memperkenalkan secara terperinci cara menggunakan AI melalui kes penggunaan kecerdasan buatan yang intuitif, menarik dan padat serta merangsang pemikiran semua orang. Kami juga mengalu-alukan pembaca untuk menyerahkan kes penggunaan yang inovatif dan praktikal. Pautan video: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Baru-baru ini, vlog kehidupan seorang gadis yang tinggal bersendirian menjadi popular di Xiaohongshu. Animasi gaya ilustrasi, ditambah dengan beberapa perkataan penyembuhan, boleh diambil dengan mudah dalam beberapa hari sahaja.
 Tsinghua Optik AI muncul dalam Alam Semula Jadi! Rangkaian saraf fizikal, perambatan belakang tidak lagi diperlukan
Aug 10, 2024 pm 10:15 PM
Tsinghua Optik AI muncul dalam Alam Semula Jadi! Rangkaian saraf fizikal, perambatan belakang tidak lagi diperlukan
Aug 10, 2024 pm 10:15 PM
Menggunakan cahaya untuk melatih rangkaian saraf, keputusan Universiti Tsinghua diterbitkan baru-baru ini dalam Nature! Apakah yang perlu saya lakukan jika saya tidak boleh menggunakan algoritma perambatan balik? Mereka mencadangkan kaedah latihan Mod Hadapan Penuh (FFM) yang secara langsung melaksanakan proses latihan dalam sistem optik fizikal, mengatasi batasan simulasi komputer digital tradisional. Ringkasnya, dahulunya adalah perlu untuk memodelkan sistem fizikal secara terperinci dan kemudian mensimulasikan model ini pada komputer untuk melatih rangkaian. Kaedah FFM menghapuskan proses pemodelan dan membenarkan sistem menggunakan data percubaan secara langsung untuk pembelajaran dan pengoptimuman. Ini juga bermakna latihan tidak lagi perlu menyemak setiap lapisan dari belakang ke hadapan (backpropagation), tetapi boleh terus mengemas kini parameter rangkaian dari hadapan ke belakang. Untuk menggunakan analogi, seperti teka-teki, penyebaran belakang
 Mengapa saya tidak tahu semasa saya belajar penjanaan garis: Terdapat hubungan kesetaraan antara matriks dan graf?
Aug 19, 2024 pm 04:52 PM
Mengapa saya tidak tahu semasa saya belajar penjanaan garis: Terdapat hubungan kesetaraan antara matriks dan graf?
Aug 19, 2024 pm 04:52 PM
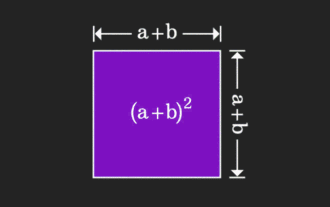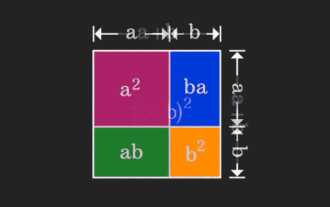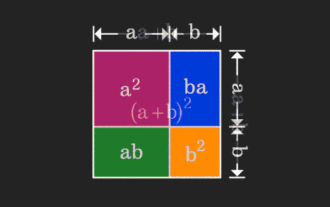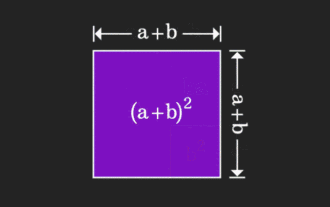
Matriks ini sukar difahami, tetapi ia mungkin berbeza jika anda melihatnya dari perspektif lain. Apabila belajar matematik, kita sering kecewa dengan kesukaran dan keabstrakan pengetahuan yang kita pelajari, tetapi kadang-kadang, hanya dengan mengubah perspektif, kita boleh mencari penyelesaian yang mudah dan intuitif untuk masalah itu. Sebagai contoh, semasa kita mempelajari formula untuk jumlah kuasa dua (a+b)² semasa kita masih kanak-kanak, kita mungkin tidak faham mengapa ia sama dengan a²+2ab+b² Kita hanya tahu bahawa ia ditulis seperti ini dalam buku dan guru meminta kami mengingatnya seperti ini; sehingga satu hari kami melihat saya melihat gambar animasi ini: Tiba-tiba saya sedar bahawa kita boleh memahaminya dari perspektif geometri! Sekarang, rasa pencerahan ini berlaku sekali lagi: matriks bukan negatif boleh ditukar secara sama kepada graf terarah yang sepadan! Seperti yang ditunjukkan dalam rajah di bawah, matriks 3×3 di sebelah kiri sebenarnya boleh
 Cara mengkonfigurasi pengembangan automatik MongoDB pada Debian
Apr 02, 2025 am 07:36 AM
Cara mengkonfigurasi pengembangan automatik MongoDB pada Debian
Apr 02, 2025 am 07:36 AM
Artikel ini memperkenalkan cara mengkonfigurasi MongoDB pada sistem Debian untuk mencapai pengembangan automatik. Langkah -langkah utama termasuk menubuhkan set replika MongoDB dan pemantauan ruang cakera. 1. Pemasangan MongoDB Pertama, pastikan MongoDB dipasang pada sistem Debian. Pasang menggunakan arahan berikut: SudoaptDateSudoaptInstall-ImongoDB-Org 2. Mengkonfigurasi set replika replika MongoDB MongoDB Set memastikan ketersediaan dan kelebihan data yang tinggi, yang merupakan asas untuk mencapai pengembangan kapasiti automatik. Mula MongoDB Service: sudosystemctlstartmongodsudosys
 Cara Memastikan Ketersediaan MongoDB Tinggi di Debian
Apr 02, 2025 am 07:21 AM
Cara Memastikan Ketersediaan MongoDB Tinggi di Debian
Apr 02, 2025 am 07:21 AM
Artikel ini menerangkan cara membina pangkalan data MongoDB yang sangat tersedia pada sistem Debian. Kami akan meneroka pelbagai cara untuk memastikan keselamatan data dan perkhidmatan terus beroperasi. Strategi Utama: Replicaset: Replicaset: Gunakan replika untuk mencapai redundansi data dan failover automatik. Apabila nod induk gagal, set replika secara automatik akan memilih nod induk baru untuk memastikan ketersediaan perkhidmatan yang berterusan. Sandaran dan Pemulihan Data: Secara kerap Gunakan perintah Mongodump untuk membuat sandaran pangkalan data dan merumuskan strategi pemulihan yang berkesan untuk menangani risiko kehilangan data. Pemantauan dan penggera: Menyebarkan alat pemantauan (seperti Prometheus, Grafana) untuk memantau status MongoDB dalam masa nyata, dan
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Apakah strategi sandaran CentOS MongoDB?
Apr 14, 2025 pm 04:51 PM
Apakah strategi sandaran CentOS MongoDB?
Apr 14, 2025 pm 04:51 PM
Penjelasan terperinci mengenai strategi sandaran yang cekap MongoDB di bawah sistem CentOS Artikel ini akan memperkenalkan secara terperinci pelbagai strategi untuk melaksanakan sandaran MongoDB pada sistem CentOS untuk memastikan kesinambungan data dan kesinambungan perniagaan. Kami akan merangkumi sandaran manual, sandaran masa, sandaran skrip automatik, dan kaedah sandaran dalam persekitaran kontena Docker, dan menyediakan amalan terbaik untuk pengurusan fail sandaran. Sandaran Manual: Gunakan perintah Mongodump untuk melakukan sandaran penuh manual, contohnya: Mongodump-Hlocalhost: 27017-U Pengguna-P Password-D Database Data-O/Backup Direktori Perintah ini akan mengeksport data dan metadata pangkalan data yang ditentukan ke direktori sandaran yang ditentukan.
 Kemas kini utama Pi Coin: Pi Bank akan datang!
Mar 03, 2025 pm 06:18 PM
Kemas kini utama Pi Coin: Pi Bank akan datang!
Mar 03, 2025 pm 06:18 PM
Pinetwork akan melancarkan Pibank, platform perbankan mudah alih revolusioner! Pinetwork hari ini mengeluarkan kemas kini utama mengenai Pimisrbank Elmahrosa (muka), yang disebut sebagai Pibank, yang mengintegrasikan dengan baik perkhidmatan perbankan tradisi C). Apakah pesona Pibank? Mari kita cari! Fungsi utama Pibank: Pengurusan sehenti akaun bank dan aset cryptocurrency. Menyokong urus niaga masa nyata dan mengamalkan biospesies
