

伪分布式安装部署CDH4.2.1与Impala[原创实践]

参考资料: http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing
参考资料:
http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/latest/CDH4-Quick-Start/cdh4qs_topic_3_3.html
http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Using-Impala/Installing-and-Using-Impala.html
http://blog.cloudera.com/blog/2013/02/from-zero-to-impala-in-minutes/
什么是Impala?
Cloudera发布了实时查询开源项目Impala,根据多款产品实测表明,它比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。
1. 安装JDK
$ sudo yum install jdk-6u41-linux-amd64.rpm
2. 伪分布式模式安装CDH4
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/cloudera-cdh4.repo
$ sudo yum install hadoop-conf-pseudo
格式化NameNode.
$ sudo -u hdfs hdfs namenode -format
启动HDFS
$ for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
创建/tmp目录
$ sudo -u hdfs hadoop fs -rm -r /tmp
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
创建YARN与日志目录
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chmod -R 1777 /tmp/hadoop-yarn/staging/history/done_intermediate
$ sudo -u hdfs hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn/staging
$ sudo -u hdfs hadoop fs -mkdir /var/log/hadoop-yarn
$ sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
检查HDFS文件树
$ sudo -u hdfs hadoop fs -ls -R /
drwxrwxrwt - hdfs supergroup 0 2012-05-31 15:31 /tmp drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /tmp/hadoop-yarn drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging drwxr-xr-x - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history drwxrwxrwt - mapred mapred 0 2012-05-31 15:31 /tmp/hadoop-yarn/staging/history/done_intermediate drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var drwxr-xr-x - hdfs supergroup 0 2012-05-31 15:31 /var/log drwxr-xr-x - yarn mapred 0 2012-05-31 15:31 /var/log/hadoop-yarn
启动YARN
$ sudo service hadoop-yarn-resourcemanager start
$ sudo service hadoop-yarn-nodemanager start
$ sudo service hadoop-mapreduce-historyserver start
创建用户目录(以用户dong.guo为例):
$ sudo -u hdfs hadoop fs -mkdir /user/dong.guo
$ sudo -u hdfs hadoop fs -chown dong.guo /user/dong.guo
测试上传文件
$ hadoop fs -mkdir input
$ hadoop fs -put /etc/hadoop/conf/*.xml input
$ hadoop fs -ls input
Found 4 items -rw-r--r-- 1 dong.guo supergroup 1461 2013-05-14 03:30 input/core-site.xml -rw-r--r-- 1 dong.guo supergroup 1854 2013-05-14 03:30 input/hdfs-site.xml -rw-r--r-- 1 dong.guo supergroup 1325 2013-05-14 03:30 input/mapred-site.xml -rw-r--r-- 1 dong.guo supergroup 2262 2013-05-14 03:30 input/yarn-site.xml
配置HADOOP_MAPRED_HOME环境变量
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
运行一个测试Job
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input output23 'dfs[a-z.]+'
Job完成后,可以看到以下目录
$ hadoop fs -ls
Found 2 items drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:30 input drwxr-xr-x - dong.guo supergroup 0 2013-05-14 03:32 output23
$ hadoop fs -ls output23
Found 2 items -rw-r--r-- 1 dong.guo supergroup 0 2013-05-14 03:32 output23/_SUCCESS -rw-r--r-- 1 dong.guo supergroup 150 2013-05-14 03:32 output23/part-r-00000
$ hadoop fs -cat output23/part-r-00000 | head
1 dfs.safemode.min.datanodes 1 dfs.safemode.extension 1 dfs.replication 1 dfs.namenode.name.dir 1 dfs.namenode.checkpoint.dir 1 dfs.datanode.data.dir
3. 安装 Hive
$ sudo yum install hive hive-metastore hive-server
$ sudo yum install mysql-server
$ sudo service mysqld start
$ cd ~
$ wget 'http://cdn.mysql.com/Downloads/Connector-J/mysql-connector-java-5.1.25.tar.gz'
$ tar xzf mysql-connector-java-5.1.25.tar.gz
$ sudo cp mysql-connector-java-5.1.25/mysql-connector-java-5.1.25-bin.jar /usr/lib/hive/lib/
$ sudo /usr/bin/mysql_secure_installation
[...] Enter current password for root (enter for none): OK, successfully used password, moving on... [...] Set root password? [Y/n] y New password:hadoophive Re-enter new password:hadoophive Remove anonymous users? [Y/n] Y [...] Disallow root login remotely? [Y/n] N [...] Remove test database and access to it [Y/n] Y [...] Reload privilege tables now? [Y/n] Y All done!
$ mysql -u root -phadoophive
mysql> CREATE DATABASE metastore; mysql> USE metastore; mysql> SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/hive-schema-0.10.0.mysql.sql; mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hadoophive'; mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hadoophive'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'%'; mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'hive'@'localhost'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'%'; mysql> GRANT SELECT,INSERT,UPDATE,DELETE,LOCK TABLES,EXECUTE ON metastore.* TO 'hive'@'localhost'; mysql> FLUSH PRIVILEGES; mysql> quit;
$ sudo mv /etc/hive/conf/hive-site.xml /etc/hive/conf/hive-site.xml.bak
$ sudo vim /etc/hive/conf/hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://heylinux.com/archives/configuration.xsl"?> javax.jdo.option.ConnectionURL jdbc:mysql://localhost/metastore the URL of the MySQL database javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName hive javax.jdo.option.ConnectionPassword hadoophive datanucleus.autoCreateSchema false datanucleus.fixedDatastore true hive.metastore.uris thrift://127.0.0.1:9083 IP address (or fully-qualified domain name) and port of the metastore host hive.aux.jars.path file:///usr/lib/hive/lib/zookeeper.jar,file:///usr/lib/hive/lib/hbase.jar,file:///usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar,file:///usr/lib/hive/lib/guava-11.0.2.jar
$ sudo service hive-metastore start
Starting (hive-metastore): [ OK ]
$ sudo service hive-server start
Starting (hive-server): [ OK ]
$ sudo -u hdfs hadoop fs -mkdir /user/hive
$ sudo -u hdfs hadoop fs -chown hive /user/hive
$ sudo -u hdfs hadoop fs -mkdir /tmp
$ sudo -u hdfs hadoop fs -chmod 777 /tmp
$ sudo -u hdfs hadoop fs -chmod o+t /tmp
$ sudo -u hdfs hadoop fs -mkdir /data
$ sudo -u hdfs hadoop fs -chown hdfs /data
$ sudo -u hdfs hadoop fs -chmod 777 /data
$ sudo -u hdfs hadoop fs -chmod o+t /data
$ sudo chown -R hive:hive /var/lib/hive
$ sudo vim /tmp/kv1.txt
1 www.baidu.com 2 www.google.com 3 www.sina.com.cn 4 www.163.com 5 heylinx.com
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties Hive history file=/tmp/root/hive_job_log_root_201305140801_825709760.txt hive> CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; hive> show tables; OK pokes Time taken: 0.415 seconds hive> LOAD DATA LOCAL INPATH '/tmp/kv1.txt' OVERWRITE INTO TABLE pokes; Copying data from file:/tmp/kv1.txt Copying file: file:/tmp/kv1.txt Loading data to table default.pokes rmr: DEPRECATED: Please use 'rm -r' instead. Deleted /user/hive/warehouse/pokes Table default.pokes stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 79, raw_data_size: 0] OK Time taken: 1.681 seconds
$ export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
4. 安装 Impala
$ cd /etc/yum.repos.d/
$ sudo wget http://archive.cloudera.com/impala/redhat/6/x86_64/impala/cloudera-impala.repo
$ sudo yum install impala impala-shell
$ sudo yum install impala-server impala-state-store
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
... dfs.client.read.shortcircuit true dfs.domain.socket.path /var/run/hadoop-hdfs/dn._PORT dfs.client.file-block-storage-locations.timeout 3000 dfs.datanode.hdfs-blocks-metadata.enabled true
$ sudo cp -rpa /etc/hadoop/conf/core-site.xml /etc/impala/conf/
$ sudo cp -rpa /etc/hadoop/conf/hdfs-site.xml /etc/impala/conf/
$ sudo service hadoop-hdfs-datanode restart
$ sudo service impala-state-store restart
$ sudo service impala-server restart
$ sudo /usr/java/default/bin/jps
5. 安装 Hbase
$ sudo yum install hbase
$ sudo vim /etc/security/limits.conf
hdfs - nofile 32768 hbase - nofile 32768
$ sudo vim /etc/pam.d/common-session
session required pam_limits.so
$ sudo vim /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.max.xcievers 4096
$ sudo cp /usr/lib/impala/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar /usr/lib/hive/lib/hive-hbase-handler-0.10.0-cdh4.2.0.jar
$ sudo /etc/init.d/hadoop-hdfs-namenode restart
$ sudo /etc/init.d/hadoop-hdfs-datanode restart
$ sudo yum install hbase-master
$ sudo service hbase-master start
$ sudo -u hive hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
Hive history file=/tmp/hive/hive_job_log_hive_201305140905_2005531704.txt
hive> CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
OK
Time taken: 3.587 seconds
hive> INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes WHERE foo=5;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1368502088579_0004, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0004/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0004
Hadoop job information for Stage-0: number of mappers: 1; number of reducers: 0
2013-05-14 09:12:45,340 Stage-0 map = 0%, reduce = 0%
2013-05-14 09:12:53,165 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 2.63 sec
MapReduce Total cumulative CPU time: 2 seconds 630 msec
Ended Job = job_1368502088579_0004
1 Rows loaded to hbase_table_1
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 2.63 sec HDFS Read: 288 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 630 msec
OK
Time taken: 21.063 seconds
hive> select * from hbase_table_1;
OK
5 heylinx.com
Time taken: 0.685 seconds
hive> SELECT COUNT (*) FROM pokes;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_1368502088579_0005, Tracking URL = http://ip-10-197-10-4:8088/proxy/application_1368502088579_0005/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1368502088579_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2013-05-14 10:32:04,711 Stage-1 map = 0%, reduce = 0%
2013-05-14 10:32:11,461 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:12,554 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:13,642 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:14,760 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:15,918 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:16,991 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:18,111 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.22 sec
2013-05-14 10:32:19,188 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.04 sec
MapReduce Total cumulative CPU time: 4 seconds 40 msec
Ended Job = job_1368502088579_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 4.04 sec HDFS Read: 288 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 40 msec
OK
5
Time taken: 28.195 seconds
</number></number></number>6. 测试Impala性能
View parameters on http://ec2-204-236-182-78.us-west-1.compute.amazonaws.com:25000
$ impala-shell
[ip-10-197-10-4.us-west-1.compute.internal:21000] > CREATE TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n"; Query: create TABLE IF NOT EXISTS pokes ( foo INT,bar STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LINES TERMINATED BY "\n" [ip-10-197-10-4.us-west-1.compute.internal:21000] > show tables; Query: show tables Query finished, fetching results ... +-------+ | name | +-------+ | pokes | +-------+ Returned 1 row(s) in 0.00s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT * from pokes; Query: select * from pokes Query finished, fetching results ... +-----+-----------------+ | foo | bar | +-----+-----------------+ | 1 | www.baidu.com | | 2 | www.google.com | | 3 | www.sina.com.cn | | 4 | www.163.com | | 5 | heylinx.com | +-----+-----------------+ Returned 5 row(s) in 0.28s [ip-10-197-10-4.us-west-1.compute.internal:21000] > SELECT COUNT (*) from pokes; Query: select COUNT (*) from pokes Query finished, fetching results ... +----------+ | count(*) | +----------+ | 5 | +----------+ Returned 1 row(s) in 0.34s
通过两个COUNT的结果来看,Hive使用了 28.195 seconds 而 Impala仅使用了0.34s,由此可以看出Impala的性能确实要优于Hive。
原文地址:伪分布式安装部署CDH4.2.1与Impala[原创实践], 感谢原作者分享。

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Penyelesaian kepada masalah bahawa sistem Win11 tidak dapat memasang pek bahasa Cina
Mar 09, 2024 am 09:48 AM
Penyelesaian kepada masalah bahawa sistem Win11 tidak dapat memasang pek bahasa Cina
Mar 09, 2024 am 09:48 AM
Penyelesaian kepada masalah sistem Win11 tidak dapat memasang pek bahasa Cina Dengan pelancaran sistem Windows 11, ramai pengguna mula menaik taraf sistem pengendalian mereka untuk mengalami fungsi dan antara muka baharu. Walau bagaimanapun, sesetengah pengguna mendapati bahawa mereka tidak dapat memasang pek bahasa Cina selepas menaik taraf, yang menyusahkan pengalaman mereka. Dalam artikel ini, kami akan membincangkan sebab mengapa sistem Win11 tidak dapat memasang pek bahasa Cina dan menyediakan beberapa penyelesaian untuk membantu pengguna menyelesaikan masalah ini. Analisis sebab Pertama, mari kita menganalisis ketidakupayaan sistem Win11 untuk
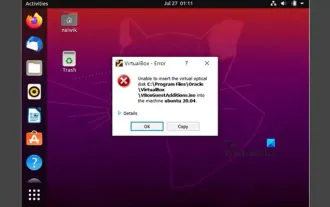 Tidak dapat memasang tambahan tetamu dalam VirtualBox
Mar 10, 2024 am 09:34 AM
Tidak dapat memasang tambahan tetamu dalam VirtualBox
Mar 10, 2024 am 09:34 AM
Anda mungkin tidak dapat memasang tambahan tetamu pada mesin maya dalam OracleVirtualBox. Apabila kita mengklik pada Devices>InstallGuestAdditionsCDImage, ia hanya membuang ralat seperti yang ditunjukkan di bawah: VirtualBox - Ralat: Tidak dapat memasukkan cakera maya C: Programming FilesOracleVirtualBoxVBoxGuestAdditions.iso ke dalam mesin ubuntu Dalam siaran ini kita akan memahami apa yang berlaku apabila anda Apa yang perlu dilakukan apabila anda tidak boleh memasang tambahan tetamu dalam VirtualBox. Tidak dapat memasang tambahan tetamu dalam VirtualBox Jika anda tidak boleh memasangnya dalam Virtua
 Apakah yang perlu saya lakukan jika Baidu Netdisk berjaya dimuat turun tetapi tidak boleh dipasang?
Mar 13, 2024 pm 10:22 PM
Apakah yang perlu saya lakukan jika Baidu Netdisk berjaya dimuat turun tetapi tidak boleh dipasang?
Mar 13, 2024 pm 10:22 PM
Jika anda telah berjaya memuat turun fail pemasangan Baidu Netdisk, tetapi tidak dapat memasangnya seperti biasa, mungkin terdapat ralat dalam integriti fail perisian atau terdapat masalah dengan baki fail dan entri pendaftaran Biarkan tapak ini mengambil jaga ia untuk pengguna Mari perkenalkan analisis masalah yang Baidu Netdisk berjaya dimuat turun tetapi tidak boleh dipasang. Analisis masalah yang berjaya dimuat turun oleh Baidu Netdisk tetapi tidak dapat dipasang 1. Semak integriti fail pemasangan: Pastikan fail pemasangan yang dimuat turun lengkap dan tidak rosak. Anda boleh memuat turunnya semula atau cuba memuat turun fail pemasangan daripada sumber lain yang dipercayai. 2. Matikan perisian anti-virus dan tembok api: Sesetengah perisian anti-virus atau program tembok api mungkin menghalang program pemasangan daripada berjalan dengan betul. Cuba lumpuhkan atau keluar dari perisian anti-virus dan tembok api, kemudian jalankan semula pemasangan
 Bagaimana untuk memasang apl Android pada Linux?
Mar 19, 2024 am 11:15 AM
Bagaimana untuk memasang apl Android pada Linux?
Mar 19, 2024 am 11:15 AM
Memasang aplikasi Android di Linux sentiasa menjadi kebimbangan ramai pengguna Terutamanya bagi pengguna Linux yang suka menggunakan aplikasi Android, adalah sangat penting untuk menguasai cara memasang aplikasi Android pada sistem Linux. Walaupun menjalankan aplikasi Android secara langsung pada Linux tidak semudah pada platform Android, dengan menggunakan emulator atau alatan pihak ketiga, kami masih boleh menikmati aplikasi Android di Linux dengan gembira. Berikut akan memperkenalkan cara memasang aplikasi Android pada sistem Linux.
 Bagaimana untuk memasang Podman pada Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
Bagaimana untuk memasang Podman pada Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
Jika anda telah menggunakan Docker, anda mesti memahami daemon, bekas dan fungsinya. Daemon ialah perkhidmatan yang berjalan di latar belakang apabila bekas sudah digunakan dalam mana-mana sistem. Podman ialah alat pengurusan percuma untuk mengurus dan mencipta bekas tanpa bergantung pada mana-mana daemon seperti Docker. Oleh itu, ia mempunyai kelebihan dalam menguruskan kontena tanpa memerlukan perkhidmatan backend jangka panjang. Selain itu, Podman tidak memerlukan kebenaran peringkat akar untuk digunakan. Panduan ini membincangkan secara terperinci cara memasang Podman pada Ubuntu24. Untuk mengemas kini sistem, kami perlu mengemas kini sistem terlebih dahulu dan membuka shell Terminal Ubuntu24. Semasa kedua-dua proses pemasangan dan peningkatan, kita perlu menggunakan baris arahan. yang mudah
 Cara Memasang dan Menjalankan Apl Nota Ubuntu pada Ubuntu 24.04
Mar 22, 2024 pm 04:40 PM
Cara Memasang dan Menjalankan Apl Nota Ubuntu pada Ubuntu 24.04
Mar 22, 2024 pm 04:40 PM
Semasa belajar di sekolah menengah, sesetengah pelajar mengambil nota yang sangat jelas dan tepat, mengambil lebih banyak nota daripada yang lain dalam kelas yang sama. Bagi sesetengah orang, mencatat nota adalah hobi, manakala bagi yang lain, ia adalah satu keperluan apabila mereka mudah melupakan maklumat kecil tentang apa-apa perkara penting. Aplikasi NTFS Microsoft amat berguna untuk pelajar yang ingin menyimpan nota penting di luar kuliah biasa. Dalam artikel ini, kami akan menerangkan pemasangan aplikasi Ubuntu pada Ubuntu24. Mengemas kini Sistem Ubuntu Sebelum memasang pemasang Ubuntu, pada Ubuntu24 kita perlu memastikan bahawa sistem yang baru dikonfigurasikan telah dikemas kini. Kita boleh menggunakan "a" yang paling terkenal dalam sistem Ubuntu
 Langkah terperinci untuk memasang bahasa Go pada komputer Win7
Mar 27, 2024 pm 02:00 PM
Langkah terperinci untuk memasang bahasa Go pada komputer Win7
Mar 27, 2024 pm 02:00 PM
Langkah terperinci untuk memasang bahasa Go pada komputer Win7 Go (juga dikenali sebagai Golang) ialah bahasa pengaturcaraan sumber terbuka yang dibangunkan oleh Google Ia mudah, cekap dan mempunyai prestasi serentak yang sangat baik Ia sesuai untuk pembangunan perkhidmatan awan, aplikasi rangkaian dan sistem hujung belakang. Memasang bahasa Go pada komputer Win7 membolehkan anda memulakan bahasa dengan cepat dan mula menulis program Go. Berikut akan memperkenalkan secara terperinci langkah-langkah untuk memasang bahasa Go pada komputer Win7, dan melampirkan contoh kod tertentu. Langkah 1: Muat turun pakej pemasangan bahasa Go dan lawati tapak web rasmi Go
 Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
Yolov10: Penjelasan terperinci, penggunaan dan aplikasi semuanya di satu tempat!
Jun 07, 2024 pm 12:05 PM
1. Pengenalan Sejak beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma dominan dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah meneroka reka bentuk seni bina YOLO, matlamat pengoptimuman, strategi pengembangan data, dsb., dan telah mencapai kemajuan yang ketara. Pada masa yang sama, bergantung pada penindasan bukan maksimum (NMS) untuk pemprosesan pasca menghalang penggunaan YOLO dari hujung ke hujung dan memberi kesan buruk kepada kependaman inferens. Dalam YOLO, reka bentuk pelbagai komponen tidak mempunyai pemeriksaan yang komprehensif dan teliti, mengakibatkan lebihan pengiraan yang ketara dan mengehadkan keupayaan model. Ia menawarkan kecekapan suboptimum, dan potensi yang agak besar untuk peningkatan prestasi. Dalam kerja ini, matlamatnya adalah untuk meningkatkan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. sampai habis
