

HDFS集中式的缓存管理原理与代码剖析

Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。 主要解决了哪些问题 1.用户可
Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。
主要解决了哪些问题
1.用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据常驻内存而不被淘汰到磁盘。例如在Hive或Impala构建的数据仓库应用中fact表会频繁地与其他表做JOIN,显然应该让fact常驻内存,这样DataNode在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于?mixed workloads的SLA。
2.centralized cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务,做到memory-locality。
3.HDFS原来单纯靠DataNode的OS buffer cache,这样不但没有把block被cache的分布情况对外暴露给上层应用优化任务调度,也有可能会造成cache浪费。例如一个block的三个replica分别存储在三个DataNote 上,有可能这个block同时被这三台DataNode的OS buffer cache,那么从HDFS的全局看就有同一个block在cache中存了三份,造成了资源浪费。?
4.加快HDFS client读速度。过去NameNode处理读请求时只根据拓扑远近决定去哪个DataNode读,现在还要加入speed的因素。当HDFS client和要读取的block被cache在同一台DataNode的时候,可以通过zero-copy read直接从内存读,略过磁盘I/O、checksum校验等环节。
5.即使数据被cache的DataNode节点宕机,block移动,集群重启,cache都不会受到影响。因为cache被NameNode统一管理并被被持久化到FSImage和EditLog,如果cache的某个block的DataNode宕机,NameNode会调度其他存储了这个replica的DataNode,把它cache到内存。
基本概念
cache directive: 表示要被cache到内存的文件或者目录。
cache pool: 用于管理一系列的cache directive,类似于命名空间。同时使用UNIX风格的文件读、写、执行权限管理机制。命令例子:
hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1?
以上代码表示把HDFS上的文件city(其实是hive上的一个fact表)放到HDFS centralized cache的financial这个cache pool下,而且这个文件只需要被缓存一份。
系统架构与原理
 用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
DFSClient读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给DFSClient,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
注:centralized cache和distributed cache的区别:
distributed cache将文件分发到各个DataNode结点本地磁盘保存,并且用完后并不会被立即清理的,而是由专门的一个线程根据文件大小限制和文件数目上限周期性进行清理。本质上distributed cache只做到了disk locality,而centralized cache做到了memory locality。
实现逻辑与代码剖析
HDFS centralized cache涉及到多个操作,其处理逻辑非常类似。为了简化问题,以addDirective这个操作为例说明。
1.NameNode处理逻辑
 NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
DFSClient给NameNode发送名为addCacheDirective的RPC, 在ClientNamenodeProtocol.proto这个文件中定义相应的接口。
NameNode接收到这个RPC之后处理,首先把这个需要被缓存的Path包装成CacheDirective加入CacheManager所管理的directivesByPath中。这时对应的File/Directory并没有被cache到内存。
一旦CacheManager那边添加了新的CacheDirective,触发CacheReplicationMonitor.rescan()来扫描并把需要通知DataNode做cache的block加入到CacheReplicationMonitor. cachedBlocks映射中。这个rescan操作在NameNode启动时也会触发,同时在NameNode运行期间以固定的时间间隔触发。
Rescan()函数主要逻辑如下:
rescanCacheDirectives()->rescanFile():依次遍历每个等待被cache的directive(存储在CacheManager. directivesByPath里),把每个等待被cache的directive包含的block都加入到CacheReplicationMonitor.cachedBlocks集合里面。
rescanCachedBlockMap():调用CacheReplicationMonitor.addNewPendingCached()为每个等待被cache的block选择一个合适的DataNode去cache(一般是选择这个block的三个replica所在的DataNode其中的剩余可用内存最多的一个),加入对应的DatanodeDescriptor的pendingCached列表。
2.NameNode与DataNode的RPC逻辑
DataNode定期向NameNode发送heartbeat RPC用于表明它还活着,同时DataNode还会向NameNode定期发送block report(默认6小时)和cache block(默认10秒)用于同步block和cache的状态。
NameNode会在每次处理某一DataNode的heartbeat RPC时顺便检查该DataNode的pendingCached列表是否为空,不为空的话发送DatanodeProtocol.DNA_CACHE命令给具体的DataNode去cache对应的block replica。
3.DataNode处理逻辑
 DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
在DataNode节点上每个BlockPool对应有一个BPServiceActor线程向NameNode发送heartbeat、接收response并处理。如果接收到来自NameNode的RPC里面的命令是DatanodeProtocol.DNA_CACHE,那么调用FsDatasetImpl.cacheBlock()把对应的block cache到内存。
这个函数先是通过RPC传过来的blockId找到其对应的FsVolumeImpl (因为执行cache block操作的线程cacheExecutor是绑定在对应的FsVolumeImpl里的);然后调用FsDatasetCache.cacheBlock()把这个block封装成MappableBlock加入到mappableBlockMap里统一管理起来,然后向对应的FsVolumeImpl.cacheExecutor线程池提交一个CachingTask异步任务(cache的过程是异步执行的)。
FsDatasetCache有个成员mappableBlockMap(HashMap)管理着这台DataNode的所有的MappableBlock及其状态(caching/cached/uncaching)。目前DataNode中”哪些block被cache到内存里了”也是只保存了soft state(和NameNode的block map一样),是DataNode向NameNode 发送heartbeat之后从NameNode那问回来的,没有持久化到DataNode本地硬盘。
CachingTask的逻辑: 调用MappableBlock.load()方法把对应的block从DataNode本地磁盘通过mmap映射到内存中,然后通过mlock锁定这块内存空间,并对这个映射到内存的block做checksum检验其完整性。这样对于memory-locality的DFSClient就可以通过zero-copy直接读内存中的block而不需要校验了。
4.DFSClient读逻辑:
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。?
当DFSClient和它要读取的block在同一台DataNode时,DFSClient可以跨过网络I/O直接从本地磁盘读取数据,这种读取数据的方式叫short circuit read。目前HDFS实现的short circuit read是通过共享内存获取要读的block在DataNode磁盘上文件的file descriptor(因为这样比传递文件目录更安全),然后直接用对应的file descriptor建立起本地磁盘输入流,所以目前的short circuit read也是一种zero-copy read。
增加了Centralized cache的HDFS的读接口并没有改变。DFSClient通过RPC获取LocatedBlock时里面多了个成员表示哪个DataNode把这个block cache到内存里面了。如果DFSClient和该block被cache的DataNode在一起,就可以通过zero-copy read大大提升读效率。而且即使在读取的过程中该block被uncache了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。?
对上层应用的影响
对于HDFS上的某个目录已经被addDirective缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于Hive/Impala式的应用非常有用。
HBase in-memory table:可以直接把某个HBase表的HFile放到centralized cache中,这会显著提高HBase的读性能,降低读请求延迟。
和Spark RDD的区别:多个RDD的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache中被cache的block一定是先写到磁盘上的,然后才能显式被cache到内存。也就是说只能cache读,不能cache写。
目前的centralized cache不是DFSClient读了谁就会把谁cache,而是需要DFSClient显式指定要cache谁,cache多长时间,淘汰谁。目前也没有类似LRU的置换策略,如果内存不够用的时候需要client显式去淘汰对应的directive到磁盘。
现在还没有跟YARN整合,需要用户自己调整好留给DataNode用于cache的内存和NodeManager的内存使用。
参考文献
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
https://issues.apache.org/jira/browse/HDFS-4949
原文地址:HDFS集中式的缓存管理原理与代码剖析, 感谢原作者分享。

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk melihat dan menyegarkan cache dns dalam Linux
Mar 07, 2024 am 08:43 AM
Bagaimana untuk melihat dan menyegarkan cache dns dalam Linux
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) ialah sistem yang digunakan di Internet untuk menukar nama domain kepada alamat IP yang sepadan. Dalam sistem Linux, cache DNS ialah mekanisme yang menyimpan hubungan pemetaan antara nama domain dan alamat IP secara tempatan, yang boleh meningkatkan kelajuan resolusi nama domain dan mengurangkan beban pada pelayan DNS. Caching DNS membolehkan sistem mendapatkan semula alamat IP dengan pantas apabila kemudiannya mengakses nama domain yang sama tanpa perlu mengeluarkan permintaan pertanyaan kepada pelayan DNS setiap kali, dengan itu meningkatkan prestasi dan kecekapan rangkaian. Artikel ini akan membincangkan dengan anda cara melihat dan memuat semula cache DNS pada Linux, serta butiran yang berkaitan dan kod sampel. Kepentingan Caching DNS Dalam sistem Linux, cache DNS memainkan peranan penting. kewujudannya
 Analisis fungsi dan prinsip nohup
Mar 25, 2024 pm 03:24 PM
Analisis fungsi dan prinsip nohup
Mar 25, 2024 pm 03:24 PM
Analisis peranan dan prinsip nohup Dalam sistem pengendalian seperti Unix dan Unix, nohup ialah arahan yang biasa digunakan yang digunakan untuk menjalankan arahan di latar belakang Walaupun pengguna keluar dari sesi semasa atau menutup tetingkap terminal, arahan itu boleh masih terus dilaksanakan. Dalam artikel ini, kami akan menganalisis fungsi dan prinsip arahan nohup secara terperinci. 1. Peranan nohup: Menjalankan arahan di latar belakang: Melalui arahan nohup, kita boleh membiarkan arahan yang berjalan lama terus dilaksanakan di latar belakang tanpa terjejas oleh pengguna yang keluar dari sesi terminal. Ini perlu dijalankan
 Mekanisme caching dan amalan aplikasi dalam pembangunan PHP
May 09, 2024 pm 01:30 PM
Mekanisme caching dan amalan aplikasi dalam pembangunan PHP
May 09, 2024 pm 01:30 PM
Dalam pembangunan PHP, mekanisme caching meningkatkan prestasi dengan menyimpan sementara data yang kerap diakses dalam memori atau cakera, dengan itu mengurangkan bilangan akses pangkalan data. Jenis cache terutamanya termasuk memori, fail dan cache pangkalan data. Caching boleh dilaksanakan dalam PHP menggunakan fungsi terbina dalam atau perpustakaan pihak ketiga, seperti cache_get() dan Memcache. Aplikasi praktikal biasa termasuk caching hasil pertanyaan pangkalan data untuk mengoptimumkan prestasi pertanyaan dan caching halaman output untuk mempercepatkan pemaparan. Mekanisme caching berkesan meningkatkan kelajuan tindak balas laman web, meningkatkan pengalaman pengguna dan mengurangkan beban pelayan.
 Cipta dan jalankan fail '.a' Linux
Mar 20, 2024 pm 04:46 PM
Cipta dan jalankan fail '.a' Linux
Mar 20, 2024 pm 04:46 PM
Bekerja dengan fail dalam sistem pengendalian Linux memerlukan penggunaan pelbagai arahan dan teknik yang membolehkan pembangun mencipta dan melaksanakan fail, kod, program, skrip dan perkara lain dengan cekap. Dalam persekitaran Linux, fail dengan sambungan ".a" mempunyai kepentingan yang besar sebagai perpustakaan statik. Perpustakaan ini memainkan peranan penting dalam pembangunan perisian, membolehkan pembangun mengurus dan berkongsi fungsi biasa dengan cekap merentas berbilang program. Untuk pembangunan perisian yang berkesan dalam persekitaran Linux, adalah penting untuk memahami cara mencipta dan menjalankan fail ".a". Artikel ini akan memperkenalkan cara memasang dan mengkonfigurasi fail ".a" Linux secara menyeluruh Mari kita terokai definisi, tujuan, struktur dan kaedah mencipta dan melaksanakan fail ".a" Linux. Apa itu L
 Universiti Tsinghua dan sumber terbuka Zhipu AI GLM-4: melancarkan revolusi baharu dalam pemprosesan bahasa semula jadi
Jun 12, 2024 pm 08:38 PM
Universiti Tsinghua dan sumber terbuka Zhipu AI GLM-4: melancarkan revolusi baharu dalam pemprosesan bahasa semula jadi
Jun 12, 2024 pm 08:38 PM
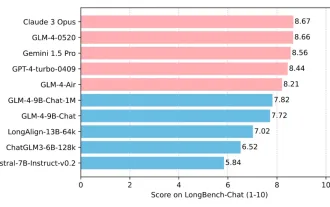
Sejak pelancaran ChatGLM-6B pada 14 Mac 2023, model siri GLM telah mendapat perhatian dan pengiktirafan yang meluas. Terutama selepas ChatGLM3-6B menjadi sumber terbuka, pembangun penuh dengan jangkaan untuk model generasi keempat yang dilancarkan oleh Zhipu AI. Jangkaan ini akhirnya telah berpuas hati sepenuhnya dengan keluaran GLM-4-9B. Kelahiran GLM-4-9B Untuk memberikan model kecil (10B dan ke bawah) keupayaan yang lebih berkuasa, pasukan teknikal GLM melancarkan model sumber terbuka siri GLM generasi keempat baharu ini: GLM-4-9B selepas hampir setengah tahun penerokaan. Model ini sangat memampatkan saiz model sambil memastikan ketepatan, dan mempunyai kelajuan inferens yang lebih pantas dan kecekapan yang lebih tinggi. Penerokaan pasukan teknikal GLM tidak
 Hubungan antara CPU, memori dan cache dijelaskan secara terperinci!
Mar 07, 2024 am 08:30 AM
Hubungan antara CPU, memori dan cache dijelaskan secara terperinci!
Mar 07, 2024 am 08:30 AM
Terdapat interaksi rapat antara CPU (unit pemprosesan pusat), memori (memori akses rawak), dan cache, yang bersama-sama membentuk komponen kritikal sistem komputer. Penyelarasan antara mereka memastikan operasi normal dan prestasi komputer yang cekap. Sebagai otak komputer, CPU bertanggungjawab untuk melaksanakan pelbagai arahan dan pemprosesan data, memori digunakan untuk menyimpan data dan program sementara, menyediakan kelajuan akses baca dan tulis yang cepat dan cache memainkan peranan penampan, mempercepatkan akses data; kelajuan dan peningkatan CPU komputer ialah komponen teras komputer dan bertanggungjawab untuk melaksanakan pelbagai arahan, operasi aritmetik dan operasi logik. Ia dipanggil "otak" komputer dan memainkan peranan penting dalam memproses data dan melaksanakan tugas. Memori adalah peranti storan penting dalam komputer.
 Buat Ejen dalam satu ayat! Robin Li: Era akan datang apabila semua orang adalah pemaju
Apr 17, 2024 pm 02:28 PM
Buat Ejen dalam satu ayat! Robin Li: Era akan datang apabila semua orang adalah pemaju
Apr 17, 2024 pm 02:28 PM
Model besar mengubah segala-galanya, dan akhirnya sampai kepada ketua editor ini. Ia juga merupakan Agen yang dicipta hanya dalam satu ayat. Seperti ini, berikan dia artikel, dan dalam masa kurang dari 1 saat, cadangan tajuk baru akan keluar. Berbanding dengan saya, kecekapan ini hanya boleh dikatakan sepantas kilat dan lambat seperti kemalasan... Apa yang lebih luar biasa ialah mencipta Ejen ini hanya mengambil masa beberapa minit sahaja. Prompt adalah milik Mak Cik Jiang: Dan jika anda juga ingin mengalami perasaan subversif ini, kini, berdasarkan platform pintar Wenxin baharu yang dilancarkan oleh Baidu, semua orang boleh mencipta pembantu pintar mereka sendiri secara percuma. Anda boleh menggunakan enjin carian, platform perkakasan pintar, pengecaman pertuturan, peta, kereta dan saluran ekologi mudah alih Baidu yang lain untuk membolehkan lebih ramai orang menggunakan kreativiti anda! Robin Li sendiri
 Model kod sumber terbuka Mistral mengambil takhta! Codestral tergila-gila dengan latihan dalam lebih 80 bahasa, dan pembangun Tongyi domestik meminta untuk mengambil bahagian!
Jun 08, 2024 pm 09:55 PM
Model kod sumber terbuka Mistral mengambil takhta! Codestral tergila-gila dengan latihan dalam lebih 80 bahasa, dan pembangun Tongyi domestik meminta untuk mengambil bahagian!
Jun 08, 2024 pm 09:55 PM
Dihasilkan oleh tindanan teknologi 51CTO (WeChat ID: blog51cto) Mistral mengeluarkan model kod pertamanya Codestral-22B! Apa yang menggilakan model ini bukan sahaja kerana ia dilatih dalam lebih 80 bahasa pengaturcaraan, termasuk Swift, dll. yang banyak model kod diabaikan. Kelajuan mereka tidak sama. Ia dikehendaki menulis sistem "terbit/langgan" menggunakan bahasa Go. GPT-4o di sini sedang dikeluarkan, dan Codestral menyerahkan kertas dengan pantas sehingga sukar untuk dilihat! Memandangkan model itu baru sahaja dilancarkan, ia masih belum diuji secara terbuka. Tetapi menurut orang yang bertanggungjawab ke atas Mistral, Codestral kini merupakan model kod sumber terbuka yang berprestasi terbaik. Rakan-rakan yang berminat dengan gambar boleh bergerak ke: - Peluk muka: https
