

SQL中对于求表记录总数的有count这个聚合命令,这个命令给我们感觉就是快,比一般的查询要快,但是,当你的数据表记录比较多时,如百万条,千万条时,对于count来说,就不是那么快了,我们需要掌握一些技巧,来优化这个count。 有人说: select count(1)
SQL中对于求表记录总数的有count这个聚合命令,这个命令给我们感觉就是快,比一般的查询要快,但是,当你的数据表记录比较多时,如百万条,千万条时,对于count来说,就不是那么快了,我们需要掌握一些技巧,来优化这个count。
有人说:
select count(1) from table
select count(primarykey) from table
比较快,一定不要用
select count(*) from table
可我要说的是,count(*)更快一些,为什么呢,count(*)是什么意思?事实上,它真正的含义是找一个占用空间最小的索引字段,然后对它进行记数,不要一看到*就认为“大”,在count命令中,它指的是“任意一个“。
对于一个大表来说,如果你的字段有bit类型,,如性别字段,表示真假关系的字段,我们需要为它加上索引,加上之后,我们的count速度就提交几十倍,真的,呵呵
首先为我们的bit类型字段加索引IsSync添加聚集索引
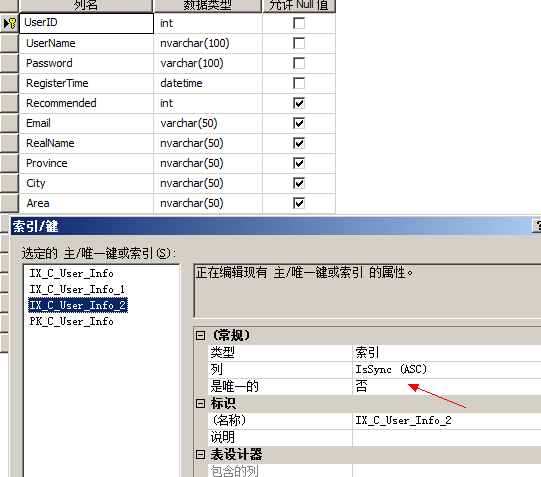
如果数据表太大,我们需要在命令行中去运行
 apa itu pengoptimuman
apa itu pengoptimuman
 mencari linux
mencari linux
 Perisian pengoptimuman kata kunci Baidu
Perisian pengoptimuman kata kunci Baidu
 Perbezaan antara counta dan count
Perbezaan antara counta dan count
 Kaedah pengoptimuman kedudukan kata kunci SEO Baidu
Kaedah pengoptimuman kedudukan kata kunci SEO Baidu
 Apakah arahan untuk memadam lajur dalam sql
Apakah arahan untuk memadam lajur dalam sql
 Pulihkan data daripada pemacu keras mudah alih
Pulihkan data daripada pemacu keras mudah alih
 Pengenalan kepada tag standard dalam php
Pengenalan kepada tag standard dalam php
 Cara membaiki lsp
Cara membaiki lsp








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



