

Python实现将xml导入至excel

最近在使用Testlink时,发现导入的用例是xml格式,且没有合适的工具转成excel格式,xml使用excel打开显示的东西也太多,网上也有相关工具转成csv格式的,结果也不合人意。
那求人不如尔己,自己写一个吧
需要用到的模块有:xml.dom.minidom(python自带)、xlwt
使用版本:
python:2.7.5
xlwt:1.0.0
一、先分析Testlink XML格式:
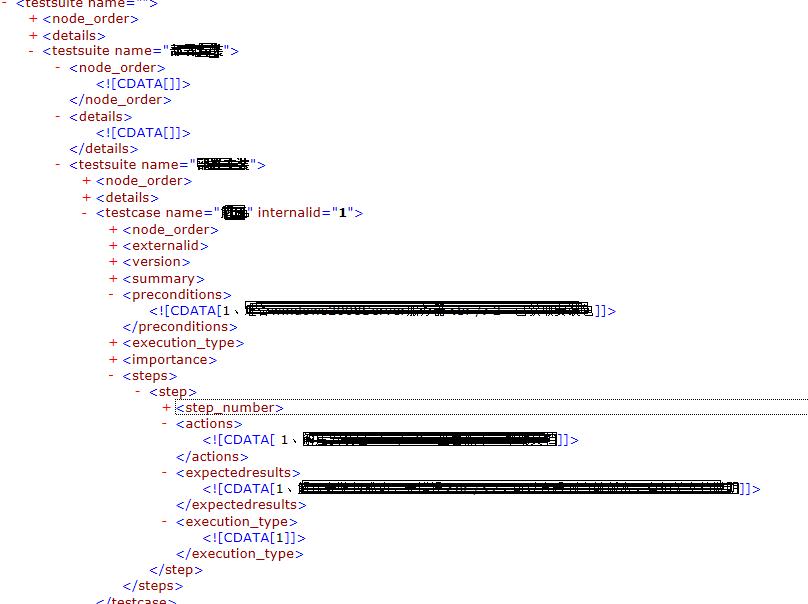
这是一个有两级testusuit的典型的testlink用例结构,我们只需要取testsuite name,testcase name,preconditions,actions,expectedresults
二、程序如下:
#coding:utf-8
'''
Created on 2015-8-20
@author: Administrator
'''
'''
'''
import xml.etree.cElementTree as ET
import xml.dom.minidom as xx
import os,xlwt,datetime
workbook=xlwt.Workbook(encoding="utf-8")
#
booksheet=workbook.add_sheet(u'sheet_1')
booksheet.col(0).width= 5120
booksheet.col(1).width= 5120
booksheet.col(2).width= 5120
booksheet.col(3).width= 5120
booksheet.col(4).width= 5120
booksheet.col(5).width= 5120
dom=xx.parse(r'D:\\Python27\test.xml')
root = dom.documentElement
row=1
col=1
borders=xlwt.Borders()
borders.left=1
borders.right=1
borders.top=1
borders.bottom=1
style = xlwt.easyxf('align: wrap on,vert centre, horiz center') #自动换行、水平居中、垂直居中
#设置标题的格式,字体方宋、加粗、背景色:菊黄
#测试项的标题
title=xlwt.easyxf(u'font:name 仿宋,height 240 ,colour_index black, bold on, italic off; align: wrap on, vert centre, horiz center;pattern: pattern solid, fore_colour light_orange;')
item='测试项'
Subitem='测试分项'
CaseTitle='测试用例标题'
Condition='预置条件'
actions='操作步骤'
Result='预期结果'
booksheet.write(0,0,item,title)
booksheet.write(0,1,Subitem,title)
booksheet.write(0,2,CaseTitle,title)
booksheet.write(0,3,Condition,title)
booksheet.write(0,4,actions,title)
booksheet.write(0,5,Result,title)
#冻结首行
booksheet.panes_frozen=True
booksheet.horz_split_pos= 1
#一级目录
for i in root.childNodes:
testsuite=i.getAttribute('name').strip()
#print testsuite
#print testsuite
'''
写测试项
'''
print "row is :",row
booksheet.write(row,col,testsuite,style)
#二级目录
for dd in i.childNodes:
print " %s" % dd.getAttribute('name')
testsuite2=dd.getAttribute('name')
if not dd.getElementsByTagName('testcase'):
print "Testcase is %s" % testsuite2
row=row+1
booksheet.write(row,2,testsuite2,style) #写测试分项
row=row+1
booksheet.write(row,1,testsuite2,style)
itemlist=dd.getElementsByTagName('testcase')
for subb in itemlist:
#print " %s" % subb.getAttribute('name')
testcase=subb.getAttribute('name')
row=row+1
booksheet.write(row,2,testcase,style)
ilist=subb.getElementsByTagName('preconditions')
for ii in ilist:
preconditions=ii.firstChild.data.replace("<br />"," ")
col=col+1
booksheet.write(row,3,preconditions,style)
steplist=subb.getElementsByTagName('actions')
#print steplist
for step in steplist:
actions=step.firstChild.data.replace("<br />"," ")
col=col+1
booksheet.write(row,4,actions,style)
#print "测试步骤:",steplist[0].firstChild.data.replace("<br />"," ")
expectlist=subb.getElementsByTagName('expectedresults')
for expect in expectlist:
result=expect.childNodes[0].nodeValue.replace("<br />","" )
booksheet.write(row,5,result,style)
row=row+1
workbook.save('demo.xls')写入excel的效果如下:

我们再来看个实例:
需要下载一个module:xlwt,如下是source code
import xml.dom.minidom
import xlwt
import sys
col = 0
row = 0
def handle_xml_report(xml_report, excel):
problems = xml_report.getElementsByTagName("problem")
handle_problems(problems, excel)
def handle_problems(problems, excel):
for problem in problems:
handle_problem(problem, excel)
def handle_problem(problem, excel):
global row
global col
code = problem.getElementsByTagName("code")
file = problem.getElementsByTagName("file")
line = problem.getElementsByTagName("line")
message = problem.getElementsByTagName("message")
for node in code:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in file:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in line:
excel.write(row, col, node.firstChild.data)
col = col + 1
for node in message:
excel.write(row, col, node.firstChild.data)
col = col + 1
row = row+1
col = 0
if __name__ == '__main__':
if(len(sys.argv) <= 1):
print ("usage: xml2xls src_file [dst_file]")
exit(0)
#the 1st argument is XML report ; the 2nd is XLS report
if(len(sys.argv) == 2):
xls_report = sys.argv[1][:-3] + 'xls'
#if there are more than 2 arguments, only the 1st & 2nd make sense
else:
xls_report = sys.argv[2]
xmldoc = xml.dom.minidom.parse(sys.argv[1])
wb = xlwt.Workbook()
ws = wb.add_sheet('MOLint')
ws.write(row, col, 'Error Code')
col = col + 1
ws.write(row, col, 'file')
col = col + 1
ws.write(row, col, 'line')
col = col + 1
ws.write(row, col, 'Description')
row = row + 1
col = 0
handle_xml_report(xmldoc, ws)
wb.save(xls_report)

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Adakah kelajuan penukaran cepat apabila menukar XML ke PDF pada telefon bimbit?
Apr 02, 2025 pm 10:09 PM
Kelajuan XML mudah alih ke PDF bergantung kepada faktor -faktor berikut: kerumitan struktur XML. Kaedah Penukaran Konfigurasi Perkakasan Mudah Alih (Perpustakaan, Algoritma) Kaedah Pengoptimuman Kualiti Kod (Pilih perpustakaan yang cekap, mengoptimumkan algoritma, data cache, dan menggunakan pelbagai threading). Secara keseluruhannya, tidak ada jawapan mutlak dan ia perlu dioptimumkan mengikut keadaan tertentu.
 Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Bagaimana cara menukar fail XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:12 PM
Tidak mustahil untuk menyelesaikan penukaran XML ke PDF secara langsung di telefon anda dengan satu aplikasi. Ia perlu menggunakan perkhidmatan awan, yang boleh dicapai melalui dua langkah: 1. Tukar XML ke PDF di awan, 2. Akses atau muat turun fail PDF yang ditukar pada telefon bimbit.
 Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Apakah fungsi jumlah bahasa C?
Apr 03, 2025 pm 02:21 PM
Tiada fungsi jumlah terbina dalam dalam bahasa C, jadi ia perlu ditulis sendiri. Jumlah boleh dicapai dengan melintasi unsur -unsur array dan terkumpul: Versi gelung: SUM dikira menggunakan panjang gelung dan panjang. Versi Pointer: Gunakan petunjuk untuk menunjuk kepada unsur-unsur array, dan penjumlahan yang cekap dicapai melalui penunjuk diri sendiri. Secara dinamik memperuntukkan versi Array: Perlawanan secara dinamik dan uruskan memori sendiri, memastikan memori yang diperuntukkan dibebaskan untuk mengelakkan kebocoran ingatan.
 Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 09:45 PM
Adakah terdapat aplikasi mudah alih yang boleh menukar XML ke PDF?
Apr 02, 2025 pm 09:45 PM
Tiada aplikasi yang boleh menukar semua fail XML ke dalam PDF kerana struktur XML adalah fleksibel dan pelbagai. Inti XML ke PDF adalah untuk menukar struktur data ke dalam susun atur halaman, yang memerlukan parsing XML dan menjana PDF. Kaedah umum termasuk parsing XML menggunakan perpustakaan python seperti ElementTree dan menjana PDF menggunakan perpustakaan ReportLab. Untuk XML yang kompleks, mungkin perlu menggunakan struktur transformasi XSLT. Apabila mengoptimumkan prestasi, pertimbangkan untuk menggunakan multithreaded atau multiprocesses dan pilih perpustakaan yang sesuai.
 Bagaimana cara menukar XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:18 PM
Bagaimana cara menukar XML ke PDF di telefon anda?
Apr 02, 2025 pm 10:18 PM
Ia tidak mudah untuk menukar XML ke PDF secara langsung pada telefon anda, tetapi ia boleh dicapai dengan bantuan perkhidmatan awan. Adalah disyorkan untuk menggunakan aplikasi mudah alih ringan untuk memuat naik fail XML dan menerima PDF yang dihasilkan, dan menukarnya dengan API awan. API awan menggunakan perkhidmatan pengkomputeran tanpa pelayan, dan memilih platform yang betul adalah penting. Kerumitan, pengendalian kesilapan, keselamatan, dan strategi pengoptimuman perlu dipertimbangkan ketika mengendalikan penjanaan XML dan penjanaan PDF. Seluruh proses memerlukan aplikasi front-end dan API back-end untuk bekerjasama, dan ia memerlukan pemahaman tentang pelbagai teknologi.
 Cara menukar XML ke dalam gambar
Apr 03, 2025 am 07:39 AM
Cara menukar XML ke dalam gambar
Apr 03, 2025 am 07:39 AM
XML boleh ditukar kepada imej dengan menggunakan perpustakaan penukar XSLT atau imej. XSLT Converter: Gunakan pemproses XSLT dan stylesheet untuk menukar XML ke imej. Perpustakaan Imej: Gunakan perpustakaan seperti PIL atau ImageMagick untuk membuat imej dari data XML, seperti bentuk lukisan dan teks.
 Bagaimana cara menukar XML ke PDF di telefon anda dengan kualiti tinggi?
Apr 02, 2025 pm 09:48 PM
Bagaimana cara menukar XML ke PDF di telefon anda dengan kualiti tinggi?
Apr 02, 2025 pm 09:48 PM
Tukar XML ke PDF dengan kualiti tinggi pada telefon bimbit anda memerlukan: Parsing XML di awan dan menjana PDF menggunakan platform pengkomputeran tanpa pelayan. Pilih Parser XML yang cekap dan perpustakaan penjanaan PDF. Mengendalikan kesilapan dengan betul. Menggunakan sepenuhnya kuasa pengkomputeran awan untuk mengelakkan tugas berat pada telefon anda. Laraskan kerumitan mengikut keperluan, termasuk memproses struktur XML kompleks, menghasilkan PDF multi-halaman, dan menambah imej. Cetak maklumat log untuk membantu debug. Mengoptimumkan prestasi, pilih parser yang cekap dan perpustakaan PDF, dan boleh menggunakan pengaturcaraan asynchronous atau data XML preprocessing. Memastikan kualiti kod yang baik dan penyelenggaraan.
 Bagaimana cara menukar XML ke PDF pada telefon Android?
Apr 02, 2025 pm 09:51 PM
Bagaimana cara menukar XML ke PDF pada telefon Android?
Apr 02, 2025 pm 09:51 PM
Menukar XML ke PDF secara langsung pada telefon Android tidak dapat dicapai melalui ciri-ciri terbina dalam. Anda perlu menyelamatkan negara melalui langkah -langkah berikut: Tukar data XML ke format yang diiktiraf oleh penjana PDF (seperti teks atau HTML); Tukar HTML ke PDF menggunakan perpustakaan generasi HTML seperti Flying Saucer.
