

用Python解析XML的几种常见方法的介绍

一、简介
XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用。它是web发展到一定阶段的必然产物,既具有SGML的核心特征,又有着HTML的简单特性,还具有明确和结构良好等许多新的特性。
python解析XML常见的有三种方法:一是xml.dom.*模块,它是W3C DOM API的实现,若需要处理DOM API则该模块很适合,注意xml.dom包里面有许多模块,须区分它们间的不同;二是xml.sax.*模块,它是SAX API的实现,这个模块牺牲了便捷性来换取速度和内存占用,SAX是一个基于事件的API,这就意味着它可以“在空中”处理庞大数量的的文档,不用完全加载进内存;三是xml.etree.ElementTree模块(简称 ET),它提供了轻量级的Python式的API,相对于DOM来说ET 快了很多,而且有很多令人愉悦的API可以使用,相对于SAX来说ET的ET.iterparse也提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,ET的性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便。
二、详解
解析的xml文件(country.xml):
在CODE上查看代码片派生到我的代码片
<?xml version="1.0"?>
<data>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
1、xml.etree.ElementTree
ElementTree生来就是为了处理XML,它在Python标准库中有两种实现:一种是纯Python实现的,如xml.etree.ElementTree,另一种是速度快一点的xml.etree.cElementTree。注意:尽量使用C语言实现的那种,因为它速度更快,而且消耗的内存更少。
在CODE上查看代码片派生到我的代码片
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
这是一个让Python不同的库使用相同API的一个比较常用的办法,而从Python 3.3开始ElementTree模块会自动寻找可用的C库来加快速度,所以只需要import xml.etree.ElementTree就可以了。
在CODE上查看代码片派生到我的代码片
#!/usr/bin/evn python
#coding:utf-8
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
import sys
try:
tree = ET.parse("country.xml") #打开xml文档
#root = ET.fromstring(country_string) #从字符串传递xml
root = tree.getroot() #获得root节点
except Exception, e:
print "Error:cannot parse file:country.xml."
sys.exit(1)
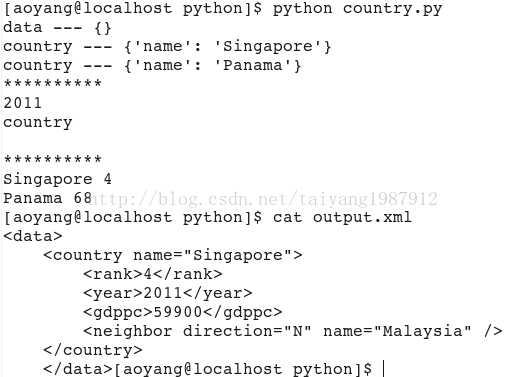
print root.tag, "---", root.attrib
for child in root:
print child.tag, "---", child.attrib
print "*"*10
print root[0][1].text #通过下标访问
print root[0].tag, root[0].text
print "*"*10
for country in root.findall('country'): #找到root节点下的所有country节点
rank = country.find('rank').text #子节点下节点rank的值
name = country.get('name') #子节点下属性name的值
print name, rank
#修改xml文件
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
运行结果:
参考:https://docs.python.org/2/library/xml.etree.elementtree.html
2、xml.dom.*
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。一个 DOM 的解析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。python中用xml.dom.minidom来解析xml文件,例子如下:
在CODE上查看代码片派生到我的代码片
#!/usr/bin/python
#coding=utf-8
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开XML文档
DOMTree = xml.dom.minidom.parse("country.xml")
Data = DOMTree.documentElement
if Data.hasAttribute("name"):
print "name element : %s" % Data.getAttribute("name")
# 在集合中获取所有国家
Countrys = Data.getElementsByTagName("country")
# 打印每个国家的详细信息
for Country in Countrys:
print "*****Country*****"
if Country.hasAttribute("name"):
print "name: %s" % Country.getAttribute("name")
rank = Country.getElementsByTagName('rank')[0]
print "rank: %s" % rank.childNodes[0].data
year = Country.getElementsByTagName('year')[0]
print "year: %s" % year.childNodes[0].data
gdppc = Country.getElementsByTagName('gdppc')[0]
print "gdppc: %s" % gdppc.childNodes[0].data
for neighbor in Country.getElementsByTagName("neighbor"):
print neighbor.tagName, ":", neighbor.getAttribute("name"), neighbor.getAttribute("direction")
运行结果:

参考:https://docs.python.org/2/library/xml.dom.html
3、xml.sax.*
SAX是一种基于事件驱动的API,利用SAX解析XML牵涉到两个部分:解析器和事件处理器。其中解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件;而事件处理器则负责对事件作出相应,对传递的XML数据进行处理。python中使用sax方式处理xml要先引入xml.sax中的parse函数,还有xml.sax.handler中的ContentHandler。常使用在如下的情况下:一、对大型文件进行处理;二、只需要文件的部分内容,或者只需从文件中得到特定信息;三、想建立自己的对象模型的时候。
ContentHandler类方法介绍
(1)characters(content)方法
调用时机:
从行开始,遇到标签之前,存在字符,content的值为这些字符串。
从一个标签,遇到下一个标签之前, 存在字符,content的值为这些字符串。
从一个标签,遇到行结束符之前,存在字符,content的值为这些字符串。
标签可以是开始标签,也可以是结束标签。
(2)startDocument()方法
文档启动的时候调用。
(3)endDocument()方法
解析器到达文档结尾时调用。
(4)startElement(name, attrs)方法
遇到XML开始标签时调用,name是标签的名字,attrs是标签的属性值字典。
(5)endElement(name)方法
遇到XML结束标签时调用。
在CODE上查看代码片派生到我的代码片
#coding=utf-8
#!/usr/bin/python
import xml.sax
class CountryHandler(xml.sax.ContentHandler):
def __init__(self):
self.CurrentData = ""
self.rank = ""
self.year = ""
self.gdppc = ""
self.neighborname = ""
self.neighbordirection = ""
# 元素开始事件处理
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "country":
print "*****Country*****"
name = attributes["name"]
print "name:", name
elif tag == "neighbor":
name = attributes["name"]
direction = attributes["direction"]
print name, "->", direction
# 元素结束事件处理
def endElement(self, tag):
if self.CurrentData == "rank":
print "rank:", self.rank
elif self.CurrentData == "year":
print "year:", self.year
elif self.CurrentData == "gdppc":
print "gdppc:", self.gdppc
self.CurrentData = ""
# 内容事件处理
def characters(self, content):
if self.CurrentData == "rank":
self.rank = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "gdppc":
self.gdppc = content
if __name__ == "__main__":
# 创建一个 XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = CountryHandler()
parser.setContentHandler(Handler)
parser.parse("country.xml")
运行结果:

4、libxml2和lxml解析xml
libxml2是使用C语言开发的xml解析器,是一个基于MIT License的免费开源软件,多种编程语言都有基于它的实现,python中的libxml2模块有点小不足的是:xpathEval()接口不支持类似模板的用法,但不影响使用,因libxml2采用C语言开发的,因此在使用API接口的方式上难免会有点不适应。
在CODE上查看代码片派生到我的代码片
#!/usr/bin/python
#coding=utf-8
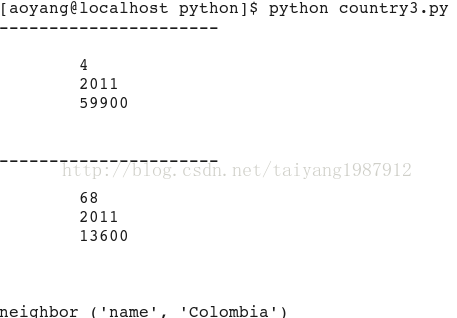
import libxml2
doc = libxml2.parseFile("country.xml")
for book in doc.xpathEval('//country'):
if book.content != "":
print "----------------------"
print book.content
for node in doc.xpathEval("//country/neighbor[@name = 'Colombia']"):
print node.name, (node.properties.name, node.properties.content)
doc.freeDoc()
lxml是以libxml2为基础采用python语言开发的,从使用层面上说比lxml更适合python开发者,且xpath()接口支持类似模板的用法。
在CODE上查看代码片派生到我的代码片
#!/usr/bin/python
#coding=utf-8
import lxml.etree
doc = lxml.etree.parse("country.xml")
for node in doc.xpath("//country/neighbor[@name = $name]", name = "Colombia"):
print node.tag, node.items()
for node in doc.xpath("//country[@name = $name]", name = "Singapore"):
print node.tag, node.items()

三、总结
(1)Python中XML解析可用的类库或模块有xml、libxml2 、lxml 、xpath等,需要深入了解的还需参考相应的文档。
(2)每一种解析方式都有自己的优点和缺点,选择前可以综合各个方面的性能考虑。
(3)若有不足,请留言,在此先感谢!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popular
Apr 14, 2025 am 12:13 AM
PHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar anda
Apr 14, 2025 am 12:02 AM
Untuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Cara mengkonfigurasi pelayan https di debian openssl
Apr 13, 2025 am 11:03 AM
Mengkonfigurasi pelayan HTTPS pada sistem Debian melibatkan beberapa langkah, termasuk memasang perisian yang diperlukan, menghasilkan sijil SSL, dan mengkonfigurasi pelayan web (seperti Apache atau Nginx) untuk menggunakan sijil SSL. Berikut adalah panduan asas, dengan mengandaikan anda menggunakan pelayan Apacheweb. 1. Pasang perisian yang diperlukan terlebih dahulu, pastikan sistem anda terkini dan pasang Apache dan OpenSSL: sudoaptDateSudoaptgradesudoaptinsta
 Panduan Pembangunan Plug-In Gitlab di Debian
Apr 13, 2025 am 08:24 AM
Panduan Pembangunan Plug-In Gitlab di Debian
Apr 13, 2025 am 08:24 AM
Membangunkan plugin Gitlab pada Debian memerlukan beberapa langkah dan pengetahuan tertentu. Berikut adalah panduan asas untuk membantu anda memulakan proses ini. Memasang GitLab terlebih dahulu, anda perlu memasang GitLab pada sistem Debian anda. Anda boleh merujuk kepada manual pemasangan rasmi GitLab. Dapatkan token akses API sebelum melakukan integrasi API, anda perlu mendapatkan token akses API Gitlab terlebih dahulu. Buka papan pemuka Gitlab, cari pilihan "AccessTokens" dalam tetapan pengguna, dan menghasilkan token akses baru. Akan dijana
 Perkhidmatan apa yang Apache
Apr 13, 2025 pm 12:06 PM
Perkhidmatan apa yang Apache
Apr 13, 2025 pm 12:06 PM
Apache adalah wira di belakang internet. Ia bukan sahaja pelayan web, tetapi juga platform yang kuat yang menyokong lalu lintas yang besar dan menyediakan kandungan dinamik. Ia memberikan fleksibiliti yang sangat tinggi melalui reka bentuk modular, yang membolehkan pengembangan pelbagai fungsi seperti yang diperlukan. Walau bagaimanapun, modulariti juga membentangkan cabaran konfigurasi dan prestasi yang memerlukan pengurusan yang teliti. Apache sesuai untuk senario pelayan yang memerlukan keperluan yang sangat disesuaikan dan memenuhi keperluan kompleks.
 Bahasa apa yang ditulis Apache?
Apr 13, 2025 pm 12:42 PM
Bahasa apa yang ditulis Apache?
Apr 13, 2025 pm 12:42 PM
Apache ditulis dalam C. Bahasa ini menyediakan kelajuan, kestabilan, mudah alih, dan akses perkakasan langsung, menjadikannya sesuai untuk pembangunan pelayan web.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
