

Python中多线程使用到Threading模块。Threading模块中用到的主要的类是Thread,我们先来写一个简单的多线程代码:
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
global n
print n
n += 1
if "__main__" == __name__:
n = 0
ThreadList = []
for i in range(0, 10):
t = MyThread()
ThreadList.append(t)
for t in ThreadList:
t.start()
for t in ThreadList:
t.join
最普通的一个多线程小例子。我一笔带过地讲一讲,我创建了一个继承Thread类的子类MyThread,作为我们的线程启动类。按照规定,重写Thread的run方法,我们的线程启动起来后会自动调用该方法。于是我首先创建了10个线程,并将其加入列表中。再使用一个for循环,开启每个线程。在使用一个for循环,调用join方法等待所有线程结束才退出主线程。
这段代码看似简单,但实际上隐藏着一个很大的问题,只是在这里没有体现出来。你真的以为我创建了10个线程,并按顺序调用了这10个线程,每个线程为n增加了1.实际上,有可能是A线程执行了n++,再C线程执行了n++,再B线程执行n++。
这里涉及到一个“锁”的问题,如果有多个线程同时操作一个对象,如果没有很好地保护该对象,会造成程序结果的不可预期(比如我们在每个线程的run方法中加入一个time.sleep(1),并同时输出线程名称,则我们会发现,输出会乱七八糟。因为可能我们的一个print语句只打印出一半的字符,这个线程就被暂停,执行另一个去了,所以我们看到的结果很乱),这种现象叫做“线程不安全”:
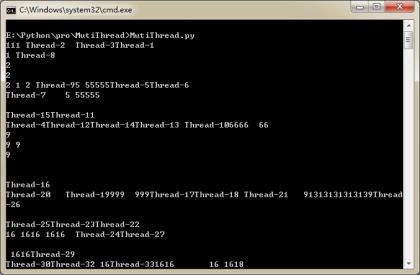
于是,Threading模块为我们提供了一个类,Threading.Lock,锁。我们创建一个该类对象,在线程函数执行前,“抢占”该锁,执行完成后,“释放”该锁,则我们确保了每次只有一个线程占有该锁。这时候对一个公共的对象进行操作,则不会发生线程不安全的现象了。
于是,我们把代码更改如下:
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
global n, lock
time.sleep(1)
if lock.acquire():
print n , self.name
n += 1
lock.release()
if "__main__" == __name__:
n = 1
ThreadList = []
lock = threading.Lock()
for i in range(1, 200):
t = MyThread()
ThreadList.append(t)
for t in ThreadList:
t.start()
for t in ThreadList:
t.join()
最后执行结果:
我们看到,我们先建立了一个threading.Lock类对象lock,在run方法里,我们使用lock.acquire()获得了这个锁。此时,其他的线程就无法再获得该锁了,他们就会阻塞在“if lock.acquire()”这里,直到锁被另一个线程释放:lock.release()。
所以,if语句中的内容就是一块完整的代码,不会再存在执行了一半就暂停去执行别的线程的情况。所以最后结果是整齐的。
就如同在java中,我们使用synchronized关键字修饰一个方法,目的一样,让某段代码被一个线程执行时,不会打断跳到另一个线程中。
这是多线程占用一个公共对象时候的情况。如果多个线程要调用多个现象,而A线程调用A锁占用了A对象,B线程调用了B锁占用了B对象,A线程不能调用B对象,B线程不能调用A对象,于是一直等待。这就造成了线程“死锁”。
Threading模块中,也有一个类,RLock,称之为可重入锁。该锁对象内部维护着一个Lock和一个counter对象。counter对象记录了acquire的次数,使得资源可以被多次require。最后,当所有RLock被release后,其他线程才能获取资源。在同一个线程中,RLock.acquire可以被多次调用,利用该特性,可以解决部分死锁问题。
死锁问题很复杂,多年来人们想出了很多算法来解决它。我就不再多说,具体还是要大家参阅帮助文档。
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



