

Hello, saya Luga, hari ini kita akan bercakap tentang teknologi yang berkaitan dengan bidang ekologi kecerdasan buatan (AI) - penilaian LLM.
Seperti yang kita sedia maklum, penilaian LLM adalah topik penting dalam bidang kecerdasan buatan. Memandangkan LLM semakin digunakan secara meluas dalam pelbagai senario, menjadi semakin penting untuk menilai keupayaan dan batasannya. Sebagai alat penilaian LLM yang baru muncul, ArthurBench menyasarkan untuk menyediakan platform penilaian yang komprehensif, adil dan boleh dihasilkan semula untuk penyelidik dan pembangun AI.

Dalam beberapa tahun kebelakangan ini, dengan perkembangan pesat dan peningkatan model bahasa besar (LLM), kaedah penilaian teks tradisional mungkin tidak lagi digunakan dalam beberapa aspek. Dalam bidang penilaian teks, kita mungkin pernah mendengar tentang beberapa kaedah, seperti kaedah penilaian berasaskan "kejadian perkataan", seperti BLEU, dan kaedah penilaian berasaskan "model pemprosesan bahasa semula jadi pra-terlatih", seperti BERTScore. Kaedah penilaian baharu ini membolehkan penilaian yang lebih tepat tentang kualiti dan kaitan teks. Sebagai contoh, kaedah penilaian BLEU menilai kualiti terjemahan berdasarkan tahap kemunculan perkataan standard, manakala kaedah penilaian BERTScore menilai kerelevanan teks berdasarkan keupayaan model pemprosesan bahasa semula jadi yang telah terlatih untuk mensimulasikan pemprosesan ayat bahasa semula jadi. Kaedah penilaian baharu ini menyelesaikan beberapa masalah kaedah tradisional pada tahap tertentu dan mempunyai fleksibiliti dan ketepatan yang lebih tinggi. Walau bagaimanapun, dengan pembangunan berterusan dan penambahbaikan model bahasa, kaedah ini sangat baik pada masa lalu, tetapi apabila teknologi ekologi LLM terus berkembang, ia ditunjukkan agak tidak mencukupi dan tidak dapat memenuhi keperluan semasa sepenuhnya.
Dengan perkembangan pesat dan peningkatan LLM, kami menghadapi cabaran dan peluang baharu. Keupayaan dan tahap prestasi LLM terus meningkat, menjadikan kaedah penilaian berasaskan kejadian perkataan seperti BLEU mungkin tidak menangkap sepenuhnya kualiti dan ketepatan semantik teks yang dijana LLM. LLM menghasilkan teks yang lebih lancar, koheren dan kaya dengan semantik, faedah yang gagal untuk diukur dengan tepat oleh kaedah penilaian berasaskan kejadian perkataan tradisional.
Kaedah penilaian untuk model pra-latihan (seperti BERTScore) mungkin menghadapi beberapa cabaran apabila menangani tugasan tertentu. Walaupun model pra-latihan berfungsi dengan baik pada banyak tugas, mereka mungkin tidak mengambil kira sepenuhnya ciri unik LLM dan prestasinya pada tugas tertentu. Oleh itu, bergantung semata-mata pada kaedah penilaian berdasarkan model pra-latihan mungkin tidak menilai sepenuhnya keupayaan LLM. Mengapa penilaian bimbingan LLM diperlukan?
1. Cekap
2. Sensitiviti
Seperti yang kita bincangkan sebelum ini, penilai LLM lebih sensitif berbanding kaedah penilaian lain. Terdapat banyak cara berbeza untuk mengkonfigurasi LLM sebagai penilai, dan tingkah lakunya boleh berbeza-beza bergantung pada konfigurasi yang dipilih. Sementara itu, cabaran lain ialah penilai LLM boleh tersekat jika penilaian melibatkan terlalu banyak langkah inferens atau memerlukan pemprosesan terlalu banyak pembolehubah secara serentak.
Selain itu, penilai mungkin menghadapi beberapa cabaran apabila berhadapan dengan tugas penilaian yang memerlukan penaakulan kompleks atau pemprosesan berbilang pembolehubah secara serentak. Ini kerana keupayaan penaakulan LLM mungkin terhad apabila berhadapan dengan situasi yang kompleks. LLM mungkin memerlukan usaha tambahan untuk menangani tugas-tugas ini untuk memastikan ketepatan dan kebolehpercayaan penilaian.
Arthur Bench ialah alat penilaian sumber terbuka yang digunakan untuk membandingkan prestasi model teks generatif (LLM). Ia boleh digunakan untuk menilai model, isyarat dan hiperparameter LLM yang berbeza dan menyediakan laporan terperinci tentang prestasi LLM pada pelbagai tugas.
Ciri utama Arthur Bench termasuk:
Secara amnya, aliran kerja Arthur Bench terutamanya melibatkan peringkat berikut, dan analisis terperinci adalah seperti berikut:
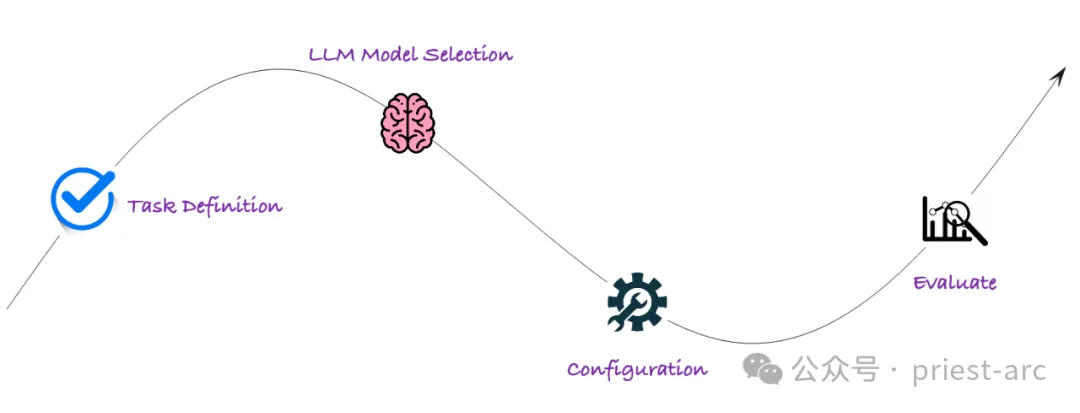
Pada peringkat ini, kami perlu menjelaskan matlamat penilaian Arthur Bench pelbagai Pelbagai tugas penilaian, termasuk:
Pada peringkat ini, kerja utama ialah memilih objek penilaian. Arthur Bench menyokong pelbagai model LLM, meliputi teknologi terkemuka daripada institusi terkenal seperti OpenAI, Google AI, Microsoft, dsb., seperti GPT-3, LaMDA, Megatron-Turing NLG, dsb. Kita boleh memilih model tertentu untuk penilaian berdasarkan keperluan penyelidikan.
Selepas melengkapkan pemilihan model, langkah seterusnya ialah menjalankan kawalan yang diperhalusi. Untuk menilai prestasi LLM dengan lebih tepat, Arthur Bench membenarkan pengguna mengkonfigurasi pembayang dan hiperparameter.
Melalui konfigurasi yang diperhalusi, kami boleh meneroka secara mendalam perbezaan prestasi LLM di bawah tetapan parameter yang berbeza dan mendapatkan hasil penilaian dengan lebih banyak nilai rujukan.
Langkah terakhir ialah menjalankan penilaian tugas dengan bantuan proses automatik. Biasanya, Arthur Bench menyediakan proses penilaian automatik yang memerlukan konfigurasi mudah untuk menjalankan tugas penilaian. Ia akan melakukan langkah berikut secara automatik:
Sebagai kunci kepada penilaian LLM yang dipacu data, Arthur Bench terutamanya menyediakan penyelesaian berikut, khususnya yang melibatkan:
merupakan langkah penting dalam bidang kecerdasan buatan dan sangat penting untuk memastikan kesahihan dan kebolehpercayaan model. Dalam proses ini, peranan Arthur Bench adalah penting. Matlamatnya adalah untuk menyediakan syarikat rangka kerja perbandingan yang boleh dipercayai untuk membantu mereka membuat keputusan termaklum di antara banyak pilihan model bahasa besar (LLM) melalui penggunaan metrik dan kaedah penilaian yang konsisten.
Arthur Bench akan menggunakan kepakaran dan pengalamannya untuk menilai setiap pilihan LLM dan memastikan metrik yang konsisten digunakan untuk membandingkan kekuatan dan kelemahan mereka. Beliau akan mempertimbangkan faktor seperti prestasi model, ketepatan, kelajuan, keperluan sumber dan banyak lagi untuk memastikan syarikat boleh membuat pilihan yang termaklum dan jelas.
Dengan menggunakan metrik dan metodologi penilaian yang konsisten, Arthur Bench akan menyediakan syarikat rangka kerja perbandingan yang boleh dipercayai, membolehkan mereka menilai sepenuhnya faedah dan had setiap pilihan LLM. Ini akan membolehkan syarikat membuat keputusan termaklum untuk memaksimumkan kemajuan pesat dalam kecerdasan buatan dan memastikan pengalaman terbaik dengan aplikasi mereka.
Apabila memilih model AI, tidak semua aplikasi memerlukan model bahasa besar (LLM) yang paling canggih atau mahal. Dalam sesetengah kes, keperluan misi boleh dipenuhi menggunakan model AI yang lebih murah.
Pendekatan pengoptimuman belanjawan ini boleh membantu syarikat membuat pilihan bijak dengan sumber yang terhad. Daripada memilih model yang paling mahal atau terkini, pilih model yang betul berdasarkan keperluan khusus anda. Model yang lebih mampu milik mungkin berprestasi lebih buruk sedikit daripada LLM tercanggih dalam beberapa aspek, tetapi untuk beberapa tugas mudah atau standard, Arthur Bench masih boleh menyediakan penyelesaian yang memenuhi keperluan.
Selain itu, Arthur Bench menekankan bahawa membawa model secara dalaman membolehkan kawalan yang lebih baik ke atas privasi data. Untuk aplikasi yang melibatkan data sensitif atau isu privasi, syarikat mungkin lebih suka menggunakan model terlatih dalaman mereka sendiri daripada bergantung pada LLM pihak ketiga luaran. Dengan menggunakan model dalaman, syarikat boleh memperoleh kawalan yang lebih besar ke atas pemprosesan dan penyimpanan data serta melindungi privasi data dengan lebih baik.
Tanda aras akademik merujuk kepada metrik dan kaedah penilaian model yang ditetapkan dalam penyelidikan akademik. Penunjuk dan kaedah ini biasanya khusus untuk tugas atau domain tertentu dan boleh menilai prestasi model dalam tugas atau domain itu dengan berkesan.
Walau bagaimanapun, penanda aras akademik tidak selalu mencerminkan prestasi model secara langsung dalam dunia sebenar. Ini kerana senario aplikasi dalam dunia nyata selalunya lebih kompleks dan memerlukan lebih banyak faktor untuk dipertimbangkan, seperti pengedaran data, persekitaran penggunaan model, dsb.
Arthur Bench membantu menterjemahkan tanda aras akademik kepada prestasi dunia sebenar. Ia mencapai matlamat ini dengan cara berikut:
Sebagai kunci kepada penilaian LLM yang dipacu data yang pantas, Arthur Bench mempunyai ciri berikut:
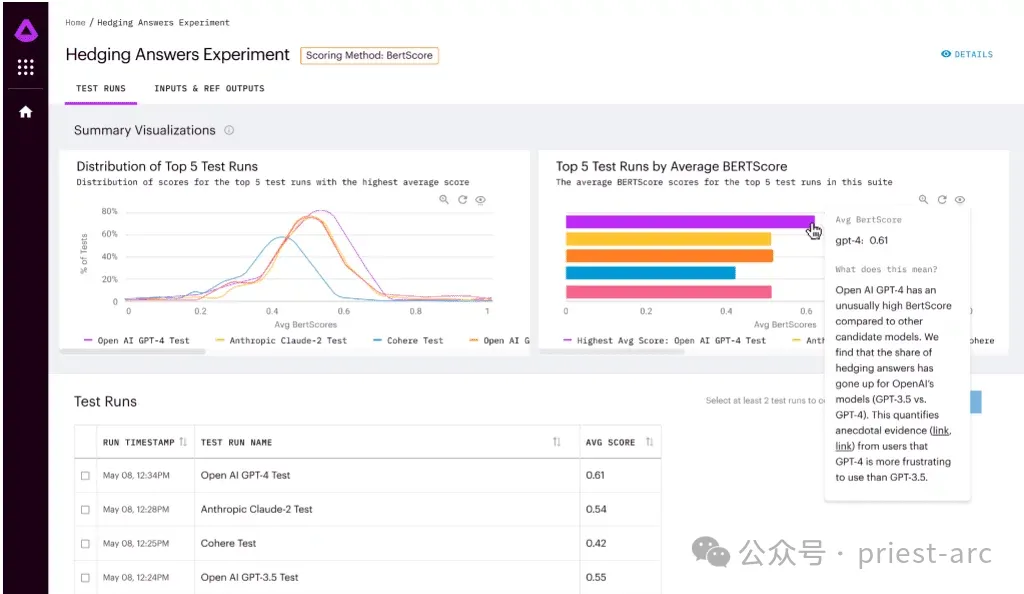
Arthur Bench mempunyai set pemarkahan yang lengkap penunjuk, meliputi segala-galanya daripada Ringkaskan semua aspek kualiti kepada pengalaman pengguna. Dia boleh menggunakan metrik pemarkahan ini pada bila-bila masa untuk menilai dan membandingkan model yang berbeza. Penggunaan gabungan metrik pemarkahan ini boleh membantunya memahami sepenuhnya kekuatan dan kelemahan setiap model.
Skop penunjuk pemarkahan ini sangat luas, termasuk tetapi tidak terhad kepada kualiti ringkasan, ketepatan, kelancaran, ketepatan tatabahasa, kebolehan memahami konteks, koheren logik, dsb. Arthur Bench akan menilai setiap model berdasarkan metrik ini dan menggabungkan hasilnya ke dalam skor komprehensif untuk membantu syarikat membuat keputusan termaklum.
Selain itu, jika syarikat mempunyai keperluan atau kebimbangan khusus, Arthur Bench juga boleh membuat dan menambah metrik pemarkahan tersuai berdasarkan keperluan syarikat. Ini dilakukan untuk memenuhi keperluan khusus syarikat dengan lebih baik dan memastikan proses penilaian adalah konsisten dengan matlamat dan piawaian syarikat.
Bagi mereka yang lebih suka penempatan tempatan dan kawalan autonomi, anda boleh mendapatkan akses daripada repositori GitHub dan menggunakan Arthur Bench ke persekitaran setempat anda sendiri. Dengan cara ini, semua orang boleh menguasai dan mengawal sepenuhnya operasi Arthur Bench dan menyesuaikan serta mengkonfigurasinya mengikut keperluan mereka sendiri.
Sebaliknya, bagi pengguna yang lebih suka kemudahan dan fleksibiliti, produk SaaS berasaskan awan juga disediakan. Anda boleh memilih untuk mendaftar untuk mengakses dan menggunakan Arthur Bench melalui awan. Kaedah ini menghapuskan keperluan untuk pemasangan dan konfigurasi tempatan yang menyusahkan, dan membolehkan anda menikmati fungsi dan perkhidmatan yang disediakan dengan segera.
Sebagai projek sumber terbuka, Arthur Bench menunjukkan ciri sumber terbuka biasa dari segi ketelusan, skalabiliti dan kerjasama komuniti. Sifat sumber terbuka ini memberikan pengguna dengan banyak kelebihan dan peluang untuk mendapatkan pemahaman yang lebih mendalam tentang cara projek itu berfungsi, dan untuk menyesuaikan serta memanjangkannya agar sesuai dengan keperluan mereka. Pada masa yang sama, keterbukaan Arthur Bench juga menggalakkan pengguna untuk mengambil bahagian secara aktif dalam kerjasama komuniti, bekerjasama dan membangun dengan pengguna lain. Model kerjasama terbuka ini membantu menggalakkan pembangunan berterusan dan inovasi projek, di samping mewujudkan nilai dan peluang yang lebih besar untuk pengguna.
Ringkasnya, Arthur Bench menyediakan rangka kerja terbuka dan fleksibel yang membolehkan pengguna menyesuaikan penunjuk penilaian, dan telah digunakan secara meluas dalam bidang kewangan. Perkongsian dengan Amazon Web Services dan Cohere memajukan lagi rangka kerja, menggalakkan pembangun untuk mencipta metrik baharu untuk Bench dan menyumbang kepada kemajuan dalam bidang penilaian model bahasa.
Rujukan:
Atas ialah kandungan terperinci Fahami rangka kerja penilaian LLM Arthur Bench dalam satu artikel. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 Tiga kaedah virtualisasi gpu
Tiga kaedah virtualisasi gpu
 Pengenalan kepada alat pengesanan SSL
Pengenalan kepada alat pengesanan SSL
 Apakah jenis pemilih css yang ada?
Apakah jenis pemilih css yang ada?
 fungsi kunci prtscr
fungsi kunci prtscr
 Bagaimana untuk membatalkan pembaharuan automatik di Stesen B
Bagaimana untuk membatalkan pembaharuan automatik di Stesen B
 Platform dagangan mata wang digital rasmi
Platform dagangan mata wang digital rasmi








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



