
 Peranti teknologi
AI
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Peranti teknologi
AI
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat

1. Pengenalan
Pengesan objek utama semasa ialah rangkaian dua peringkat atau satu peringkat berdasarkan rangkaian pengelas tulang belakang yang digunakan semula dari deep CNN. YOLOv3 ialah salah satu pengesan satu peringkat tercanggih yang menerima imej input dan membahagikannya kepada matriks grid bersaiz sama. Sel grid dengan pusat sasaran bertanggungjawab untuk mengesan sasaran tertentu.
Apa yang kami kongsikan hari ini adalah untuk mencadangkan kaedah matematik baharu, yang memperuntukkan berbilang grid kepada setiap sasaran untuk mencapai ramalan kotak sempadan ketat yang tepat. Para penyelidik juga mencadangkan peningkatan data salin-tampal luar talian yang berkesan untuk pengesanan sasaran. Kaedah yang baru dicadangkan dengan ketara mengatasi beberapa pengesan objek terkini dan menjanjikan prestasi yang lebih baik. 2. Latar Belakang
Rangkaian pengesanan objek direka untuk mencari objek pada imej dan melabelkannya dengan tepat menggunakan kotak sempadan padanan tepat. Baru-baru ini, terdapat dua cara berbeza untuk mencapai matlamat ini. Kaedah pertama adalah dari segi prestasi Kaedah yang paling penting ialah pengesanan objek dua peringkat Wakil terbaik ialah rangkaian saraf konvolusi serantau (RCNN) dan terbitannya [R-CNN yang lebih pantas: Ke arah pengesanan objek masa nyata dengan cadangan wilayah] rangkaian], [R-CNN pantas]. Sebaliknya, kumpulan kedua pelaksanaan pengesanan objek terkenal dengan kelajuan pengesanan yang sangat baik dan ringan, dan dipanggil rangkaian satu peringkat Contoh yang mewakili ialah [Anda hanya melihat sekali: Pengesanan objek masa nyata bersatu], [SSD:. Pengesan kotak berbilang pukulan tunggal], [Kehilangan fokus untuk pengesanan objek padat]. Rangkaian dua peringkat bergantung pada rangkaian cadangan wilayah terpendam yang menjana kawasan calon imej yang mungkin mengandungi objek yang diminati. Kawasan calon yang dijana oleh rangkaian ini boleh mengandungi kawasan objek yang diminati Dalam pengesanan objek satu peringkat, pengesanan dikendalikan serentak dengan pengelasan dan penyetempatan dalam laluan ke hadapan yang lengkap. Oleh itu, rangkaian satu peringkat biasanya lebih ringan, lebih pantas dan lebih mudah untuk dilaksanakan.
 Penyelidikan hari ini masih mematuhi kaedah YOLO, terutamanya YOLOv3, dan mencadangkan penggodaman mudah yang boleh menggunakan berbilang elemen unit rangkaian pada masa yang sama untuk meramal koordinat sasaran, kategori dan keyakinan sasaran. Rasional di sebalik elemen unit berbilang rangkaian bagi setiap objek adalah untuk meningkatkan kebarangkalian meramalkan kotak sempadan yang sesuai dengan memaksa berbilang elemen unit berfungsi pada objek yang sama. . koordinat.
Penyelidikan hari ini masih mematuhi kaedah YOLO, terutamanya YOLOv3, dan mencadangkan penggodaman mudah yang boleh menggunakan berbilang elemen unit rangkaian pada masa yang sama untuk meramal koordinat sasaran, kategori dan keyakinan sasaran. Rasional di sebalik elemen unit berbilang rangkaian bagi setiap objek adalah untuk meningkatkan kebarangkalian meramalkan kotak sempadan yang sesuai dengan memaksa berbilang elemen unit berfungsi pada objek yang sama. . koordinat.
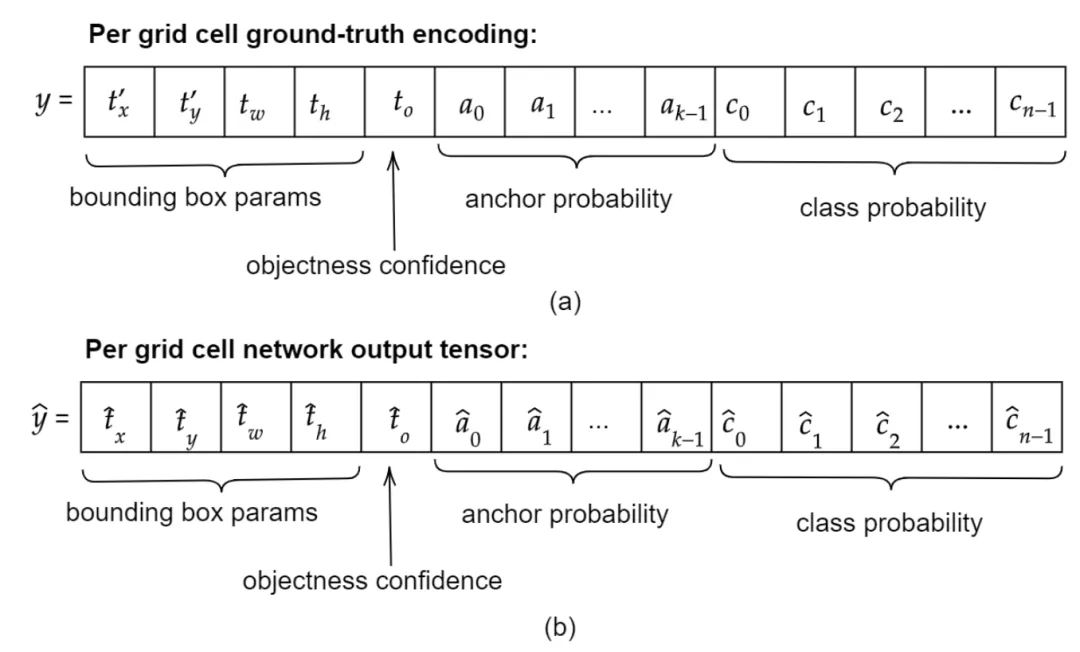
(b+) Ramalan kotak sempadan yang kurang rawak dan tidak pasti, yang bermaksud ketepatan tinggi dan ingat semula kerana unit rangkaian berdekatan dilatih untuk meramalkan kategori dan koordinat objek yang sama

Tambahan pula, memandangkan peruntukan berbilang grid ialah penggunaan matematik parameter sedia ada dan tidak memerlukan lapisan pengumpulan titik kunci tambahan dan pasca pemprosesan untuk menggabungkan semula titik kunci kepada sasaran yang sepadan, seperti CenterNet dan CornerNet, boleh dikatakan ia ialah cara yang lebih semula jadi untuk mencapai apa yang cuba dicapai oleh pengesan objek tanpa sauh atau berasaskan titik kunci. Sebagai tambahan kepada anotasi berlebihan berbilang grid, para penyelidik juga memperkenalkan teknologi peningkatan data berasaskan salin-tampal luar talian baharu untuk pengesanan objek yang tepat.
3. TUGASAN MULTI-GRID
Gambar di atas mengandungi tiga sasaran iaitu anjing, basikal dan kereta. Untuk kepentingan ringkas, kami akan menerangkan tugasan berbilang grid kami pada satu objek. Imej di atas menunjukkan kotak pembatas tiga objek, dengan lebih terperinci mengenai kotak pembatas anjing itu. Imej di bawah menunjukkan kawasan zum keluar bagi imej di atas, memfokus pada bahagian tengah kotak sempadan anjing. Koordinat kiri atas sel grid yang mengandungi pusat kotak sempadan anjing dilabelkan dengan nombor 0, manakala lapan sel grid lain yang mengelilingi grid yang mengandungi pusat mempunyai label dari 1 hingga 8.
Setakat ini saya telah menerangkan fakta asas tentang bagaimana jaringan yang mengandungi pusat kotak sempadan objek menganotasi objek. Kebergantungan pada hanya satu sel grid bagi setiap objek untuk melakukan kerja yang sukar untuk meramalkan kategori dan kotak pembatas ketat yang tepat menimbulkan banyak isu, seperti:
(a) Jurang yang besar antara grid positif dan negatif Ketidakseimbangan, iaitu, dengan dan tanpa koordinat grid pusat objek
(b) Penumpuan kotak sempadan perlahan kepada GT
(c) Kekurangan pandangan berbilang perspektif (sudut) objek yang akan diramalkan.
Jadi soalan semula jadi untuk ditanya di sini ialah, "Jelas sekali, kebanyakan objek mengandungi kawasan lebih daripada satu sel grid, jadi adakah terdapat cara matematik mudah untuk memperuntukkan lebih banyak sel grid ini untuk cuba meramalkan kategori dan koordinat objek bersama sel grid tengah?" Beberapa kelebihan ini adalah (a) ketidakseimbangan yang dikurangkan, (b) latihan yang lebih pantas untuk menumpu kepada kotak pembatas kerana kini beberapa sel grid menyasarkan objek yang sama secara serentak, (c) peningkatan ramalan kotak pembatas ketat Peluang (d) menyediakan grid- pengesan berasaskan seperti YOLOv3 dengan pandangan berbilang paparan dan bukannya pandangan satu titik objek. Peruntukan multigrid yang baru dicadangkan cuba menjawab soalan di atas. . s untuk menjadikannya lebih ringan dan lebih pantas. Blok lilitan mempunyai Conv2D+Batch Normalization+LeakyRelu. Blok yang dikeluarkan bukan dari tulang belakang klasifikasi, iaitu Darknet53. Sebaliknya, alih keluar mereka daripada tiga rangkaian output pengesanan berbilang skala atau kepala, dua daripada setiap rangkaian output. Walaupun rangkaian dalam secara amnya berprestasi baik, rangkaian yang terlalu dalam juga cenderung terlalu pantas atau memperlahankan rangkaian dengan ketara. B. Fungsi Kehilangan sintesis imej latihan berfungsi seperti berikut : Pertama, menggunakan skrip carian imej ringkas untuk memuat turun beribu-ribu imej tanpa objek latar belakang daripada Imej Google menggunakan kata kunci seperti mercu tanda, hujan, hutan, dll., iaitu imej tanpa objek yang menarik minat kami. Kami kemudian secara berulang memilih objek p dan kotak sempadannya daripada imej q rawak keseluruhan set data latihan. Kami kemudian menjana semua kemungkinan kombinasi kotak sempadan p yang dipilih menggunakan indeksnya sebagai ID. Daripada set gabungan, kami memilih subset kotak sempadan yang memenuhi dua syarat berikut:

jika disusun dalam beberapa susunan rawak bersebelahan, ia mesti dimuatkan dalam kawasan imej latar belakang sasaran yang diberikan
dan sepatutnya menggunakan ruang imej latar belakang secara keseluruhan atau sekurang-kurangnya sebahagian besar tanpa objek bertindih Perbandingan prestasi pada dataset coco
Seperti yang dapat dilihat dari rajah, baris pertama menunjukkan enam. imej input, manakala baris kedua menunjukkan rangkaian sebelum penindasan bukan maksimum (NMS) Baris terakhir menunjukkan ramalan kotak sempadan terakhir MultiGridDet untuk imej input selepas NMS.
Atas ialah kandungan terperinci Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1664
1664
 14
1422
52
1316
25
1267
29
1239
24
14
1422
52
1316
25
1267
29
1239
24

 Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
1. Pengenalan Pada masa ini, pengesan objek utama ialah rangkaian dua peringkat atau satu peringkat berdasarkan rangkaian pengelas tulang belakang yang digunakan semula CNN dalam. YOLOv3 ialah salah satu pengesan satu peringkat tercanggih yang menerima imej input dan membahagikannya kepada matriks grid bersaiz sama. Sel grid dengan pusat sasaran bertanggungjawab untuk mengesan sasaran tertentu. Apa yang saya kongsikan hari ini ialah kaedah matematik baharu yang memperuntukkan berbilang grid kepada setiap sasaran untuk mencapai ramalan kotak sempadan ketat muat yang tepat. Para penyelidik juga mencadangkan peningkatan data salin-tampal luar talian yang berkesan untuk pengesanan sasaran. Kaedah yang baru dicadangkan dengan ketara mengatasi beberapa pengesan objek terkini dan menjanjikan prestasi yang lebih baik. 2. Rangkaian pengesanan sasaran latar belakang direka bentuk untuk digunakan
 SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
Dalam bidang pengesanan sasaran, YOLOv9 terus membuat kemajuan dalam proses pelaksanaan Dengan mengguna pakai seni bina dan kaedah baharu, ia secara berkesan meningkatkan penggunaan parameter konvolusi tradisional, yang menjadikan prestasinya jauh lebih unggul daripada produk generasi sebelumnya. Lebih setahun selepas YOLOv8 dikeluarkan secara rasmi pada Januari 2023, YOLOv9 akhirnya hadir! Sejak Joseph Redmon, Ali Farhadi dan yang lain mencadangkan model YOLO generasi pertama pada 2015, penyelidik dalam bidang pengesanan sasaran telah mengemas kini dan mengulanginya berkali-kali. YOLO ialah sistem ramalan berdasarkan maklumat global imej, dan prestasi modelnya terus dipertingkatkan. Dengan menambah baik algoritma dan teknologi secara berterusan, penyelidik telah mencapai hasil yang luar biasa, menjadikan YOLO semakin berkuasa dalam tugas pengesanan sasaran.
 Langkah untuk menyediakan grid kamera pada iPhone
Mar 26, 2024 pm 07:21 PM
Langkah untuk menyediakan grid kamera pada iPhone
Mar 26, 2024 pm 07:21 PM
1. Buka desktop iPhone anda, cari dan klik untuk memasuki [Settings], 2. Klik untuk memasukkan [Camera] pada halaman tetapan. 3. Klik untuk menghidupkan suis di sebelah kanan [Grid].
 Bagaimana untuk menggunakan C++ untuk penjejakan imej berprestasi tinggi dan pengesanan sasaran?
Aug 26, 2023 pm 03:25 PM
Bagaimana untuk menggunakan C++ untuk penjejakan imej berprestasi tinggi dan pengesanan sasaran?
Aug 26, 2023 pm 03:25 PM
Bagaimana untuk menggunakan C++ untuk penjejakan imej berprestasi tinggi dan pengesanan sasaran? Abstrak: Dengan perkembangan pesat kecerdasan buatan dan teknologi penglihatan komputer, pengesanan imej dan pengesanan sasaran telah menjadi bidang penyelidikan yang penting. Artikel ini akan memperkenalkan cara untuk mencapai penjejakan imej berprestasi tinggi dan pengesanan sasaran dengan menggunakan bahasa C++ dan beberapa perpustakaan sumber terbuka serta menyediakan contoh kod. Pengenalan: Penjejakan imej dan pengesanan objek adalah dua tugas penting dalam bidang penglihatan komputer. Ia digunakan secara meluas dalam banyak bidang, seperti pengawasan video, pemanduan autonomi, sistem pengangkutan pintar, dll. untuk
 Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Kertas kerja ini membincangkan bidang pengesanan objek 3D, terutamanya pengesanan objek 3D untuk Open-Vocabulary. Dalam tugas pengesanan objek 3D tradisional, sistem perlu meramalkan lokasi objek dalam adegan sebenar kotak sempadan 3D dan label kategori semantik, yang biasanya bergantung pada awan titik atau imej RGB. Walaupun teknologi pengesanan objek 2D berprestasi baik kerana keluasan dan kelajuannya, penyelidikan berkaitan menunjukkan bahawa pembangunan pengesanan universal 3D ketinggalan berbanding perbandingan. Pada masa ini, kebanyakan kaedah pengesanan objek 3D masih bergantung pada pembelajaran diselia sepenuhnya dan dihadkan oleh data beranotasi sepenuhnya di bawah mod input tertentu dan hanya boleh mengecam kategori yang muncul semasa latihan, sama ada dalam adegan dalaman atau luaran. Makalah ini menunjukkan bahawa cabaran yang dihadapi oleh pengesanan sasaran universal 3D adalah terutamanya
 Petua Reka Letak CSS: Amalan Terbaik untuk Melaksanakan Reka Letak Ikon Grid Pekeliling
Oct 20, 2023 am 10:46 AM
Petua Reka Letak CSS: Amalan Terbaik untuk Melaksanakan Reka Letak Ikon Grid Pekeliling
Oct 20, 2023 am 10:46 AM
Petua Reka Letak CSS: Amalan Terbaik untuk Melaksanakan Tataletak Ikon Grid Pekeliling Susun atur Grid ialah teknik reka letak yang biasa dan berkuasa dalam reka bentuk web moden. Susun atur ikon grid bulat adalah pilihan reka bentuk yang lebih unik dan menarik. Artikel ini akan memperkenalkan beberapa amalan terbaik dan contoh kod khusus untuk membantu anda melaksanakan reka letak ikon grid bulat. Struktur HTML Mula-mula, kita perlu menyediakan elemen bekas dan letakkan ikon dalam bekas ini. Kita boleh menggunakan senarai tidak tertib (<ul>) sebagai bekas dan item senarai (<l
 Contoh Penglihatan Komputer dalam Python: Pengesanan Objek
Jun 10, 2023 am 11:36 AM
Contoh Penglihatan Komputer dalam Python: Pengesanan Objek
Jun 10, 2023 am 11:36 AM
Dengan perkembangan kecerdasan buatan, teknologi penglihatan komputer telah menjadi salah satu tumpuan perhatian orang ramai. Sebagai bahasa pengaturcaraan yang cekap dan mudah dipelajari, Python telah diiktiraf dan dipromosikan secara meluas dalam bidang penglihatan komputer. Artikel ini akan menumpukan pada contoh penglihatan komputer dalam Python: pengesanan objek. Apakah pengesanan objek? Pengesanan objek adalah teknologi utama dalam bidang penglihatan komputer Tujuannya adalah untuk mengenal pasti lokasi dan saiz objek tertentu dalam gambar atau video. Berbanding dengan klasifikasi imej, pengesanan sasaran bukan sahaja memerlukan imej pengenalan
 Seni bina dalam terkini untuk pengesanan sasaran mempunyai separuh parameter dan 3 kali lebih pantas +
Apr 09, 2023 am 11:41 AM
Seni bina dalam terkini untuk pengesanan sasaran mempunyai separuh parameter dan 3 kali lebih pantas +
Apr 09, 2023 am 11:41 AM
Pengenalan Ringkas Penulis kajian mencadangkan Matrix Net (xNet), seni bina dalam baharu untuk pengesanan objek. xNets memetakan objek dengan dimensi saiz dan nisbah bidang yang berbeza ke dalam lapisan rangkaian, di mana objek hampir seragam dalam saiz dan nisbah bidang dalam lapisan. Oleh itu, xNets menyediakan seni bina sedar saiz dan nisbah aspek. Penyelidik menggunakan xNets untuk meningkatkan pengesanan sasaran berasaskan titik kunci. Seni bina baharu mencapai kecekapan masa yang lebih tinggi daripada pengesan satu tangkapan lain, dengan 47.8 mAP pada set data MS COCO, sambil menggunakan separuh parameter dan menjadi 3 kali lebih pantas untuk melatih daripada rangka kerja terbaik seterusnya. Seperti yang ditunjukkan dalam paparan hasil mudah di atas, parameter dan kecekapan xNet jauh melebihi model lain.
