
 Peranti teknologi
AI
DiffMap: rangkaian pertama yang menggunakan LDM untuk meningkatkan pembinaan peta berketepatan tinggi
Peranti teknologi
AI
DiffMap: rangkaian pertama yang menggunakan LDM untuk meningkatkan pembinaan peta berketepatan tinggi
DiffMap: rangkaian pertama yang menggunakan LDM untuk meningkatkan pembinaan peta berketepatan tinggi

Tajuk kertas:
DiffMap: Mempertingkatkan Segmentasi Peta dengan Peta Sebelum Menggunakan Model Resapan
Pengarang kertas:
quan Lei, Xuewei Tang, Ziyuan Liu, Le Cui, Kehua Sheng, Bo Zhang, Diange Yang
01 Pengenalan Latar Belakang
Untuk kenderaan pandu sendiri, peta definisi tinggi (HD) boleh membantu mereka meningkatkan pemahaman mereka tentang alam sekitar (persepsi) ) ketepatan dan ketepatan navigasi. Walau bagaimanapun, pemetaan manual menghadapi masalah kerumitan dan kos yang tinggi. Untuk tujuan ini, penyelidikan semasa mengintegrasikan pembinaan peta ke dalam tugas persepsi BEV (pandangan mata burung) Membina peta HD raster dalam ruang BEV dianggap sebagai tugas pembahagian, yang boleh difahami sebagai menambah penggunaan sesuatu yang serupa dengan FCN. (volume penuh) selepas mendapat ciri BEV ketua segmentasi rangkaian produk). Contohnya, HDMapNet mengekodkan ciri sensor melalui LSS (Lift, Splat, Shoot), dan kemudian menggunakan FCN berbilang resolusi untuk segmentasi semantik, pengesanan contoh dan ramalan arah untuk membina peta.
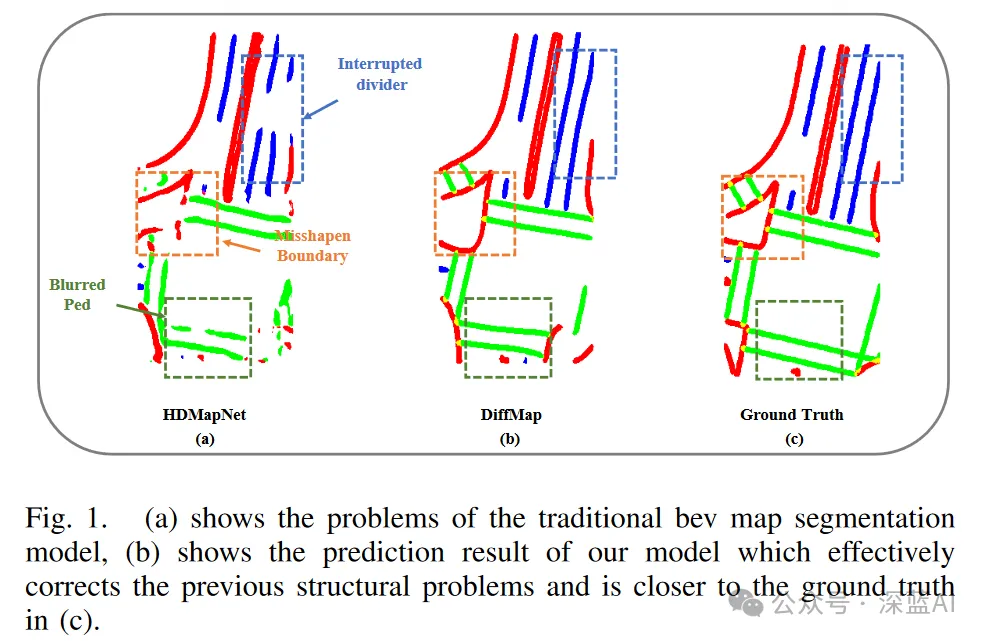
Walau bagaimanapun, pada masa ini kaedah sedemikian (kaedah pengelasan berasaskan piksel) masih mempunyai batasan yang wujud, termasuk kemungkinan mengabaikan atribut pengelasan tertentu, yang boleh membawa kepada herotan dan gangguan median, lintasan pejalan kaki yang kabur dan jenis artifak dan hingar , seperti yang ditunjukkan dalam Rajah 1(a). Masalah ini bukan sahaja menjejaskan ketepatan struktur peta, tetapi juga boleh menjejaskan secara langsung modul perancangan laluan hiliran sistem pemanduan autonomi. . ciri-ciri garisan lorong. Sesetengah model generatif mempunyai keupayaan ini dalam menangkap keaslian dan ciri-ciri yang wujud bagi imej. Sebagai contoh, LDM (Model Resapan Terpendam) telah menunjukkan potensi besar dalam penjanaan imej kesetiaan tinggi dan membuktikan keberkesanannya dalam tugas yang berkaitan dengan peningkatan segmentasi. Di samping itu, pembolehubah kawalan boleh diperkenalkan untuk terus membimbing penjanaan imej untuk memenuhi keperluan kawalan khusus. Oleh itu, menggunakan model generatif untuk menangkap struktur peta sebelum ini dijangka dapat mengurangkan artifak pembahagian dan meningkatkan prestasi pembinaan peta.
Dalam artikel ini, penulis menyebut rangkaian DiffMap. Buat pertama kalinya, rangkaian ini melaksanakan pemodelan terdahulu berstruktur peta pada model segmentasi sedia ada dan menyokong pasang dan main dengan menggunakan LDM yang dipertingkatkan sebagai modul peningkatan. DiffMap bukan sahaja mempelajari peta sebelum melalui proses menambah dan mengalih keluar hingar untuk memastikan output sepadan dengan cerapan bingkai semasa, ia juga boleh menyepadukan ciri BEV sebagai isyarat kawalan untuk memastikan output sepadan dengan cerapan bingkai semasa. Keputusan percubaan menunjukkan bahawa DiffMap boleh menjana hasil pembahagian peta yang lebih lancar dan lebih munasabah, sambil mengurangkan artifak dan meningkatkan prestasi pembinaan peta secara keseluruhan.
02 Kerja Berkaitan2.1 Pembinaan Peta Semantik
Dalam pembinaan peta definisi tinggi (HD) tradisional, peta semantik biasanya secara manual atau separa automatik beranotasi awan. Secara amnya, peta yang konsisten secara global dibina berdasarkan algoritma SLAM, dan anotasi semantik ditambah secara manual pada peta. Walau bagaimanapun, pendekatan ini memakan masa dan intensif buruh dan juga memberikan cabaran penting dalam mengemas kini peta, sekali gus mengehadkan kebolehskalaan dan prestasi masa nyatanya.
HDMapNet mencadangkan kaedah untuk membina peta semantik tempatan secara dinamik menggunakan penderia on-board. Ia mengekod awan titik lidar dan ciri imej panoramik ke dalam ruang Pandangan Mata Burung (BEV) dan menyahkodnya menggunakan tiga kepala berbeza, akhirnya menghasilkan peta semantik tempatan tervektor. SuperFusion memfokuskan pada membina peta semantik ketepatan tinggi jarak jauh, menggunakan maklumat kedalaman lidar untuk meningkatkan anggaran kedalaman imej dan menggunakan ciri imej untuk membimbing ramalan ciri lidar jarak jauh. Kemudian kepala pengesanan peta yang serupa dengan HDMapNet digunakan untuk mendapatkan peta semantik. MachMap membahagikan tugas kepada pengesanan garisan poli dan pembahagian contoh poligon, dan menggunakan pemprosesan pasca untuk memperhalusi topeng untuk mendapatkan hasil akhir. Penyelidikan seterusnya memfokuskan pada pemetaan dalam talian hujung ke hujung untuk mendapatkan peta definisi tinggi bervektor secara langsung. Pembinaan dinamik peta semantik tanpa anotasi manual secara berkesan mengurangkan kos pembinaan.
2.2 Model resapan yang digunakan untuk segmentasi dan pengesanan kepada pelbagai tugas seperti segmentasi dan pengesanan. SegDiff menggunakan model resapan pada tugas pembahagian imej, di mana pengekod UNet yang digunakan dipisahkan lagi kepada tiga modul: E, F dan G. Modul G dan F masing-masing mengekod imej input I dan peta pembahagian, yang kemudiannya digabungkan secara tambahan dalam E untuk memperhalusi peta pembahagian secara berulang. DDPMS menggunakan model segmentasi asas untuk menjana ramalan awal sebelum dan model resapan untuk memperhalusi sebelumnya. DiffusionDet memanjangkan model resapan kepada rangka kerja pengesanan sasaran, memodelkan pengesanan sasaran sebagai proses resapan mengecil daripada kotak hingar ke kotak sasaran.
Model resapan juga digunakan dalam bidang pemanduan autonomi, seperti MagicDrive menggunakan kekangan geometri untuk mensintesis pemandangan jalanan, dan Motiondiffuser memanjangkan model resapan kepada masalah ramalan gerakan berbilang ejen. . MapLite2.0 mengambil peta terdahulu definisi standard (SD) sebagai titik permulaan dan menggabungkannya dengan penderia on-board untuk membuat kesimpulan peta definisi tinggi tempatan dalam masa nyata. MapEx dan SMERF memanfaatkan data peta standard untuk meningkatkan kesedaran lorong dan pemahaman topologi. SMERF mengguna pakai pengekod peta standard berasaskan Transformer untuk mengekodkan garisan lorong dan jenis lorong, dan kemudian mengira perhatian silang antara maklumat peta standard dan ciri pandangan mata burung (BEV) berasaskan sensor untuk menyepadukan maklumat peta standard. NMP menyediakan keupayaan ingatan jangka panjang untuk kenderaan autonomi dengan menggabungkan data terdahulu peta lalu dengan data persepsi semasa. MapPrior menggabungkan model diskriminatif dan generatif, pengekodan ramalan awal yang dijana berdasarkan model sedia ada sebagai prior semasa fasa ramalan, menyuntik ruang terpendam diskret model generatif, dan kemudian menggunakan model generatif untuk memperhalusi ramalan. PreSight menggunakan data daripada perjalanan sebelumnya untuk mengoptimumkan medan sinaran saraf skala bandar, menjana prior saraf dan meningkatkan persepsi dalam talian dalam navigasi seterusnya.
03 Analisis Kaedah3.1 Persediaan

 Seperti yang ditunjukkan dalam Rajah 2. Sebagai penyahkod, DiffMap menggabungkan model resapan ke dalam model segmentasi peta semantik, yang mengambil imej berbilang paparan di sekeliling dan awan titik LiDAR sebagai input, mengekodnya ke dalam ruang BEV dan memperoleh ciri BEV yang digabungkan. Kemudian DiffMap digunakan sebagai penyahkod untuk menjana peta segmentasi. Dalam modul DiffMap, ciri BEV digunakan sebagai syarat untuk membimbing proses denoising. . Bahagian pengekod bertanggungjawab untuk mengekstrak ciri daripada data input (LiDAR dan/atau data kamera) dan menukarnya kepada perwakilan dimensi tinggi. Pada masa yang sama, penyahkod biasanya bertindak sebagai kepala pembahagian untuk memetakan perwakilan ciri dimensi tinggi kepada peta pembahagian yang sepadan. Baseline memainkan dua peranan utama dalam rangka kerja keseluruhan: penyelia dan pengawal. Sebagai penyelia, garis dasar menjana hasil pembahagian sebagai penyeliaan tambahan. Pada masa yang sama, sebagai pengawal, ia menyediakan ciri-ciri BEV perantaraan sebagai pembolehubah kawalan bersyarat untuk membimbing proses penjanaan model resapan.
Seperti yang ditunjukkan dalam Rajah 2. Sebagai penyahkod, DiffMap menggabungkan model resapan ke dalam model segmentasi peta semantik, yang mengambil imej berbilang paparan di sekeliling dan awan titik LiDAR sebagai input, mengekodnya ke dalam ruang BEV dan memperoleh ciri BEV yang digabungkan. Kemudian DiffMap digunakan sebagai penyahkod untuk menjana peta segmentasi. Dalam modul DiffMap, ciri BEV digunakan sebagai syarat untuk membimbing proses denoising. . Bahagian pengekod bertanggungjawab untuk mengekstrak ciri daripada data input (LiDAR dan/atau data kamera) dan menukarnya kepada perwakilan dimensi tinggi. Pada masa yang sama, penyahkod biasanya bertindak sebagai kepala pembahagian untuk memetakan perwakilan ciri dimensi tinggi kepada peta pembahagian yang sepadan. Baseline memainkan dua peranan utama dalam rangka kerja keseluruhan: penyelia dan pengawal. Sebagai penyelia, garis dasar menjana hasil pembahagian sebagai penyeliaan tambahan. Pada masa yang sama, sebagai pengawal, ia menyediakan ciri-ciri BEV perantaraan sebagai pembolehubah kawalan bersyarat untuk membimbing proses penjanaan model resapan.
◆Modul DiffMap:
Susulan LDM, pengarang memperkenalkan modul DiffMap sebagai penyahkod dalam rangka kerja garis dasar. LDM terutamanya terdiri daripada dua bahagian: modul pemampatan sedar imej (seperti VQVAE) dan model resapan yang dibina menggunakan UNet. Pertama, pengekod mengekod kebenaran tanah pembahagian peta ke dalam ruang terpendam, yang mewakili dimensi rendah ruang terpendam. Selepas itu, resapan dan denoising dilakukan dalam ruang pembolehubah pendam berdimensi rendah, dan penyahkod digunakan untuk memulihkan ruang terpendam kepada ruang piksel asal.
Mula-mula tambah hingar melalui proses resapan, dan dapatkan peta potensi hingar pada setiap langkah masa, di mana . Kemudian semasa proses denoising, UNet berfungsi sebagai rangkaian tulang belakang untuk ramalan bunyi. Untuk meningkatkan bahagian penyeliaan hasil segmentasi, model DiffMap dijangka secara langsung menyediakan ciri semantik untuk ramalan berkaitan contoh semasa latihan. Oleh itu, penulis membahagikan struktur rangkaian UNet kepada dua cawangan, satu cawangan digunakan untuk meramalkan bunyi, seperti model resapan tradisional, dan cawangan lain digunakan untuk meramalkan bunyi dalam ruang terpendam. 
▲Rajah 3|Modul denosing
Seluruh proses adalah proses penjanaan bersyarat, dan hasil pembahagian peta diperoleh berdasarkan input sensor semasa. Taburan kebarangkalian keputusan boleh dimodelkan sebagai, di mana mewakili hasil pembahagian peta dan mewakili pembolehubah kawalan bersyarat, iaitu ciri BEV. Penulis menggunakan dua kaedah untuk menyepadukan pembolehubah kawalan di sini. Pertama, memandangkan ciri BEV dan BEV mempunyai kategori dan skala yang sama dalam domain spatial, ia akan diselaraskan kepada saiz ruang terpendam, dan kemudian ia digabungkan sebagai input proses penyahnosan, seperti yang ditunjukkan dalam Persamaan 5.
Kedua, mekanisme perhatian silang disepadukan ke dalam setiap lapisan rangkaian UNet, sebagai kunci/nilai dan pertanyaan. Formula modul perhatian silang adalah seperti berikut:
3.3 Pelaksanaan khusus
◆Latihan:


04 Eksperimen
4.1 Butiran percubaan ◆Set Data:
Sahkan DiffMap pada set data nuScenes. Set data nuScenes mengandungi imej berbilang paparan dan awan titik sebanyak 1000 adegan, yang mana 700 adegan digunakan untuk latihan, 150 untuk pengesahan dan 150 untuk ujian. Dataset nuScenes juga mengandungi label semantik peta HD beranotasi. ◆Seni bina:
Gunakan ResNet-101 sebagai rangkaian tulang belakang cawangan kamera, dan gunakan PointPillars sebagai rangkaian tulang belakang cawangan LiDAR model. Ketua pembahagian dalam model garis dasar ialah rangkaian FCN berasaskan ResNet-18. Untuk pengekod auto, VQVAE digunakan dan model ini telah dilatih terlebih dahulu pada set data peta bersegmen nuScenes untuk mengekstrak ciri peta dan memampatkan peta menjadi ruang terpendam asas. Akhirnya, UNet digunakan untuk membina rangkaian penyebaran. ◆Butiran latihan:
Gunakan pengoptimum AdamW untuk melatih model VQVAE selama 30 zaman. Penjadual kadar pembelajaran yang digunakan ialah LambdaLR, yang secara beransur-ansur mengurangkan kadar pembelajaran dalam mod pereputan eksponen dengan faktor pereputan 0.95. Kadar pembelajaran awal ditetapkan kepada , dan saiz kelompok ialah 8. Kemudian, model resapan dilatih dari awal menggunakan pengoptimum AdamW selama 30 zaman dengan kadar pembelajaran awal 2e-4. Penjadual MultiStepLR diguna pakai, yang melaraskan kadar pembelajaran mengikut titik masa pencapaian yang ditentukan (0.7, 0.9, 1.0) dan faktor skala 1/3 pada peringkat latihan yang berbeza. Akhir sekali, hasil pembahagian BEV ditetapkan kepada resolusi 0.15m, dan awan titik LiDAR divoxelkan. Julat pengesanan HDMapNet ialah [-30m, 30m]×[-15m, 15m]m, jadi saiz peta BEV yang sepadan ialah 400×200, manakala Superfusion menggunakan [0m, 90m]×[-15m, 15m] dan mendapat 600 × 200 hasil. Disebabkan oleh kekangan dimensi LDM (pensampelan turun 8x dalam VAE dan UNet), saiz peta kebenaran asas semantik perlu dipadatkan kepada gandaan 64. ◆Butiran inferens:
Hasil ramalan diperoleh dengan melakukan proses denoising pada peta hingar sebanyak 20 kali di bawah keadaan ciri BEV semasa. Purata 3 sampel digunakan sebagai hasil ramalan akhir.
4.2 Penunjuk penilaian
 dinilai terutamanya untuk tugasan segmentasi semantik peta dan pengesanan contoh. Dan ia tertumpu terutamanya pada tiga elemen peta statik: sempadan lorong, pembahagi lorong dan lintasan pejalan kaki.
dinilai terutamanya untuk tugasan segmentasi semantik peta dan pengesanan contoh. Dan ia tertumpu terutamanya pada tiga elemen peta statik: sempadan lorong, pembahagi lorong dan lintasan pejalan kaki.

4.3 Keputusan penilaian
 Jadual 1 menunjukkan perbandingan skor IoU untuk peta semantik DiffMap menunjukkan peningkatan yang ketara dalam semua selang, mencapai hasil terbaik terutamanya pada pembahagi lorong dan lintasan pejalan kaki.
Jadual 1 menunjukkan perbandingan skor IoU untuk peta semantik DiffMap menunjukkan peningkatan yang ketara dalam semua selang, mencapai hasil terbaik terutamanya pada pembahagi lorong dan lintasan pejalan kaki.
▲Jadual 1|Perbandingan skor IoU
 Seperti yang ditunjukkan dalam Jadual 2, kaedah DiffMap juga mempunyai peningkatan ketara dalam ketepatan purata (AP), yang mengesahkan keberkesanan DiffMap.
Seperti yang ditunjukkan dalam Jadual 2, kaedah DiffMap juga mempunyai peningkatan ketara dalam ketepatan purata (AP), yang mengesahkan keberkesanan DiffMap.
Seperti yang ditunjukkan dalam Jadual 3, apabila paradigma DiffMap disepadukan ke dalam HDMapNet, dapat diperhatikan bahawa DiffMap boleh meningkatkan prestasi HDMapNet sama ada hanya menggunakan kamera atau kaedah gabungan kamera-lidar. Ini menunjukkan bahawa kaedah DiffMap berkesan dalam pelbagai tugasan segmentasi, termasuk pengesanan jarak jauh dan jarak dekat. Walau bagaimanapun, untuk sempadan, DiffMap tidak berfungsi dengan baik kerana struktur bentuk sempadan tidak tetap dan terdapat banyak herotan yang tidak dapat diramalkan, yang menjadikannya sukar untuk menangkap ciri struktur priori.
 ▲Jadual 3|Hasil analisis kuantitatif
▲Jadual 3|Hasil analisis kuantitatif
4.4 Eksperimen Ablasi
Jadual 4 menunjukkan kesan dalam keputusan VQEmpling yang berbeza Dengan menganalisis kelakuan DiffMap apabila faktor pensampelan turun ialah 4, 8, dan 16, kita dapat melihat bahawa apabila faktor pensampelan menurun ditetapkan kepada 8x, hasil terbaik diperoleh.
 ▲Jadual 4|Keputusan percubaan Ablasi
▲Jadual 4|Keputusan percubaan Ablasi
Selain itu, penulis juga mengukur kesan pemadaman modul ramalan berkaitan contoh pada model, seperti yang ditunjukkan dalam Jadual 5. Percubaan menunjukkan bahawa menambah ramalan ini meningkatkan lagi IOU.

▲ Jadual 5 | Hasil eksperimen ablasi (sama ada termasuk modul ramalan)
4.5 Visualisasi
Figure 4 menunjukkan perbandingan antara diffmap dan garis dasar (hdmapnet-fusion) dalam adegan kompleks. Adalah jelas bahawa hasil segmentasi garis dasar mengabaikan sifat bentuk dan konsistensi dalam elemen. Sebaliknya, DiffMap menunjukkan keupayaan untuk membetulkan isu ini, menghasilkan output pembahagian yang sejajar dengan spesifikasi peta. Khususnya, dalam kes (a), (b), (d), (e), (h) dan (l), DiffMap membetulkan laluan lintasan yang diramalkan secara tidak tepat. Dalam kes (c), (d), (h), (i), (j), dan (l), DiffMap melengkapkan atau mengalih keluar sempadan yang tidak tepat, menjadikan keputusan lebih hampir kepada geometri sempadan yang realistik. Tambahan pula, dalam kes (b), (f), (g), (h), (k) dan (l), DiffMap menyelesaikan masalah garis pemisah putus dan memastikan keselarian unsur-unsur bersebelahan. . dengan itu mempertingkatkan Model pembahagian peta tradisional diguna pakai. Kaedah ini boleh digunakan sebagai alat bantu untuk mana-mana model pembahagian peta, dan keputusan ramalannya dipertingkatkan dengan ketara dalam kedua-dua senario pengesanan jauh dan dekat. Memandangkan kaedah ini sangat berskala, ia sesuai untuk mengkaji jenis maklumat terdahulu yang lain Sebagai contoh, peta SD sebelum boleh disepadukan ke dalam modul kedua DiffMap untuk meningkatkan prestasinya. Dijangkakan bahawa kemajuan dalam pembinaan peta bervektor akan berterusan pada masa hadapan.

Atas ialah kandungan terperinci DiffMap: rangkaian pertama yang menggunakan LDM untuk meningkatkan pembinaan peta berketepatan tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1677
1677
 14
1430
52
1333
25
1278
29
1257
24
14
1430
52
1333
25
1278
29
1257
24

 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
