

LLM |. Yuan 2.0-M32: Model Campuran Pakar dengan Penghalaan Perhatian

. 2 daripada pakar ini aktif. Seni bina hibrid pakar yang mengandungi 32 pakar dicadangkan dan diguna pakai untuk memilih pakar dengan lebih cekap Berbanding dengan model yang menggunakan rangkaian penghalaan klasik, kadar ketepatan dipertingkatkan sebanyak 3.8%. Yuan+2.0-M32 dilatih dari awal, menggunakan token 2000B, dan penggunaan latihannya hanya 9.25% daripada model ensembel padat dengan saiz parameter yang sama. Untuk memilih pakar dengan lebih baik, penghala perhatian diperkenalkan, yang mempunyai keupayaan untuk mengesan dengan cepat dan dengan itu membolehkan pemilihan pakar yang lebih baik.
 Yuan 2.0-M32 telah menunjukkan keupayaan berdaya saing dalam pengekodan, matematik dan pelbagai bidang profesional, menggunakan hanya 3.7 bilion parameter aktif daripada 40 bilion jumlah parameter, dan pengiraan hadapan 7.4 GFlop setiap token. Kedua-dua penunjuk ini hanya 1/. 19 daripada Llama3-70B. Yuan 2.0-M32 mengatasi Llama3-70B dalam penanda aras MATH dan ARC-Challenge, dengan kadar ketepatan masing-masing mencapai 55.89% dan 95.8%. Model dan kod sumber Yuan 2.0-M32 ada di GitHub: https://github.com/IEIT-Yuan/Yuan2.0-M32. . mudah dibina dengan menambah bilangan pakar Skala yang lebih besar daripada model set padat, menghasilkan prestasi ketepatan yang lebih tinggi. Malah, apabila melatih model dengan sumber pengkomputeran terhad, MoE dilihat sebagai pilihan yang sangat baik untuk mengurangkan kos yang berkaitan dengan model, saiz set data dan kuasa pengkomputeran yang terhad.
Yuan 2.0-M32 telah menunjukkan keupayaan berdaya saing dalam pengekodan, matematik dan pelbagai bidang profesional, menggunakan hanya 3.7 bilion parameter aktif daripada 40 bilion jumlah parameter, dan pengiraan hadapan 7.4 GFlop setiap token. Kedua-dua penunjuk ini hanya 1/. 19 daripada Llama3-70B. Yuan 2.0-M32 mengatasi Llama3-70B dalam penanda aras MATH dan ARC-Challenge, dengan kadar ketepatan masing-masing mencapai 55.89% dan 95.8%. Model dan kod sumber Yuan 2.0-M32 ada di GitHub: https://github.com/IEIT-Yuan/Yuan2.0-M32. . mudah dibina dengan menambah bilangan pakar Skala yang lebih besar daripada model set padat, menghasilkan prestasi ketepatan yang lebih tinggi. Malah, apabila melatih model dengan sumber pengkomputeran terhad, MoE dilihat sebagai pilihan yang sangat baik untuk mengurangkan kos yang berkaitan dengan model, saiz set data dan kuasa pengkomputeran yang terhad.
Rangkaian penghalaan pakar adalah teras kepada struktur KPM. Struktur ini memilih pakar calon untuk mengambil bahagian dalam pengiraan dengan mengira kebarangkalian pemberian token kepada setiap pakar. Pada masa ini, dalam kebanyakan struktur MoE yang popular, algoritma penghalaan klasik biasanya digunakan, yang melaksanakan produk titik antara token dan vektor ciri setiap pakar dan memilih pakar dengan produk titik terbesar sebagai pemenang. Dalam pilihan ini, vektor ciri pakar adalah bebas dan korelasi antara pakar diabaikan. Walau bagaimanapun, struktur KPM biasanya memilih lebih daripada seorang pakar pada satu masa, dan mungkin terdapat korelasi antara ciri-ciri pakar yang berbeza. Oleh itu, dalam kes ini, vektor ciri yang dipilih mungkin mempunyai pertindihan dan konflik untuk produk titik antara setiap pakar yang terlibat dalam pengiraan, yang seterusnya menjejaskan ketepatan keputusan. Walau bagaimanapun, struktur MoE biasanya memilih lebih daripada seorang pakar pada satu masa, dan mungkin terdapat korelasi antara ciri pakar yang berbeza Oleh itu, dalam kes ini, vektor ciri yang dipilih oleh algoritma penghalaan klasik mungkin bertindih dan bercanggah, menjejaskan pengiraan. ketepatan. Untuk menyelesaikan masalah ini, struktur KPM sering menggunakan vektor ciri pakar bebas, yang bermaksud bahawa setiap pakar dianggap sebagai bebas sepenuhnya, manakala korelasi antara pakar diabaikan. Walau bagaimanapun, pendekatan ini boleh menyebabkan beberapa masalah. Oleh itu, apabila memilih pakar, struktur KPM biasanya memilih lebih daripada seorang pakar, dan mungkin terdapat korelasi antara ciri-ciri pakar yang berbeza. Dalam kes ini, vektor ciri yang dipilih mungkin mempunyai pertindihan dan konflik untuk produk titik antara setiap pakar yang terlibat dalam pengiraan, yang seterusnya menjejaskan ketepatan keputusan. Oleh itu, struktur KPM memerlukan algoritma penghalaan yang lebih tepat untuk memilih pakar terbaik, dan pemilihan perlu dipertimbangkan
2.2 Kaedah kertas
2.2.1 Seni bina model
2.2 Berdasarkan Yuan Struktur model 2B, Yuan 2.0 memperkenalkan perhatian berasaskan penapisan tempatan (LFA) untuk mempertimbangkan pergantungan tempatan token input, dengan itu meningkatkan ketepatan model. Dalam Yuan 2.0-M32, rangkaian suapan ke hadapan (FFN) padat setiap lapisan digantikan dengan komponen KPM.
Rajah 1 menunjukkan seni bina lapisan KPM yang digunakan dalam model kertas. Mengambil empat FFN sebagai contoh (sebenarnya terdapat 32 pakar), setiap lapisan KPM terdiri daripada FFN bebas sebagai pakar. Memandangkan rangkaian laluan pakar memberikan token input kepada pakar yang berkaitan, rangkaian laluan klasik menetapkan vektor ciri untuk setiap pakar. Dan kirakan produk titik antara token input dan setiap vektor ciri pakar untuk mendapatkan persamaan antara token dan setiap pakar. Pakar yang mempunyai persamaan tertinggi akan digunakan untuk mengira output. Pakar yang mempunyai persamaan paling kuat dipilih untuk pengaktifan dan mengambil bahagian dalam pengiraan seterusnya.
Gambar 1 Rajah 1: penerangan tentang Yuan 2.0-M32. Gambar di sebelah kiri menunjukkan pengembangan lapisan MoE dalam seni bina Yuan 2.0. Lapisan MoE menggantikan lapisan suapan hadapan dalam Yuan 2.0. Rajah di sebelah kanan menunjukkan struktur lapisan MoE. Dalam model kertas kerja, setiap token input akan diberikan kepada 2 daripada jumlah 32 pakar, dan dalam rajah kertas menggunakan 4 pakar sebagai contoh. Output KPM ialah jumlah wajaran pakar terpilih. N mewakili bilangan lapisan. Vektor ciri setiap pakar adalah bebas antara satu sama lain, dan korelasi antara pakar diabaikan semasa mengira kebarangkalian. Malah, dalam kebanyakan model KPM, dua atau lebih pakar biasanya dipilih untuk mengambil bahagian dalam pengiraan seterusnya, yang secara semula jadi menghasilkan korelasi yang kuat antara pakar. Mengambil kira korelasi antara pakar pastinya membantu meningkatkan ketepatan.
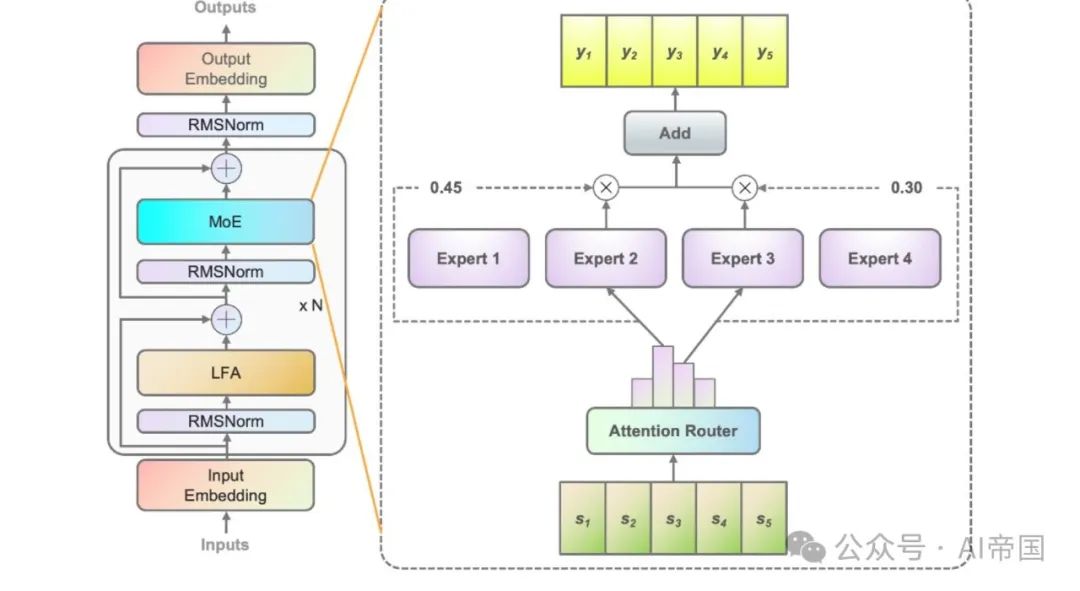 Rajah 2(b) menunjukkan seni bina penghala perhatian yang dicadangkan dalam kerja ini rangkaian penghalaan novel ini menyepadukan korelasi antara pakar dengan menggunakan mekanisme perhatian. Matriks pekali yang mewakili korelasi antara pakar dibina dan digunakan dalam pengiraan nilai kebarangkalian akhir.
Rajah 2(b) menunjukkan seni bina penghala perhatian yang dicadangkan dalam kerja ini rangkaian penghalaan novel ini menyepadukan korelasi antara pakar dengan menggunakan mekanisme perhatian. Matriks pekali yang mewakili korelasi antara pakar dibina dan digunakan dalam pengiraan nilai kebarangkalian akhir.
 Jadual 1: Perbandingan struktur penghalaan yang berbeza
Jadual 1: Perbandingan struktur penghalaan yang berbeza
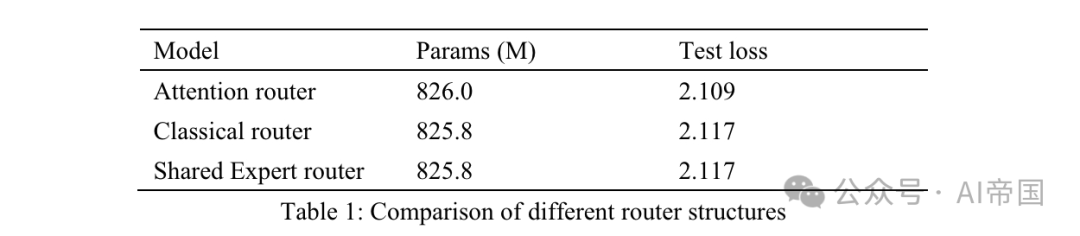
Jadual 1 menyenaraikan keputusan ketepatan penghala yang berbeza. Model kertas itu menguji penghala perhatian pada 8 pakar yang boleh dilatih. Model penghala klasik mempunyai 8 pakar yang boleh dilatih untuk memastikan skala parameter yang sama, dan struktur penghalaan adalah sama seperti yang digunakan pada Mixtral 8*7B, iaitu Softmax pada satu lapisan linear. Penghala pakar kongsi menggunakan strategi pengasingan pakar kongsi dan seni bina penghalaan klasik. Terdapat dua pakar tetap yang menguasai pengetahuan am, dan dua yang pertama daripada 14 pakar pilihan sebagai pakar khusus.
Keluaran KPM ialah gabungan pakar tetap dan pakar yang dipilih oleh penghala. Ketiga-tiga model menggunakan 30Btoken untuk latihan dan 10Btoken lagi untuk ujian. Mempertimbangkan keputusan antara penghala klasik dan penghala pakar yang dikongsi, kertas itu mendapati bahawa penghala tersebut mencapai kerugian ujian yang sama dengan peningkatan 7.35% dalam masa latihan. Kecekapan pengiraan pakar kongsi adalah agak rendah dan tidak membawa kepada ketepatan latihan yang lebih baik daripada strategi KPM klasik. Oleh itu, dalam model kertas kerja, kertas itu menggunakan strategi penghalaan klasik tanpa pakar yang dikongsi bersama. Berbanding dengan rangkaian laluan klasik, kehilangan ujian penghala perhatian meningkat sebanyak 3.8%.
 Kertas menguji kebolehskalaan model dengan menambah bilangan pakar dan menetapkan saiz parameter setiap pakar. Menambah bilangan pakar latihan hanya mengubah kapasiti model, bukan parameter model yang diaktifkan sebenar. Semua model dilatih dengan 50 bilion token dan diuji dengan tambahan 10 bilion token. Kertas itu menetapkan pakar yang diaktifkan kepada 2, dan hiperparameter latihan bagi ketiga-tiga model adalah sama. Kesan penskalaan pakar diukur dengan kehilangan ujian selepas melatih 50 bilion token (Jadual 2). Berbanding model dengan 8 pakar yang boleh dilatih, model dengan 16 pakar menunjukkan pengurangan kerugian sebanyak 2%, manakala model dengan 32 pakar menunjukkan pengurangan kerugian sebanyak 3.6%. Memandangkan ketepatannya, kertas itu memilih 32 pakar untuk Yuan 2.0-M32.
Kertas menguji kebolehskalaan model dengan menambah bilangan pakar dan menetapkan saiz parameter setiap pakar. Menambah bilangan pakar latihan hanya mengubah kapasiti model, bukan parameter model yang diaktifkan sebenar. Semua model dilatih dengan 50 bilion token dan diuji dengan tambahan 10 bilion token. Kertas itu menetapkan pakar yang diaktifkan kepada 2, dan hiperparameter latihan bagi ketiga-tiga model adalah sama. Kesan penskalaan pakar diukur dengan kehilangan ujian selepas melatih 50 bilion token (Jadual 2). Berbanding model dengan 8 pakar yang boleh dilatih, model dengan 16 pakar menunjukkan pengurangan kerugian sebanyak 2%, manakala model dengan 32 pakar menunjukkan pengurangan kerugian sebanyak 3.6%. Memandangkan ketepatannya, kertas itu memilih 32 pakar untuk Yuan 2.0-M32.
Table 2: Hasil eksperimen yang dilanjutkan
2.2.2 Latihan Model
Yuan 2.0-M32 dilatih melalui gabungan paralelisme data dan paralelisme saluran paip, tetapi tidak menggunakan paralelisme tensor atau paralelisme pengoptimuman. Rajah 3 menunjukkan keluk kerugian, dan kerugian latihan terakhir ialah 1.22.
Semasa proses penalaan halus, kertas itu memanjangkan panjang jujukan kepada 16384. Berikutan kerja CodeLLama (Roziere et al., 2023), kertas itu menetapkan semula nilai kekerapan asas pembenaman kedudukan diputar (RoPE) untuk mengelakkan pengecilan skor perhatian apabila panjang jujukan meningkat. Daripada hanya meningkatkan nilai asas daripada 1000 kepada nilai yang sangat besar (mis. 1000000), kertas itu menggunakan kesedaran NTK (bloc97, 2023) untuk mengira nilai asas baharu.
Kertas ini juga membandingkan prestasi model Yuan 2.0-M32 yang telah dilatih dengan asas baharu dalam gaya persepsi NTK, dan dengan asas lain dalam tugas mendapatkan jarum dengan panjang jujukan sehingga 16K. Kertas kerja mendapati bahawa nilai asas baharu 40890 untuk gaya persepsi NTK menunjukkan prestasi yang lebih baik. Oleh itu, 40890 digunakan semasa penalaan halus.
2.2.4 Set data pra-latihan
Yuan 2.0-M32 pra-latihan dari awal menggunakan set data dwibahasa yang mengandungi token 2000B. Data mentah pra-latihan mengandungi lebih 3400B token, dan berat setiap kategori diselaraskan berdasarkan kualiti dan kuantiti data.
Korpus pra-latihan komprehensif terdiri daripada:
44 sub-set data yang meliputi data rangkak web, Wikipedia, kertas akademik, buku, kod, matematik dan formula serta kepakaran khusus domain. Sebahagian daripadanya ialah set data sumber terbuka dan selebihnya dicipta oleh Yuan 2.0.
Sesetengah data perangkak web biasa, buku Cina, perbualan dan data berita Cina diwarisi daripada Yuan 1.0 (Wu et al., 2021). Kebanyakan data pra-latihan dalam Yuan 2.0 juga telah digunakan semula.
Butiran tentang pembinaan dan sumber setiap set data adalah seperti berikut:
Web (25.2%): Data perangkak tapak web diperoleh daripada set data sumber terbuka dan perangkak awam yang diproses daripada data kerja sebelumnya (Yuan 1.0) kertas dikumpul. Untuk butiran lanjut tentang Sistem Penapisan Data Besar-besaran (MDFS) untuk mengekstrak kandungan berkualiti tinggi daripada konteks web, sila rujuk Yuan 1.0.
Ensiklopedia (1.2%), kertas kerja (0.84%), buku (6.49%) dan terjemahan (1.1%): Data diwarisi daripada set data Yuan 1.0 dan Yuan 2.0.
Kod (47.5%): Set data kod diperluaskan dengan hebat berbanding Yuan 2.0. Kertas itu menggunakan kod daripada Stack v2 (Lozhkov et al., 2024). Komen dalam Stack v2 diterjemahkan ke dalam bahasa Cina. Data sintesis kod dijana melalui pendekatan yang serupa dengan Yuan 2.0.
Matematik (6.36%): Semua data matematik daripada Yuan 2.0 telah digunakan semula. Data ini terutamanya datang daripada set data sumber terbuka, termasuk proof-pile vl (Azerbayev, 2022) dan v2 (Paster et al., 2023), AMPS (Hendrycks et al., 2021), MathPile (Wang, Xia, dan Liu, 2023 ) dan StackMathQA (Zhang, 2024). Mencipta set data sintetik untuk pengiraan berangka menggunakan Python untuk memudahkan empat operasi aritmetik.
Domain khusus (1.93%): Ini ialah set data yang mengandungi pengetahuan latar belakang yang berbeza.
2.2.5 Set data penalaan halus
Set data penalaan halus dilanjutkan berdasarkan set data yang digunakan dalam Yuan 2.0.
Set data arahan kod. Semua data pengaturcaraan dengan arahan bahasa Cina dan beberapa dengan ulasan bahasa Inggeris dijana oleh model bahasa besar (LLM). Kira-kira 30% daripada data arahan kod adalah dalam bahasa Inggeris, dan selebihnya dalam bahasa Cina. Data sintetik meniru kod Python dengan anotasi Cina dalam penjanaan segera dan strategi pembersihan data.
Kod Python dengan ulasan bahasa Inggeris yang dikumpulkan daripada Magicoder-Evol-Instruct-110K dan CodeFeedback-Filtered-Instruction. Ekstrak data arahan dengan teg bahasa (seperti "python") daripada set data.
Kod dalam bahasa lain seperti C/C++/Go/Java/SQL/Shell, dengan ulasan bahasa Inggeris, berasal daripada set data sumber terbuka dan diproses dengan cara yang serupa dengan kod Python. Strategi pembersihan adalah serupa dengan kaedah dalam Yuan 2.0. Kotak pasir direka bentuk untuk mengekstrak baris yang boleh disusun dan boleh laku daripada kod yang dijana dan mengekalkan baris yang lulus sekurang-kurangnya satu ujian unit.
Set data arahan matematik. Set data arahan matematik semuanya diwarisi daripada set data penalaan halus dalam Yuan 2.0. Untuk meningkatkan keupayaan model untuk menyelesaikan masalah matematik melalui kaedah pengaturcaraan, kertas itu membina data matematik yang didorong oleh Thoughts (PoT). PoT menukar masalah matematik kepada tugas penjanaan kod yang melakukan pengiraan dalam Python.
Set Data Arahan Keselamatan. Selain set data sembang Yuan 2.0, kertas kerja itu juga membina set data penjajaran keselamatan dwibahasa berdasarkan set data penjajaran keselamatan sumber terbuka. Kertas kerja itu hanya mengeluarkan soalan daripada set data awam, meningkatkan kepelbagaian soalan dan menggunakan model bahasa yang besar untuk menjana semula jawapan bahasa Cina dan Inggeris.
2.2.6 Tokenizer
Untuk Yuan 2.0-M32, tokenizer Inggeris dan Cina diwarisi daripada tokenizer yang digunakan dalam Yuan 2.0. . dan dinilai pada MMLU sebagai penanda aras yang komprehensif.
2.3.1 Penjanaan Kod
Keupayaan penjanaan kod dinilai menggunakan penanda aras HumanEval. Kaedah dan petua penilaian adalah serupa dengan yang dinyatakan dalam Meta 2.0.
Jadual 3: Perbandingan antara Yuan 2.0-M32 dan model lain pada pas HumanEval @1
Model dijangka akan melengkapkan fungsi selepas. Fungsi yang dihasilkan akan dinilai melalui ujian unit. Jadual 3 menunjukkan keputusan Yuan 2.0-M32 dalam pembelajaran sifar pukulan dan membandingkannya dengan model lain. Keputusan Yuan 2.0-M32 adalah kedua selepas DeepseekV2 dan Llama3-70B, dan jauh melebihi model lain, walaupun parameter aktif dan penggunaan pengiraannya jauh lebih rendah daripada model lain.
Berbanding dengan DeepseekV2, model kertas menggunakan kurang daripada satu perempat daripada parameter aktif dan memerlukan kurang daripada satu perlima pengiraan setiap token, sambil mencapai tahap ketepatannya lebih daripada 90%. Berbanding dengan Llama3-70B, jurang antara parameter model dan jumlah pengiraan adalah lebih besar, tetapi kertas masih boleh mencapai 91% tahapnya. Yuan 2.0-M32 menunjukkan keupayaan pengaturcaraan yang kukuh, lulus tiga daripada empat soalan. Yuan 2.0-M32 cemerlang dalam pembelajaran sampel kecil, meningkatkan ketepatan HumanEval kepada 78.0 dalam 14 percubaan.
2.3.2 Matematik
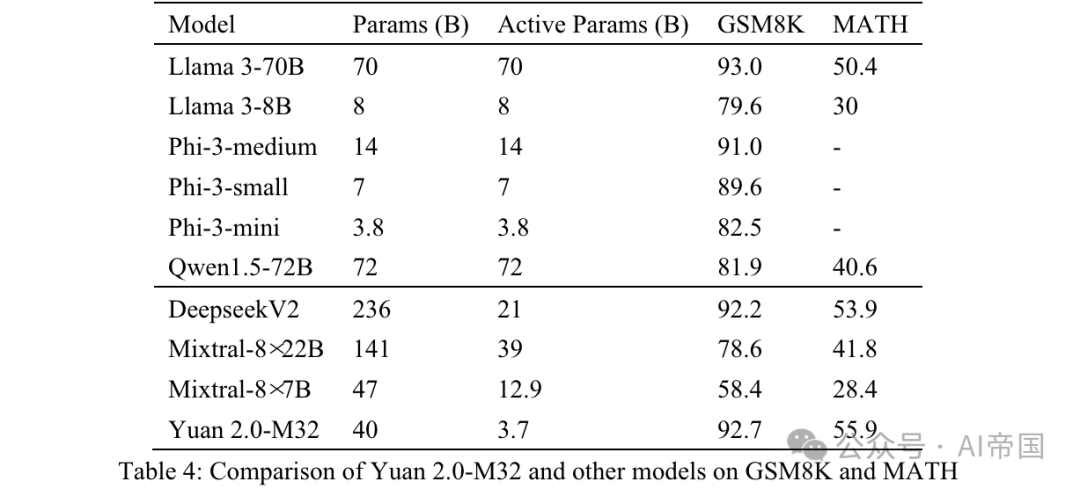
Keupayaan matematik Yuan 2.0-M32 dinilai melalui penanda aras GSM8K dan MATH. Gesaan dan strategi ujian untuk GSM8K adalah serupa dengan yang digunakan pada Yuan 2.0, dengan satu-satunya perbezaan ialah kertas itu menggunakan 8 percubaan (Jadual 4).
 Jadual 4: Perbandingan Yuan 2.0-M32 dengan model lain pada GSM8K dan MATH
Jadual 4: Perbandingan Yuan 2.0-M32 dengan model lain pada GSM8K dan MATH
MATH ialah set data yang mengandungi 12,500 soalan dan jawapan pertandingan matematik yang mencabar. Setiap soalan dalam set data ini mempunyai penyelesaian langkah demi langkah yang lengkap, membimbing model untuk menjana derivasi jawapan dan penjelasan. Jawapan kepada soalan boleh menjadi nilai berangka, atau ungkapan matematik (seperti y=2x+5, x-+2x-1, 2a+b, dsb.). Yuan 2.0-M32 menggunakan kaedah Chain of Thinking (CoT) untuk menjana jawapan akhir melalui 4 percubaan. Jawapan akan diekstrak daripada analisis dan ditukar kepada format bersatu.
Untuk keputusan berangka, output yang setara secara matematik dalam semua format diterima. Sebagai contoh, pecahan 1/2, 12, 0.5, 0.50 semuanya ditukar kepada 0.5 dan dianggap sebagai hasil yang sama. Untuk ungkapan matematik, kertas itu membuang simbol tab dan ruang dan menyatukan ungkapan biasa untuk irama atau nota muzik. 55 '5' semuanya diterima sebagai jawapan yang sama. Keputusan akhir selepas pemprosesan dibandingkan dengan jawapan standard dan dinilai menggunakan skor EM (Exact Match).
Seperti yang dapat dilihat daripada keputusan yang ditunjukkan dalam Jadual 4, Yuan 2.0-M32 mempunyai markah tertinggi pada penanda aras MATH. Berbanding dengan Mixtral-8x7B, parameter aktif yang terakhir adalah 3.48 kali ganda daripada Yuan 2.0-M32, tetapi skor Yuan hampir dua kali ganda. Pada GSM8K, skor Yuan 2.0-M32 juga sangat hampir dengan Llama 3-70B dan lebih baik daripada model lain.
2.3.3MMLU
Pemahaman bahasa berbilang tugas berskala besar (MMLU) merangkumi 57 disiplin seperti STEM, kemanusiaan dan sains sosial, bermula daripada tugas bahasa asas hingga tugas penaakulan logik lanjutan. Semua soalan dalam MMLU ialah soalan QA aneka pilihan dalam bahasa Inggeris. Model ini dijangka menjana pilihan yang betul atau analisis yang sepadan.
Organisasi data input Yuan 2.0-M32 ditunjukkan dalam Lampiran B. Teks sebelumnya dihantar kepada model dan semua jawapan yang berkaitan dengan jawapan yang betul atau label pilihan dianggap betul.
Ketepatan akhir diukur dengan MC1 (Jadual 5). Keputusan pada MMLU menunjukkan keupayaan model kertas dalam bidang yang berbeza. Yuan 2.0-M32 melebihi prestasi Mixtral-8x7B, Phi-3-mini dan Llama 3-8B.
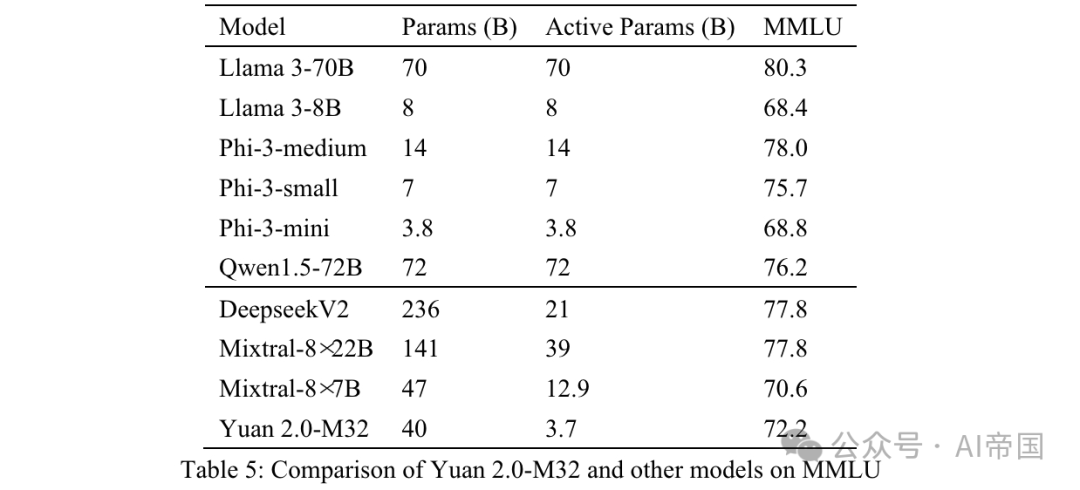 Jadual 5: Perbandingan Yuan 2.0-M32 dengan model lain pada MMLU
Jadual 5: Perbandingan Yuan 2.0-M32 dengan model lain pada MMLU
2.3.4 ARC
Cabaran Penanda Aras Berbilang Inferens AI2 (ARC) yang mengandungi data pilihan (ARC) Soalan daripada ujian sains untuk darjah 9 hingga 9. Ia dibahagikan kepada dua bahagian, Mudah dan Cabaran, dengan bahagian yang kedua mengandungi bahagian yang lebih kompleks yang memerlukan penaakulan lanjut. Kertas kerja menguji model kertas dalam bahagian cabaran.
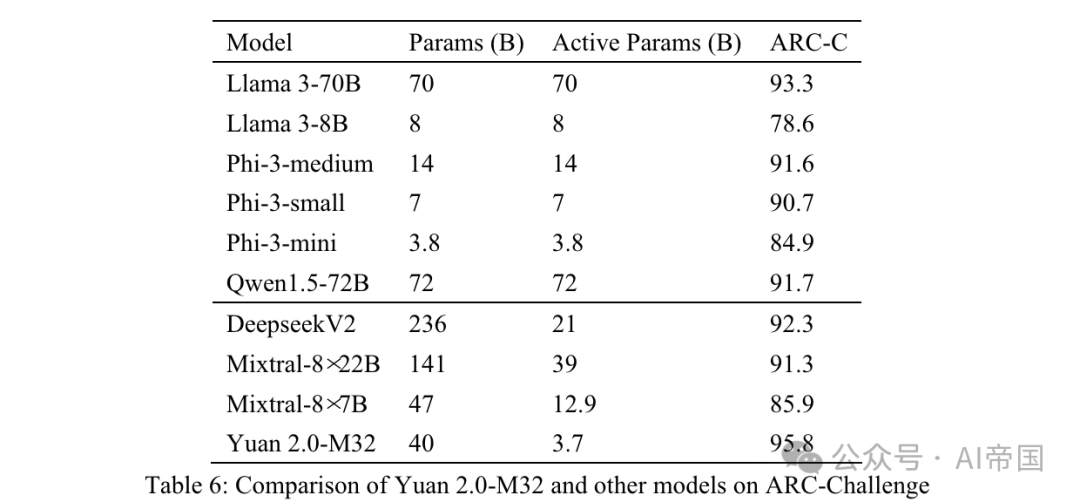 Jadual 6: Perbandingan Yuan 2.0-M32 dan model lain pada ARC-Challenge
Jadual 6: Perbandingan Yuan 2.0-M32 dan model lain pada ARC-Challenge
Soalan dan pilihan disambungkan secara terus dan dipisahkan oleh . Teks sebelumnya dihantar ke model, yang dijangka menjana label atau jawapan yang sepadan. Jawapan yang dihasilkan dibandingkan dengan jawapan sebenar dan keputusan dikira menggunakan sasaran MC1.
Jadual 6 menunjukkan keputusan untuk ARC-C menunjukkan bahawa Yuan 2.0-M32 cemerlang dalam menyelesaikan masalah saintifik yang kompleks - ia mengatasi prestasi Llama3-70B pada penanda aras ini.
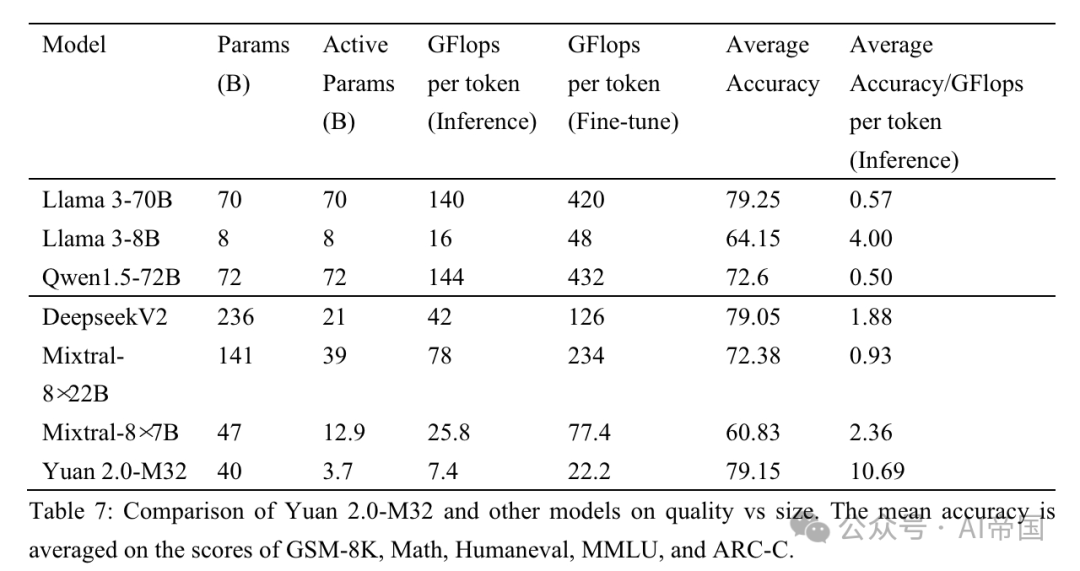 Gambar
Gambar
Jadual 7: Perbandingan kualiti dan saiz antara Yuan 2.0-M32 dan model lain. Purata ketepatan dipuratakan berdasarkan markah daripada GSM-8K, Math, Humaneval, MMLU dan ARC-C
Kertas kerja membandingkan prestasi kertas kerja dengan tiga model MoE (Keluarga Mixtral, Deepseek) dan enam model padat (Qwen (Bai et al., 2023), keluarga Llama dan keluarga Phi-3 (Abdin et al., 2024 )) untuk Menilai prestasi Yuan 2.0-M32 dalam bidang yang berbeza. Jadual 7 menunjukkan perbandingan antara ketepatan dan usaha pengiraan antara Yuan 2.0-M32 dan model lain. Yuan 2.0-M32 diperhalusi menggunakan hanya parameter aktif 3.7B dan 22.2 GFlop setiap token, yang merupakan yang paling menjimatkan untuk mendapatkan hasil yang setanding atau bahkan mengatasi model lain yang disenaraikan dalam jadual. Jadual 7 membayangkan kecekapan pengiraan yang sangat baik dan prestasi model kertas semasa proses inferens. Yuan 2.0-M32 mempunyai ketepatan purata 79.15, yang setanding dengan Llama3-70B. Purata ketepatan/GFlop setiap nilai token ialah 10.69, iaitu 18.9 kali ganda Llama3-70B.
Tajuk kertas: Yuan 2.0-M32: Campuran Pakar dengan Penghala Perhatian
Pautan kertas: https://www.php.cn/link/cc7d159f399ff38f9d159d399ff
Atas ialah kandungan terperinci LLM |. Yuan 2.0-M32: Model Campuran Pakar dengan Penghalaan Perhatian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Caltech Cina menggunakan AI untuk menumbangkan bukti matematik! Mempercepatkan 5 kali terkejut Tao Zhexuan, 80% langkah matematik adalah automatik sepenuhnya
Apr 23, 2024 pm 03:01 PM
Caltech Cina menggunakan AI untuk menumbangkan bukti matematik! Mempercepatkan 5 kali terkejut Tao Zhexuan, 80% langkah matematik adalah automatik sepenuhnya
Apr 23, 2024 pm 03:01 PM
LeanCopilot, alat matematik formal yang telah dipuji oleh ramai ahli matematik seperti Terence Tao, telah berkembang semula? Sebentar tadi, profesor Caltech Anima Anandkumar mengumumkan bahawa pasukan itu mengeluarkan versi diperluaskan kertas LeanCopilot dan mengemas kini pangkalan kod. Alamat kertas imej: https://arxiv.org/pdf/2404.12534.pdf Percubaan terkini menunjukkan bahawa alat Copilot ini boleh mengautomasikan lebih daripada 80% langkah pembuktian matematik! Rekod ini adalah 2.3 kali lebih baik daripada aesop garis dasar sebelumnya. Dan, seperti sebelum ini, ia adalah sumber terbuka di bawah lesen MIT. Dalam gambar, dia ialah Song Peiyang, seorang budak Cina
 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Daripada 'manusia + RPA' kepada 'manusia + generatif AI + RPA', bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA?
Jun 05, 2023 pm 12:30 PM
Daripada 'manusia + RPA' kepada 'manusia + generatif AI + RPA', bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA?
Jun 05, 2023 pm 12:30 PM
Sumber imej@visualchinesewen|Wang Jiwei Daripada "manusia + RPA" kepada "manusia + generatif AI + RPA", bagaimanakah LLM mempengaruhi interaksi manusia-komputer RPA? Dari perspektif lain, bagaimanakah LLM mempengaruhi RPA dari perspektif interaksi manusia-komputer? RPA, yang menjejaskan interaksi manusia-komputer dalam pembangunan program dan automasi proses, kini akan turut diubah oleh LLM? Bagaimanakah LLM mempengaruhi interaksi manusia-komputer? Bagaimanakah AI generatif mengubah interaksi manusia-komputer RPA? Ketahui lebih lanjut mengenainya dalam satu artikel: Era model besar akan datang, dan AI generatif berdasarkan LLM sedang mengubah interaksi manusia-komputer RPA dengan pantas mentakrifkan semula interaksi manusia-komputer, dan LLM mempengaruhi perubahan dalam seni bina perisian RPA. Jika anda bertanya apakah sumbangan RPA kepada pembangunan program dan automasi, salah satu jawapannya ialah ia telah mengubah interaksi manusia-komputer (HCI, h
 Plaud melancarkan perakam boleh pakai NotePin AI untuk $169
Aug 29, 2024 pm 02:37 PM
Plaud melancarkan perakam boleh pakai NotePin AI untuk $169
Aug 29, 2024 pm 02:37 PM
Plaud, syarikat di belakang Perakam Suara AI Plaud Note (tersedia di Amazon dengan harga $159), telah mengumumkan produk baharu. Digelar NotePin, peranti ini digambarkan sebagai kapsul memori AI, dan seperti Pin AI Humane, ini boleh dipakai. NotePin ialah
 GraphRAG dipertingkatkan untuk mendapatkan semula graf pengetahuan (dilaksanakan berdasarkan kod Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG dipertingkatkan untuk mendapatkan semula graf pengetahuan (dilaksanakan berdasarkan kod Neo4j)
Jun 12, 2024 am 10:32 AM
Penjanaan Dipertingkatkan Pengambilan Graf (GraphRAG) secara beransur-ansur menjadi popular dan telah menjadi pelengkap hebat kepada kaedah carian vektor tradisional. Kaedah ini mengambil kesempatan daripada ciri-ciri struktur pangkalan data graf untuk menyusun data dalam bentuk nod dan perhubungan, dengan itu mempertingkatkan kedalaman dan perkaitan kontekstual bagi maklumat yang diambil. Graf mempunyai kelebihan semula jadi dalam mewakili dan menyimpan maklumat yang pelbagai dan saling berkaitan, dan dengan mudah boleh menangkap hubungan dan sifat yang kompleks antara jenis data yang berbeza. Pangkalan data vektor tidak dapat mengendalikan jenis maklumat berstruktur ini dan ia lebih menumpukan pada pemprosesan data tidak berstruktur yang diwakili oleh vektor berdimensi tinggi. Dalam aplikasi RAG, menggabungkan data graf berstruktur dan carian vektor teks tidak berstruktur membolehkan kami menikmati kelebihan kedua-duanya pada masa yang sama, iaitu perkara yang akan dibincangkan oleh artikel ini. struktur
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Memandangkan prestasi model bahasa berskala besar sumber terbuka terus bertambah baik, prestasi dalam penulisan dan analisis kod, pengesyoran, ringkasan teks dan pasangan menjawab soalan (QA) semuanya bertambah baik. Tetapi apabila ia berkaitan dengan QA, LLM sering gagal dalam isu yang berkaitan dengan data yang tidak terlatih, dan banyak dokumen dalaman disimpan dalam syarikat untuk memastikan pematuhan, rahsia perdagangan atau privasi. Apabila dokumen ini disoal, LLM boleh berhalusinasi dan menghasilkan kandungan yang tidak relevan, rekaan atau tidak konsisten. Satu teknik yang mungkin untuk menangani cabaran ini ialah Retrieval Augmented Generation (RAG). Ia melibatkan proses meningkatkan respons dengan merujuk pangkalan pengetahuan berwibawa di luar sumber data latihan untuk meningkatkan kualiti dan ketepatan penjanaan. Sistem RAG termasuk sistem mendapatkan semula untuk mendapatkan serpihan dokumen yang berkaitan daripada korpus
 Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
Jul 01, 2024 am 07:22 AM
Google AI mengumumkan Gemini 1.5 Pro dan Gemma 2 untuk pembangun
Jul 01, 2024 am 07:22 AM
Google AI telah mula menyediakan pembangun akses kepada tetingkap konteks lanjutan dan ciri penjimatan kos, bermula dengan model bahasa besar (LLM) Gemini 1.5 Pro. Sebelum ini tersedia melalui senarai tunggu, penuh 2 juta token konteks windo
