Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
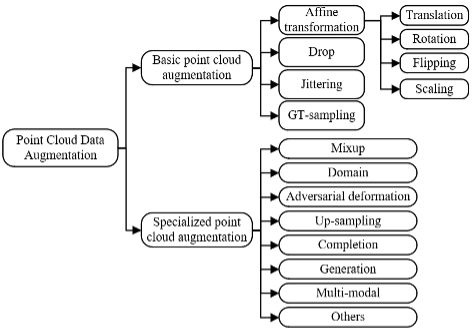
Pengarang pertama kertas kerja ini, Zhu Qinfeng, ialah calon kedoktoran tahun pertama yang dilatih bersama oleh Universiti Xi'an Jiaotong-Liverpool Universiti Liverpool, dan penyelianya ialah Profesor Madya Fan Lei. Arah penyelidikan utama beliau ialah segmentasi semantik, gabungan maklumat pelbagai mod, penglihatan 3D, imej hiperspektral dan peningkatan data. Kumpulan penyelidikan ini merekrut pelajar kedoktoran 24/25 peringkat pertanyaan e-mel dialu-alukan. E-mel: qinfeng.zhu21@student.xjtlu.edu.cnLaman utama: https://zhuqinfeng1999.github.io/ artikel teratas bagi jurnal dalam bidang pengecaman corak Kertas ulasan terkini Pengiktirafan 2024: Tafsiran "Kemajuan dalam Pembesaran Data Awan Titik untuk Pembelajaran Mendalam: Satu Tinjauan". Kertas kerja ini telah disiapkan oleh Zhu Qinfeng, Fan Lei dan Weng Ningxin dari Universiti Xi'an Jiaotong-Liverpool. Semakan ini secara menyeluruh meringkaskan peningkatan data awan titik kerja penyelidikan berkaitan buat kali pertama. Pembelajaran mendalam telah menjadi salah satu kaedah arus perdana dan berkesan untuk tugasan analisis awan titik seperti pengesanan, pembahagian dan pengelasan. Untuk mengurangkan pemasangan berlebihan semasa melatih model pembelajaran mendalam, dan terutamanya untuk meningkatkan prestasi model apabila jumlah atau kepelbagaian data latihan adalah terhad, penambahan data selalunya penting. Walaupun pelbagai kaedah penambahan data awan titik telah digunakan secara meluas dalam tugas pemprosesan awan titik yang berbeza, tiada semakan atau perbincangan sistematik mengenai kaedah ini telah diterbitkan lagi. Oleh itu, kertas kerja ini menyiasat kaedah ini dan mengklasifikasikannya ke dalam rangka kerja klasifikasi yang merangkumi kaedah penambahan data awan titik asas dan khusus. Melalui penilaian menyeluruh terhadap kaedah penambahbaikan ini, kertas kerja ini mengenal pasti potensi dan batasannya, menyediakan rujukan berguna untuk memilih kaedah peningkatan yang sesuai. Selain itu, artikel ini meneroka potensi arah untuk penyelidikan masa depan. Tinjauan ini membantu memberikan gambaran menyeluruh tentang penyelidikan semasa tentang penambahan data awan titik dan mempromosikan aplikasi dan pembangunannya yang lebih luas. Akses Percuma: https://authors.elsevier.com/c/1j3TW77nKoLGMarXiv: https://arxiv.org/pdf/2308.12113Laman utama pengarang: https://19zhuqinfeng. Rajah 1. Klasifikasi kaedah peningkatan data awan titik. Point Cloud Data AugmentationDalam bidang deep learning, data augmentation sering digunakan apabila set data latihan yang ada adalah terhad. Ini melibatkan melaksanakan satu siri operasi tertentu untuk mengubah suai atau melanjutkan data asal, dengan itu meningkatkan saiz dan kepelbagaian set data.
Pembesaran data hampir selalu dianggap ideal apabila melatih rangkaian pembelajaran mendalam memandangkan set data ditambah kualiti yang baik membantu meningkatkan keteguhan rangkaian, meningkatkan keupayaan generalisasi dan mengurangkan pemasangan berlebihan . Perkembangan menyeluruh telah diperhatikan dalam bidang peningkatan data imej dan peningkatan data teks.
Dalam banyak kertas penyelidikan yang diterbitkan baru-baru ini mengenai tugas pemprosesan awan titik, penyelidik telah meneroka pelbagai kaedah untuk meningkatkan data awan titik. Pelbagai kaedah ini menimbulkan cabaran kepada penyelidik dalam memilih kaedah yang sesuai. Oleh itu, adalah sangat bernilai untuk menyiasat kaedah ini secara sistematik dan mengklasifikasikannya ke dalam kumpulan yang berbeza.
Kertas kerja ini membentangkan tinjauan komprehensif tentang kaedah penambahan data awan titik.
Berdasarkan tinjauan kami, kami mencadangkan sistem klasifikasi kaedah peningkatan ini, seperti yang ditunjukkan dalam Rajah 1.
Kaedah peningkatan boleh dibahagikan kepada dua kategori utama: peningkatan awan titik asas dan peningkatan awan titik khusus, yang serupa dengan kaedah pengelasan tipikal peningkatan imej.. Peningkatan awan titik khusus merujuk kepada kaedah yang biasanya dibangunkan untuk menyelesaikan cabaran tertentu atau bertindak balas terhadap persekitaran aplikasi tertentu. Dalam kebanyakan kes, peningkatan awan titik tertentu secara pengiraan lebih kompleks daripada peningkatan asas, bergantung pada butiran pelaksanaan kaedah peningkatan. Subkategori dalam sistem pengelasan yang dicadangkan kami mewakili ringkasan pelbagai kaedah yang telah digunakan untuk peningkatan data awan titik dalam literatur, atau berpotensi untuk digunakan untuk peningkatan data awan titik. Sumbangan utama ulasan ini adalah seperti berikut: Ini ialah semakan pertama untuk meninjau kaedah peningkatan data awan titik secara menyeluruh, meliputi kemajuan terkini dalam peningkatan data awan titik. Berdasarkan ciri-ciri operasi peningkatan, kami mencadangkan sistem klasifikasi kaedah peningkatan data awan titik. Kajian ini meringkaskan pelbagai kaedah penambahan data awan titik, membincangkan aplikasinya dalam tugas pemprosesan awan titik biasa seperti pengesanan, pembahagian dan pengelasan, serta menyediakan cadangan untuk penyelidikan masa depan yang berpotensi.
-
Peningkatan awan titik asas
Transformasi affine melibatkan transformasi ruang affine, yang mengekalkan kolineariti dan skala jarak. Dalam peningkatan data imej, kaedah transformasi affine yang biasa digunakan termasuk penskalaan, terjemahan, putaran, flipping dan ricih. Begitu juga, transformasi affine juga boleh digunakan untuk pembesaran data awan titik. Kaedah biasa termasuk terjemahan, putaran, flipping dan penskalaan, dan kaedah ini telah digunakan secara meluas untuk menjana data latihan baharu tambahan.
Operasi ini boleh digunakan pada keseluruhan set data awan titik atau pada kejadian terpilih dalam data awan titik menggunakan strategi tertentu (contoh merujuk kepada objek semantik seperti kenderaan yang ditunjukkan dalam Rajah 2(a) ), atau digunakan untuk bahagian tertentu daripada contoh yang dipilih.
Walau bagaimanapun, data yang dipertingkatkan oleh transformasi affine mungkin menghadapi masalah kehilangan maklumat atau semantik yang tidak munasabah. Operasi khusus dan perbincangan mengenai transformasi affine ini diperincikan dalam kertas.射 Rajah 2. Contoh untuk meningkatkan data awan titik melalui transformasi tiruan: (a) data awan titik asal, (b) kenderaan peralihan, (C) kenderaan berputar, (D) mengezum kenderaan, (e) Balikkan pemandangan. Buang peningkatan
merujuk kepada membuang beberapa titik data dalam data awan titik, seperti ditunjukkan dalam Rajah 3. Pemilihan titik penyingkiran ditentukan oleh strategi khusus. Titik yang dibuang boleh menjadi sebahagian daripada keseluruhan data awan titik atau titik yang dipilih secara rawak dalam tempat kejadian. Penambahan keciciran membantu model pembelajaran mendalam menjadi lebih teguh kepada data yang hilang atau tidak lengkap yang mewakili adegan tersumbat atau separa kelihatan.  Ia juga menghalang model pembelajaran mendalam daripada menjadi terlalu bergantung pada titik data tertentu dalam set data latihan. Walau bagaimanapun, kehilangan maklumat awan titik yang berlebihan atau kritikal boleh menyebabkan perwakilan tidak realistik objek dunia sebenar dalam data latihan dan menjejaskan latihan model pembelajaran mendalam. Pelbagai kaedah dan perbincangan berdasarkan peningkatan keciciran diperincikan dalam kertas kerja.弃 Rajah 3. Contoh pengukuhan peningkatan tetulang: (A) Data awan titik asal, (b) buang awan titik peningkatan secara rawak, (C) buang sebahagian awan titik peningkatan. Jitter merujuk kepada penggunaan gangguan kecil atau bunyi pada kedudukan satu titik dalam awan titik, seperti yang ditunjukkan dalam Rajah 4. Pelbagai kaedah dan perbincangan berdasarkan peningkatan jitter diperincikan dalam kertas kerja. 增 Rajah 4. Contoh peningkatan penilaian: (a) data awan titik asal, (b) data awan titik dipertingkatkan dengan jitter. Dalam set data awan titik peringkat tempat kejadian, seperti adegan pemanduan autonomi luar, kejadian berlabel biasanya terhad. Dalam kes ini, persampelan GT menjadi kaedah penambahan data yang mudah dan berkesan.
Ia juga menghalang model pembelajaran mendalam daripada menjadi terlalu bergantung pada titik data tertentu dalam set data latihan. Walau bagaimanapun, kehilangan maklumat awan titik yang berlebihan atau kritikal boleh menyebabkan perwakilan tidak realistik objek dunia sebenar dalam data latihan dan menjejaskan latihan model pembelajaran mendalam. Pelbagai kaedah dan perbincangan berdasarkan peningkatan keciciran diperincikan dalam kertas kerja.弃 Rajah 3. Contoh pengukuhan peningkatan tetulang: (A) Data awan titik asal, (b) buang awan titik peningkatan secara rawak, (C) buang sebahagian awan titik peningkatan. Jitter merujuk kepada penggunaan gangguan kecil atau bunyi pada kedudukan satu titik dalam awan titik, seperti yang ditunjukkan dalam Rajah 4. Pelbagai kaedah dan perbincangan berdasarkan peningkatan jitter diperincikan dalam kertas kerja. 增 Rajah 4. Contoh peningkatan penilaian: (a) data awan titik asal, (b) data awan titik dipertingkatkan dengan jitter. Dalam set data awan titik peringkat tempat kejadian, seperti adegan pemanduan autonomi luar, kejadian berlabel biasanya terhad. Dalam kes ini, persampelan GT menjadi kaedah penambahan data yang mudah dan berkesan.
GT-sampling merujuk kepada operasi menambahkan tika berlabel pada set data latihan Seperti yang ditunjukkan dalam Rajah 5, tika GT berlabel datang daripada set data latihan yang sama atau set data lain. Persampelan GT biasanya sesuai untuk set data awan titik peringkat pemandangan, manakala set data awan titik peringkat contoh seperti ShapeNet biasanya tidak dipertimbangkan. Pelbagai kaedah dan perbincangan berdasarkan peningkatan pensampelan GT diperincikan dalam kertas kerja.
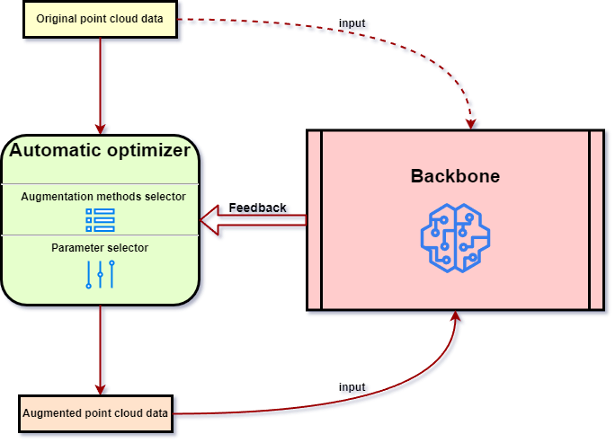
. (b) Persampelan GT yang tidak munasabah secara semantik, satu kereta berada di dalam dinding bangunan dan satu lagi berada di dalam pokok. Selain itu, artikel ini juga memperkenalkan strategi yang digunakan pada kaedah peningkatan data awan titik asas, seperti strategi berasaskan Patch dan strategi pengoptimuman automatik (lihat Rajah 6). Artikel ini meringkaskan kaedah peningkatan awan titik asas biasa, seperti yang ditunjukkan dalam Jadual 1. Rajah 6. Proses biasa pengoptimuman automatik.
Peningkatan awan titik khususKaedah peningkatan awan titik khusus biasanya direka untuk menyelesaikan cabaran atau senario aplikasi tertentu. Peningkatan awan titik khusus termasuk: Peningkatan campuran, peningkatan domain, peningkatan ubah bentuk lawan, peningkatan pensampelan, peningkatan penyiapan, peningkatan generatif, peningkatan multimodal dan lain-lain.
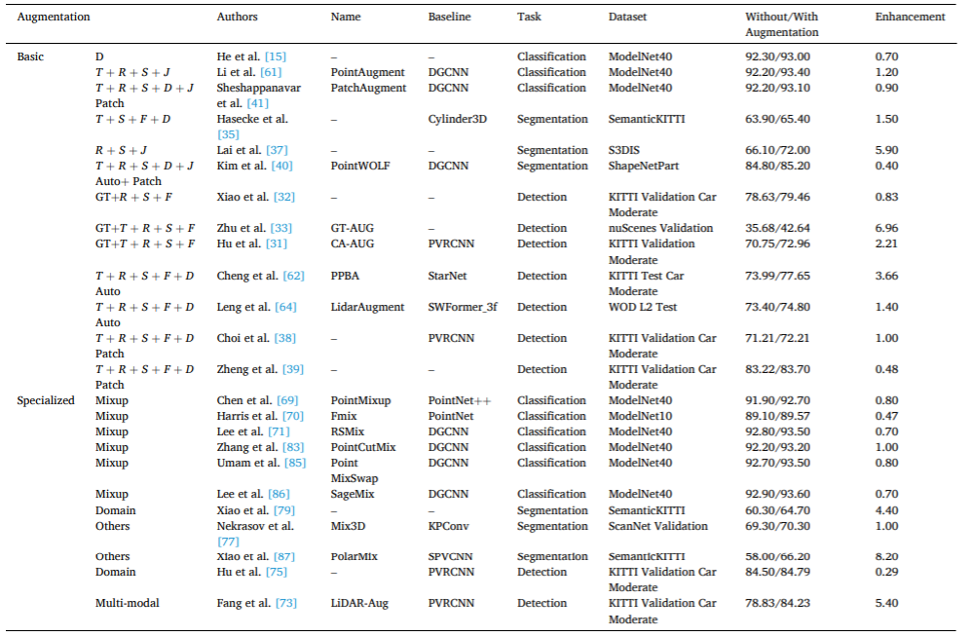
Takrifan khusus dan perbincangan kaedah peningkatan khusus ini diperincikan dalam teks. Jadual 2 memberikan gambaran keseluruhan pembangunan kaedah peningkatan khusus yang mewakili, menyediakan pelbagai maklumat. Jadual 2. Kaedah peningkatan awan titik khusus perwakilan. Perlu diambil perhatian bahawa beberapa teknologi ubah bentuk, pensampelan tinggi, penyiapan dan penjanaan lawan semasa tidak digunakan secara langsung untuk peningkatan data awan titik, seperti yang ditunjukkan dalam Jadual 3. Untuk menyediakan klasifikasi komprehensif kaedah khusus, kaedah berpotensi ini juga disertakan dan dibincangkan dalam artikel ini. Jadual 3. Kaedah peningkatan awan titik khusus yang berpotensi.
Tugas dan senario yang terpakai bagi kaedah peningkatan data awan titik dibincangkan secara terperinci dalam kertas kerja, dan peranan dalam pembelajaran awan pointency adalah peningkatan. seperti Seperti yang ditunjukkan dalam Rajah 7.
Figure 7. (a) Formation d'apprentissage en profondeur conventionnelle, envoi des données originales et des données améliorées au réseau d'apprentissage en profondeur pour la formation, et obtention du modèle formé, (b) Apprentissage de cohérence, en utilisant diverses méthodes d'amélioration pour modifier les points d'entrée ; Les données cloud sont transformées pour générer plusieurs variables augmentées, qui sont ensuite transmises à plusieurs réseaux pour un apprentissage cohérent, permettant ainsi d'effectuer des prédictions cohérentes pendant la formation. Le tableau 4 organise la littérature sur l'évaluation quantitative avant et après l'amélioration des données, montrant l'effet de l'amélioration des données. Dans le cadre de la comparaison de diverses méthodes d'augmentation, l'annexe (voir l'article pour plus de détails) fournit également un aperçu des performances quantitatives des tâches en aval utilisant des données de nuages de points augmentées, ainsi que les méthodes d'augmentation utilisées dans ces tâches.
Tableau 4. Rapport sur les résultats du point amélioration des données cloud sur des performances de modèle améliorées. L'équipe de recherche a identifié neuf directions possibles pour des recherches ultérieures dans ce domaine : déformation versariale, suréchantillonnage, complétion et génération pour l’augmentation des données. Compte tenu des progrès des GAN et des modèles de diffusion, ces modèles peuvent être utilisés pour générer des instances de nuages de points réalistes et diversifiées. Les recherches futures devraient évaluer ces méthodes sur des ensembles de données de référence sur des tâches spécifiques de traitement de nuages de points afin d'évaluer leur efficacité en tant que techniques d'augmentation. Actuellement, il existe peu d'études utilisant des réseaux de base et des ensembles de données cohérents pour évaluer les performances des méthodes d'augmentation des données de nuages de points pour différentes tâches de traitement de nuages de points. Une telle évaluation améliorera notre compréhension des performances des différentes méthodes d’augmentation. Par conséquent, les efforts de recherche futurs pourraient se concentrer sur l’établissement de nouvelles méthodes, mesures et/ou ensembles de données pour évaluer l’efficacité des méthodes d’augmentation des données de nuages de points et leur impact sur les performances des modèles d’apprentissage profond.
Certaines méthodes d'augmentation spécifiques peuvent être coûteuses en termes de calcul lorsqu'elles sont appliquées à des ensembles de données de nuages de points à grande échelle. Les travaux futurs pourraient se concentrer sur le développement d’algorithmes efficaces qui concilient coût de calcul et efficacité accrue. De plus, certaines méthodes spécifiques d’amélioration des nuages de points sont relativement complexes et difficiles à reproduire. Il est recommandé de développer une approche plug-and-play pour promouvoir son adoption généralisée. Pour l'amélioration des données de nuages de points, il manque une combinaison universellement acceptée d'opérations d'amélioration de base. Par conséquent, des travaux futurs sont nécessaires pour établir un protocole standard permettant de sélectionner les opérations d’augmentation pour différents domaines d’application, tâches et/ou ensembles de données sans sacrifier l’efficacité de l’augmentation. -
Plusieurs variantes de nuages de points générées par l'augmentation affecteront l'efficacité de l'apprentissage de la cohérence. Actuellement, à notre connaissance, seules les méthodes de boosting de base sont utilisées dans l’apprentissage de la cohérence. L’exploration de méthodes spécifiques d’amélioration des nuages de points, telles que la déformation contradictoire et l’amélioration générative, constitue un moyen intéressant d’améliorer l’efficacité de l’apprentissage de la cohérence et est considérée comme une orientation de recherche future précieuse. -
Actuellement, il existe peu de recherches sur la combinaison de méthodes de base d'amélioration des nuages de points avec des méthodes spécifiques d'amélioration des nuages de points. Une telle combinaison a le potentiel d’augmenter encore la polyvalence de l’augmentation des données et mérite de futures recherches. -
L'augmentation doit simuler de manière réaliste les changements dans les données du nuage de points, tels que les changements dans la taille, la position, l'orientation, l'apparence et l'environnement de l'objet, pour garantir que les données simulées sont cohérentes avec les situations du monde réel et restent sémantiquement correct. Des recherches futures pourraient envisager de normaliser les différentes plages d’amélioration pour répondre à des scénarios d’application spécifiques. -
Certaines applications, telles que la détection d'objets, peuvent impliquer des objets dynamiques dans la scène. Les nuages de points capturés dans des environnements dynamiques peuvent nécessiter des stratégies d'augmentation spécifiques prenant en compte les changements temporels des objets. Par exemple, une trajectoire spécifique d'un objet en mouvement peut être conçue, ce qui peut être réalisé grâce à un ensemble d'opérations d'amélioration combinées, telles qu'une translation, une rotation et un rejet. -
ViT atteint également de solides performances dans les tâches de segmentation et de classification en combinant simplement des opérations de base. Il serait intéressant d’explorer les performances de la méthode améliorée lorsqu’elle est intégrée au ViT de pointe en tant que réseau fédérateur. -
-
-
- [1] Qinfeng Zhu, Lei Fan, Ningxin Weng, Advances in Point
Augmentation des données cloud pour une Apprentissage : une enquête, reconnaissance de formes (2024), doi :
https://doi.org/10.1016/j.patcog.2024.110532Atas ialah kandungan terperinci XJTLU dan Universiti Liverpool mencadangkan: semakan komprehensif pertama bagi peningkatan data awan titik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Peranti teknologi
Peranti teknologi




















 Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
Daripada RLHF kepada DPO kepada TDPO, algoritma penjajaran model besar sudah pun 'peringkat token'
Jun 24, 2024 pm 03:04 PM
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
 Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
Mendahului senarai jurutera perisian AI sumber terbuka, penyelesaian tanpa ejen UIUC dengan mudah menyelesaikan masalah pengaturcaraan sebenar SWE-bench
Jul 17, 2024 pm 10:02 PM
 Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
Pengarang ControlNet mendapat satu lagi kejayaan! Seluruh proses menghasilkan lukisan daripada gambar, memperoleh 1.4k bintang dalam masa dua hari
Jul 17, 2024 am 01:56 AM
 Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
Kertas arXiv boleh disiarkan sebagai 'bertubi-tubi', platform perbincangan Stanford alphaXiv dalam talian, LeCun menyukainya
Aug 01, 2024 pm 05:18 PM
 Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh
Jul 23, 2024 pm 02:05 PM
Penjanaan video tanpa had, perancangan dan membuat keputusan, penyebaran paksa penyepaduan ramalan token seterusnya dan penyebaran jujukan penuh
Jul 23, 2024 pm 02:05 PM
 Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
Satu kejayaan ketara dalam Hipotesis Riemann! Tao Zhexuan amat mengesyorkan kertas kerja baharu daripada MIT dan Oxford, dan pemenang Fields Medal berusia 37 tahun mengambil bahagian
Aug 05, 2024 pm 03:32 PM
 Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
Latihan aksiomatik membolehkan LLM mempelajari penaakulan kausal: model 67 juta parameter adalah setanding dengan trilion tahap parameter GPT-4
Jul 17, 2024 am 10:14 AM
