
 Peranti teknologi
AI
YOLOv10 ada di sini! Pengesanan sasaran hujung ke hujung masa nyata sebenar
Peranti teknologi
AI
YOLOv10 ada di sini! Pengesanan sasaran hujung ke hujung masa nyata sebenar
YOLOv10 ada di sini! Pengesanan sasaran hujung ke hujung masa nyata sebenar

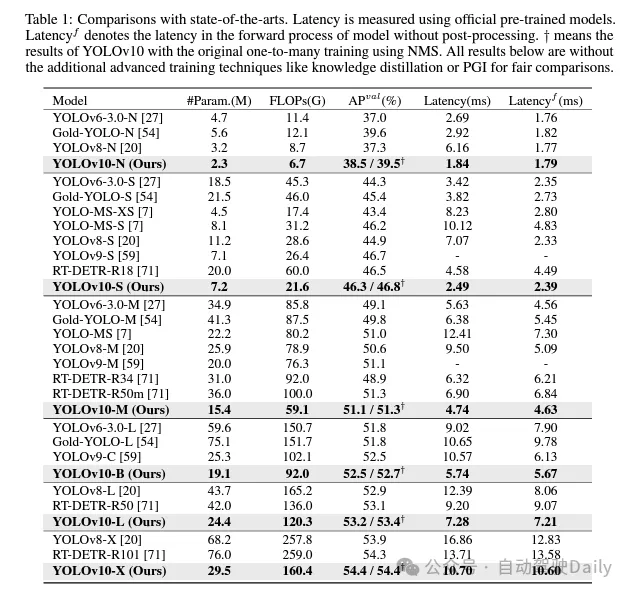
Dalam beberapa tahun kebelakangan ini, YOLO telah menjadi paradigma arus perdana dalam bidang pengesanan objek masa nyata kerana keseimbangannya yang berkesan antara kos pengiraan dan prestasi pengesanan. Penyelidik telah menjalankan penerokaan mendalam tentang reka bentuk struktur, matlamat pengoptimuman, strategi peningkatan data, dsb. YOLO dan telah mencapai kemajuan yang ketara. Walau bagaimanapun, pergantungan pasca pemprosesan pada penindasan bukan maksimum (NMS) menghalang penggunaan YOLO hujung ke hujung dan memberi kesan negatif kependaman inferens. Tambahan pula, reka bentuk pelbagai komponen dalam YOLO tidak mempunyai semakan yang komprehensif dan menyeluruh, mengakibatkan redundansi pengiraan yang ketara dan mengehadkan prestasi model. Ini menghasilkan kecekapan yang tidak optimum, dan potensi besar untuk peningkatan prestasi. Dalam kerja ini, kami berhasrat untuk memajukan lagi sempadan kecekapan prestasi YOLO daripada kedua-dua pasca pemprosesan dan seni bina model. Untuk tujuan ini, kami mula-mula mencadangkan peruntukan dwi yang berterusan untuk latihan YOLO tanpa NMS, yang pada masa yang sama membawa prestasi kompetitif dan kependaman inferens yang rendah. Tambahan pula, kami memperkenalkan strategi reka bentuk model yang didorong oleh ketepatan kecekapan yang komprehensif untuk YOLO. Kami telah mengoptimumkan secara menyeluruh setiap komponen YOLO dari perspektif kecekapan dan ketepatan, yang sangat mengurangkan overhed pengiraan dan meningkatkan keupayaan model. Hasil daripada usaha kami ialah generasi baharu siri YOLO yang direka untuk pengesanan objek hujung ke hujung masa nyata, yang dipanggil YOLOv10. Eksperimen yang meluas menunjukkan bahawa YOLOv10 mencapai prestasi dan kecekapan terkini pada pelbagai skala model. Sebagai contoh, pada set data COCO, YOLOv10-S kami adalah 1.8 kali lebih pantas daripada RT-DETR-R18 di bawah AP yang serupa, sambil mengurangkan parameter dan operasi titik terapung (FLOP) sebanyak 2.8 kali. Berbanding dengan YOLOv9-C, YOLOv10-B mengurangkan kependaman sebanyak 46% dan mengurangkan parameter sebanyak 25% di bawah prestasi yang sama. Pautan kod: https://github.com/THU-MIG/yolov10.
Apakah penambahbaikan yang terdapat dalam YOLOv10?
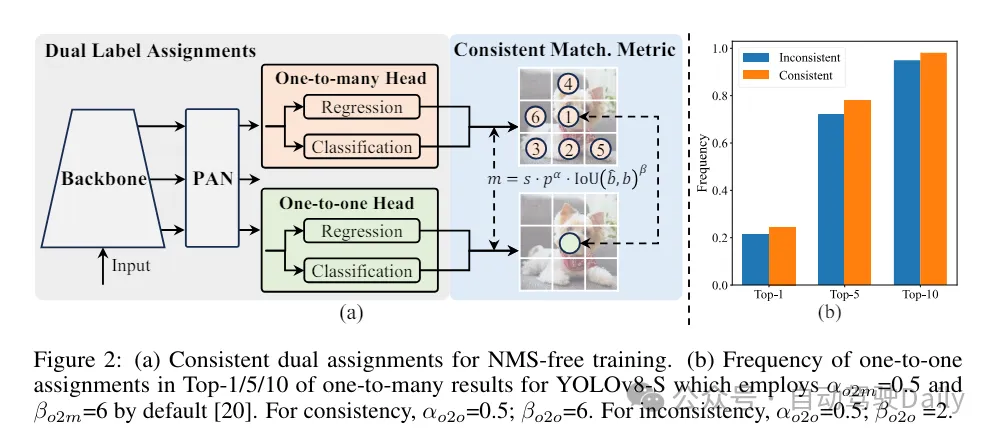
Pertama-tama selesaikan masalah ramalan yang berlebihan dalam pasca pemprosesan dengan mencadangkan strategi dua peruntukan yang berterusan untuk YOLO tanpa NMS. Strategi ini termasuk tugasan dwi label dan metrik padanan yang konsisten. Ini membolehkan model memperoleh penyeliaan yang kaya dan harmoni semasa latihan sambil menghapuskan keperluan untuk NMS semasa inferens, mencapai prestasi kompetitif sambil mengekalkan kecekapan tinggi.
Kali ini, strategi reka bentuk model dipacu kecekapan-ketepatan yang komprehensif dicadangkan untuk seni bina model, dan setiap komponen dalam YOLO diperiksa secara menyeluruh. Dari segi kecekapan, kepala pengelasan ringan, pensampelan bawah gandingan saluran ruang dan reka bentuk blok berpandukan pangkat dicadangkan untuk mengurangkan lebihan pengiraan yang jelas dan mencapai seni bina yang lebih cekap.
Dari segi ketepatan, konvolusi kernel yang besar diterokai dan modul separa perhatian diri yang berkesan dicadangkan untuk meningkatkan keupayaan model dan memanfaatkan potensi peningkatan prestasi pada kos yang rendah.
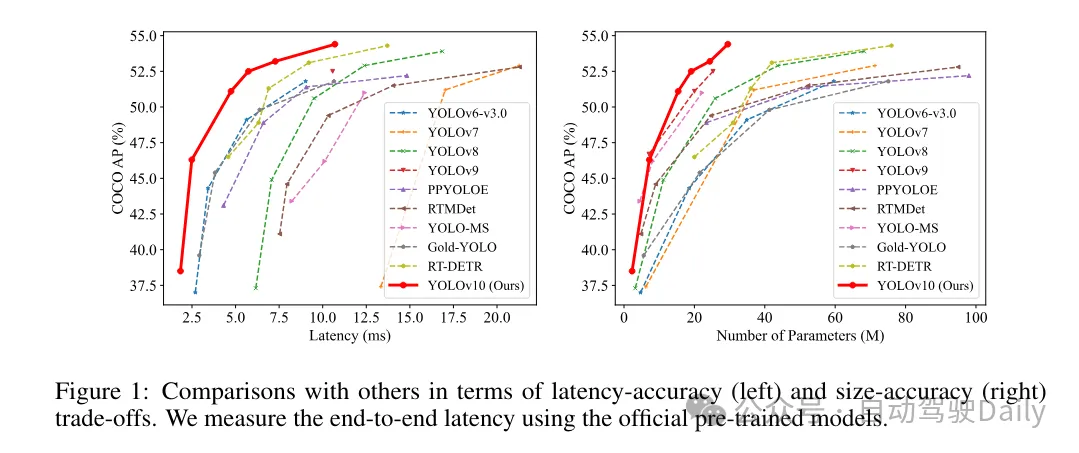
Berdasarkan kaedah ini, penulis berjaya melaksanakan satu siri pengesan hujung ke hujung masa nyata dengan saiz model yang berbeza, iaitu YOLOv10-N/S/M/B/L/X. Eksperimen yang meluas pada penanda aras pengesanan objek standard menunjukkan bahawa YOLOv10 menunjukkan keupayaan untuk mengatasi prestasi model terkini dari segi pertukaran ketepatan pengiraan pada pelbagai saiz model. Seperti yang ditunjukkan dalam Rajah 1, di bawah prestasi yang sama, YOLOv10-S/X masing-masing adalah 1.8 kali/1.3 kali lebih pantas daripada RT-DETR R18/R101. Berbanding dengan YOLOv9-C, YOLOv10-B mencapai 46% pengurangan kependaman di bawah prestasi yang sama. Di samping itu, YOLOv10 menunjukkan kecekapan penggunaan parameter yang sangat tinggi. YOLOv10-L/X ialah 0.3 AP dan 0.5 AP lebih tinggi daripada YOLOv8-L/X dengan bilangan parameter dikurangkan masing-masing sebanyak 1.8 kali dan 2.3 kali. YOLOv10-M mencapai AP yang serupa dengan YOLOv9-M/YOLO-MS sambil mengurangkan bilangan parameter masing-masing sebanyak 23% dan 31%.
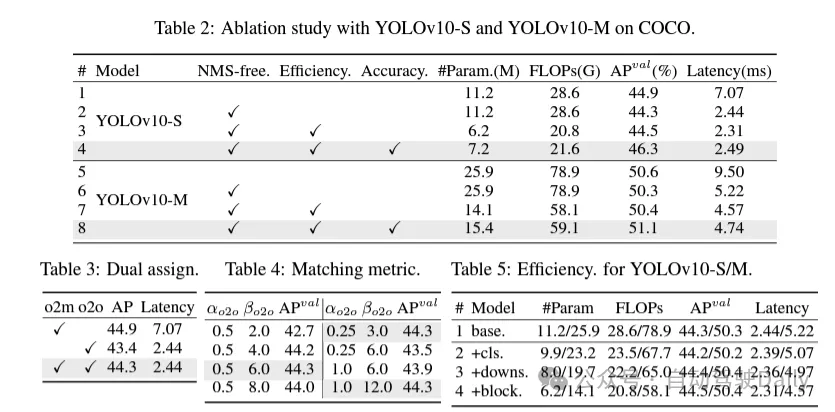
Semasa proses latihan, YOLO biasanya menggunakan TAL (Pembelajaran Tugasan Tugasan) untuk memberikan berbilang sampel kepada setiap kejadian. Mengguna pakai kaedah peruntukan satu kepada banyak menjana isyarat penyeliaan yang kaya, yang membantu mengoptimumkan dan mencapai prestasi yang lebih kukuh. Walau bagaimanapun, ini juga menjadikan YOLO mesti bergantung pada NMS (penindasan bukan maksimum) pasca pemprosesan, yang menghasilkan kecekapan inferens suboptimum pada masa penggunaan. Walaupun kerja-kerja terdahulu telah meneroka pendekatan padanan satu-dengan-satu untuk menyekat ramalan berlebihan, mereka sering menambah overhed inferens tambahan atau menghasilkan prestasi suboptimum. Dalam kerja ini, kami mencadangkan strategi latihan bebas NMS yang menggunakan tugasan dwi label dan metrik padanan yang konsisten, mencapai kecekapan tinggi dan prestasi daya saing. Melalui strategi ini, YOLO kami tidak lagi memerlukan NMS dalam latihan, mencapai kecekapan tinggi dan prestasi kompetitif.
Reka bentuk model dipacu kecekapan. Komponen dalam YOLO termasuk batang, lapisan pensampelan bawah, peringkat dengan blok binaan asas, dan kepala. Kos pengiraan bahagian tulang belakang adalah sangat rendah, jadi kami melaksanakan reka bentuk model dipacu kecekapan untuk tiga bahagian yang lain.
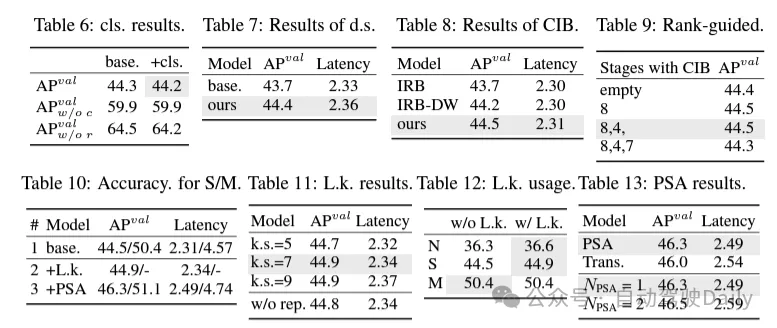
(1) Pengepala pengelasan ringan. Dalam YOLO, kepala klasifikasi dan kepala regresi biasanya mempunyai seni bina yang sama. Walau bagaimanapun, mereka mempunyai perbezaan yang ketara dalam overhed pengiraan. Sebagai contoh, dalam YOLOv8-S, bilangan FLOP dan parameter kepala pengelasan (5.95G/1.51M FLOP dan parameter) dan kepala regresi (2.34G/0.64M) ialah 2.5 kali dan 2.4 kali ganda daripada regresi kepala masing-masing. Walau bagaimanapun, dengan menganalisis kesan ralat klasifikasi dan ralat regresi (lihat Jadual 6), kami mendapati bahawa kepala regresi adalah lebih penting kepada prestasi YOLO. Oleh itu, kita boleh mengurangkan overhed pengepala pengelasan tanpa perlu risau tentang kemudaratan prestasi. Oleh itu, kami hanya mengguna pakai seni bina kepala pengelasan ringan, yang terdiri daripada dua konvolusi yang boleh dipisahkan secara mendalam dengan saiz kernel 3 × 3, diikuti dengan kernel 1 × 1. Melalui penambahbaikan di atas, kita boleh memudahkan seni bina kepala pengelasan ringan, yang terdiri daripada dua konvolusi boleh dipisahkan dalam dengan saiz kernel lilitan 3 × 3, diikuti dengan kernel lilitan 1 × 1. Seni bina yang dipermudahkan ini boleh mencapai fungsi klasifikasi dengan overhed pengiraan yang lebih kecil dan bilangan parameter.
(2) Pensampelan nyahgandingan saluran ruang. YOLO biasanya menggunakan lilitan piawai 3×3 biasa dengan langkah 2, sambil melaksanakan pensampelan bawah spatial (dari H × W ke H/2 × W/2) dan transformasi saluran (dari C ke 2C). Ini memperkenalkan kos pengiraan dan kiraan parameter yang tidak boleh diabaikan. Sebaliknya, kami mencadangkan untuk memisahkan pengurangan ruang dan operasi pembesaran saluran untuk mencapai pensampelan turun yang lebih cekap. Khususnya, lilitan arah mata digunakan untuk memodulasi dimensi saluran, dan kemudian lilitan mendalam digunakan untuk pensampelan spatial. Ini mengurangkan kos pengiraan dan pengiraan parameter kepada . Pada masa yang sama, ia memaksimumkan pengekalan maklumat semasa pensampelan turun, dengan itu mengurangkan kependaman sambil mengekalkan prestasi kompetitif.
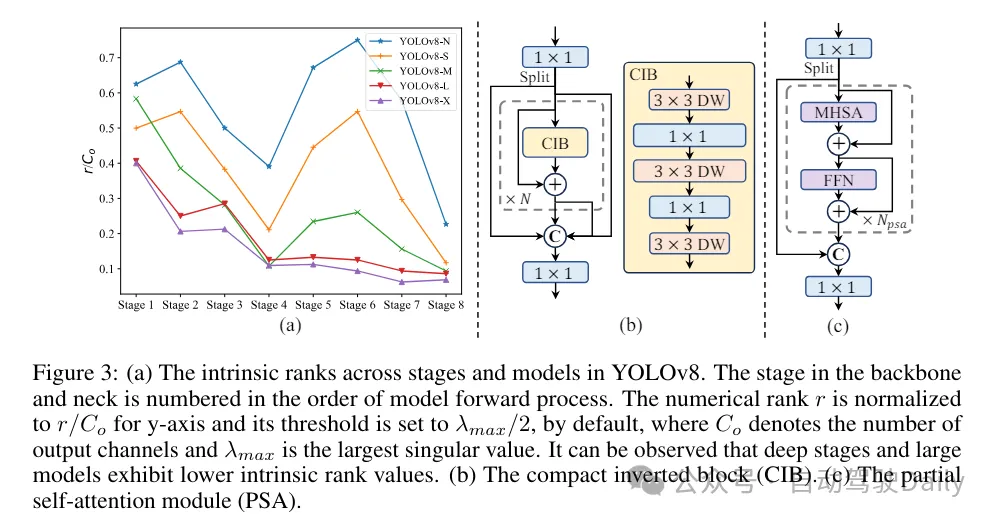
(3) Reka bentuk modul berdasarkan bimbingan pangkat. YOLO biasanya menggunakan blok binaan asas yang sama untuk semua peringkat, seperti blok kesesakan dalam YOLOv8. Untuk mengkaji secara menyeluruh reka bentuk isomorfik YOLO ini, kami menggunakan kedudukan intrinsik untuk menganalisis lebihan setiap peringkat. Secara khusus, kedudukan berangka bagi lilitan terakhir dalam blok asas terakhir dalam setiap peringkat dikira, yang mengira bilangan nilai tunggal yang lebih besar daripada ambang. Rajah 3(a) menunjukkan keputusan YOLOv8, menunjukkan bahawa peringkat dalam dan model besar lebih berkemungkinan menunjukkan lebihan redundansi. Pemerhatian ini menunjukkan bahawa hanya menggunakan reka bentuk blok yang sama pada semua peringkat adalah suboptimum untuk mencapai pertukaran kecekapan kapasiti terbaik. Untuk menyelesaikan masalah ini, skim reka bentuk modul berasaskan pangkat dicadangkan, yang bertujuan untuk mengurangkan kerumitan peringkat yang terbukti berlebihan melalui reka bentuk seni bina yang padat.
Kami mula-mula memperkenalkan struktur bongkah terbalik padat (CIB) yang menggunakan lilitan kedalaman yang murah untuk pencampuran ruang dan lilitan arah yang kos efektif untuk pencampuran saluran, seperti yang ditunjukkan dalam Rajah 3(b). Ia boleh berfungsi sebagai blok binaan asas yang berkesan, contohnya tertanam dalam struktur ELAN (Rajah 3(b)). Kemudian, strategi peruntukan modul berasaskan pangkat digalakkan untuk mencapai kecekapan optimum sambil mengekalkan kuasa daya saing. Khususnya, berdasarkan model, susun semua peringkat mengikut susunan menaik pangkat intrinsiknya. Periksa lebih lanjut perubahan prestasi selepas menggantikan blok asas peringkat utama dengan CIB. Jika tiada kemerosotan prestasi berbanding model yang diberikan, kami terus menggantikan peringkat seterusnya, jika tidak, hentikan proses tersebut. Hasilnya, kami boleh melaksanakan reka bentuk blok padat suai pada peringkat dan saiz model yang berbeza, mencapai kecekapan yang lebih tinggi tanpa menjejaskan prestasi.
Berdasarkan reka bentuk model berorientasikan ketepatan. Makalah ini meneroka lebih lanjut mekanisme konvolusi kernel besar dan perhatian kendiri untuk mencapai reka bentuk berasaskan ketepatan, bertujuan untuk meningkatkan prestasi pada kos yang minimum.
(1) Konvolusi isirong besar. Mengguna pakai lilitan dalam kernel besar ialah cara yang berkesan untuk mengembangkan medan penerimaan dan meningkatkan keupayaan model. Walau bagaimanapun, hanya mengeksploitasinya dalam semua peringkat boleh menyebabkan pencemaran dalam ciri cetek yang digunakan untuk mengesan objek kecil, sementara juga memperkenalkan overhed I/O yang ketara dan kependaman dalam peringkat resolusi tinggi. Oleh itu, penulis mencadangkan untuk menggunakan lilitan dalam kernel besar dalam blok maklumat antara peringkat (CIB) peringkat dalam. Di sini saiz kernel lilitan 3×3 mendalam kedua dalam CIB dinaikkan kepada 7×7. Selain itu, teknologi penyusunan semula struktur diguna pakai untuk memperkenalkan satu lagi cawangan konvolusi kedalaman 3×3 untuk mengurangkan masalah pengoptimuman tanpa meningkatkan overhed inferens. Tambahan pula, apabila saiz model bertambah, medan penerimaannya mengembang secara semula jadi, dan faedah menggunakan belitan kernel besar secara beransur-ansur berkurangan. Oleh itu, lilitan kernel besar hanya digunakan pada skala model kecil.
(2) Separa Perhatian Diri (PSA). Mekanisme perhatian diri digunakan secara meluas dalam pelbagai tugas visual kerana keupayaan pemodelan globalnya yang sangat baik. Walau bagaimanapun, ia mempamerkan kerumitan pengiraan yang tinggi dan jejak ingatan. Untuk menyelesaikan masalah ini, memandangkan redundansi kepala perhatian yang ada di mana-mana, penulis mencadangkan reka bentuk modul perhatian kendiri separa (PSA) yang cekap, seperti ditunjukkan dalam Rajah 3.(c). Secara khusus, ciri dibahagikan sama rata kepada dua bahagian mengikut saluran selepas lilitan 1×1. Hanya sebahagian daripada ciri dimasukkan ke dalam blok NPSA yang terdiri daripada modul perhatian diri berbilang kepala (MHSA) dan rangkaian suapan ke hadapan (FFN). Kemudian, kedua-dua bahagian ciri disambung dan dicantumkan melalui lilitan 1×1. Selain itu, tetapkan dimensi pertanyaan dan kunci dalam MHSA kepada separuh daripada nilai dan gantikan LayerNorm dengan BatchNorm untuk inferens pantas. PSA hanya diletakkan selepas peringkat 4 dengan resolusi terendah untuk mengelakkan overhed berlebihan yang disebabkan oleh kerumitan pengiraan kuadratik perhatian diri. Dengan cara ini, keupayaan pembelajaran perwakilan global boleh digabungkan ke dalam YOLO pada kos pengiraan yang rendah, sekali gus meningkatkan keupayaan model dan meningkatkan prestasi.
Perbandingan eksperimen
Saya tidak akan memperkenalkan terlalu banyak di sini, hanya hasilnya! ! ! Latensi dikurangkan dan prestasi terus meningkat.
Atas ialah kandungan terperinci YOLOv10 ada di sini! Pengesanan sasaran hujung ke hujung masa nyata sebenar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Apakah maksud hujung ke hujung?
Sep 27, 2021 pm 12:10 PM
Apakah maksud hujung ke hujung?
Sep 27, 2021 pm 12:10 PM
Hujung ke hujung merujuk kepada "sambungan rangkaian". Untuk rangkaian untuk berkomunikasi, sambungan mesti diwujudkan Tidak kira berapa jauh atau berapa banyak mesin di antara, sambungan mesti diwujudkan di antara kedua-dua hujung Setelah sambungan diwujudkan, ia dikatakan sebagai hujung -sambungan hujung, iaitu hujung ke hujung ialah pautan logik.
 Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
1. Pengenalan Pada masa ini, pengesan objek utama ialah rangkaian dua peringkat atau satu peringkat berdasarkan rangkaian pengelas tulang belakang yang digunakan semula CNN dalam. YOLOv3 ialah salah satu pengesan satu peringkat tercanggih yang menerima imej input dan membahagikannya kepada matriks grid bersaiz sama. Sel grid dengan pusat sasaran bertanggungjawab untuk mengesan sasaran tertentu. Apa yang saya kongsikan hari ini ialah kaedah matematik baharu yang memperuntukkan berbilang grid kepada setiap sasaran untuk mencapai ramalan kotak sempadan ketat muat yang tepat. Para penyelidik juga mencadangkan peningkatan data salin-tampal luar talian yang berkesan untuk pengesanan sasaran. Kaedah yang baru dicadangkan dengan ketara mengatasi beberapa pengesan objek terkini dan menjanjikan prestasi yang lebih baik. 2. Rangkaian pengesanan sasaran latar belakang direka bentuk untuk digunakan
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
 SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
Dalam bidang pengesanan sasaran, YOLOv9 terus membuat kemajuan dalam proses pelaksanaan Dengan mengguna pakai seni bina dan kaedah baharu, ia secara berkesan meningkatkan penggunaan parameter konvolusi tradisional, yang menjadikan prestasinya jauh lebih unggul daripada produk generasi sebelumnya. Lebih setahun selepas YOLOv8 dikeluarkan secara rasmi pada Januari 2023, YOLOv9 akhirnya hadir! Sejak Joseph Redmon, Ali Farhadi dan yang lain mencadangkan model YOLO generasi pertama pada 2015, penyelidik dalam bidang pengesanan sasaran telah mengemas kini dan mengulanginya berkali-kali. YOLO ialah sistem ramalan berdasarkan maklumat global imej, dan prestasi modelnya terus dipertingkatkan. Dengan menambah baik algoritma dan teknologi secara berterusan, penyelidik telah mencapai hasil yang luar biasa, menjadikan YOLO semakin berkuasa dalam tugas pengesanan sasaran.
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
 Bagaimana untuk menggunakan C++ untuk penjejakan imej berprestasi tinggi dan pengesanan sasaran?
Aug 26, 2023 pm 03:25 PM
Bagaimana untuk menggunakan C++ untuk penjejakan imej berprestasi tinggi dan pengesanan sasaran?
Aug 26, 2023 pm 03:25 PM
Bagaimana untuk menggunakan C++ untuk penjejakan imej berprestasi tinggi dan pengesanan sasaran? Abstrak: Dengan perkembangan pesat kecerdasan buatan dan teknologi penglihatan komputer, pengesanan imej dan pengesanan sasaran telah menjadi bidang penyelidikan yang penting. Artikel ini akan memperkenalkan cara untuk mencapai penjejakan imej berprestasi tinggi dan pengesanan sasaran dengan menggunakan bahasa C++ dan beberapa perpustakaan sumber terbuka serta menyediakan contoh kod. Pengenalan: Penjejakan imej dan pengesanan objek adalah dua tugas penting dalam bidang penglihatan komputer. Ia digunakan secara meluas dalam banyak bidang, seperti pengawasan video, pemanduan autonomi, sistem pengangkutan pintar, dll. untuk
 Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Berbilang SOTA! OV-Uni3DETR: Meningkatkan kebolehgeneralisasian pengesanan 3D merentas kategori, adegan dan modaliti (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Kertas kerja ini membincangkan bidang pengesanan objek 3D, terutamanya pengesanan objek 3D untuk Open-Vocabulary. Dalam tugas pengesanan objek 3D tradisional, sistem perlu meramalkan lokasi objek dalam adegan sebenar kotak sempadan 3D dan label kategori semantik, yang biasanya bergantung pada awan titik atau imej RGB. Walaupun teknologi pengesanan objek 2D berprestasi baik kerana keluasan dan kelajuannya, penyelidikan berkaitan menunjukkan bahawa pembangunan pengesanan universal 3D ketinggalan berbanding perbandingan. Pada masa ini, kebanyakan kaedah pengesanan objek 3D masih bergantung pada pembelajaran diselia sepenuhnya dan dihadkan oleh data beranotasi sepenuhnya di bawah mod input tertentu dan hanya boleh mengecam kategori yang muncul semasa latihan, sama ada dalam adegan dalaman atau luaran. Makalah ini menunjukkan bahawa cabaran yang dihadapi oleh pengesanan sasaran universal 3D adalah terutamanya
 Pada tahun 2024, adakah terdapat kejayaan besar dan kemajuan dalam pemanduan autonomi hujung ke hujung di China?
May 08, 2024 pm 02:49 PM
Pada tahun 2024, adakah terdapat kejayaan besar dan kemajuan dalam pemanduan autonomi hujung ke hujung di China?
May 08, 2024 pm 02:49 PM
Tidak semua orang dapat memahami bahawa Tesla V12 telah dilancarkan secara besar-besaran di Amerika Utara dan telah mendapat pengiktirafan daripada semakin ramai pengguna kerana prestasi cemerlangnya pemanduan autonomi hujung ke hujung juga telah menjadi arah teknikal yang paling dibimbangkan oleh semua orang tentang dalam industri pemanduan autonomi. Baru-baru ini, saya mempunyai peluang untuk mengadakan beberapa pertukaran dengan jurutera kelas pertama, pengurus produk, pelabur dan orang media dalam banyak industri. Saya mendapati bahawa semua orang sangat berminat dengan pemanduan autonomi hujung ke hujung, tetapi dari segi beberapa pemahaman asas pemanduan autonomi hujung ke hujung, Masih terdapat salah faham seperti ini. Sebagai seseorang yang cukup bertuah untuk merasai fungsi bandar dengan dan tanpa gambar daripada jenama peringkat pertama domestik, serta dua versi FSD V11 dan V12, di sini saya ingin bercakap tentang beberapa perkara pada peringkat ini berdasarkan latar belakang profesional saya dan menjejaki kemajuan Tesla FSD selama ini.
