

Dengan model besar sebagai rahmat pintar, robot humanoid telah menjadi trend baharu.
Robot dalam filem fiksyen sains "boleh memberitahu bahawa saya bukan manusia" nampaknya semakin hampir.
Namun, masih menjadi masalah kejuruteraan yang sukar untuk robot, terutamanya robot humanoid, untuk berfikir dan bertindak seperti manusia.
Ambil pembelajaran mudah untuk berjalan sebagai contoh Menggunakan pembelajaran pengukuhan untuk melatih mungkin berubah menjadi yang berikut:

Tiada masalah dalam teori (mengikut mekanisme ganjaran), dan matlamat untuk pergi. menaiki tangga telah dicapai , kecuali prosesnya agak abstrak, ia mungkin tidak sama dengan kebanyakan corak tingkah laku manusia.
Sebab sukar bagi robot untuk bertindak "secara semula jadi" seperti manusia adalah disebabkan sifat pemerhatian dan ruang tindakan yang berdimensi tinggi, dan ketidakstabilan yang wujud dalam bentuk bipedal.
Dalam hal ini, kerja yang disertai LeCun memberikan penyelesaian baharu berdasarkan dipacu data.

Alamat kertas: https://arxiv.org/pdf/2405.18418
Pengenalan projek: https://nicklashansen.com/rlpuppeteer

Semestinya beberapa netizen yang datang membuat onar berkata, "Yang sebelum ini nampak lebih menarik."

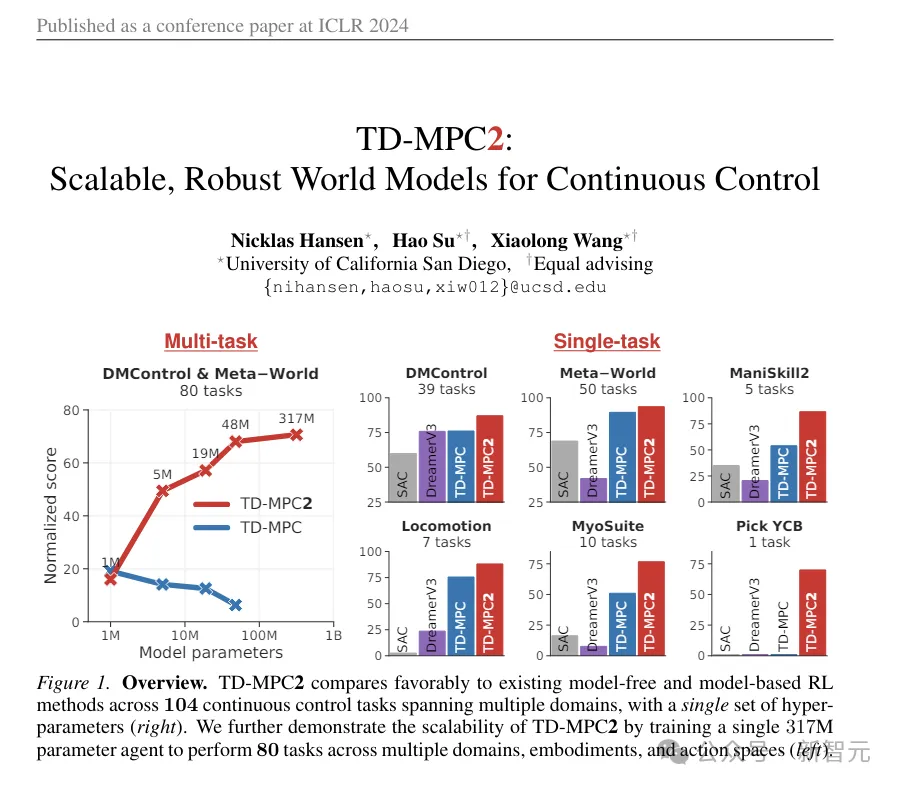
Pengarang mencadangkan model dunia hierarki untuk melatih dua ejen, peringkat tinggi dan peringkat rendah Ejen peringkat tinggi menjana arahan berdasarkan pemerhatian visual untuk ejen peringkat rendah untuk dilaksanakan.
Model ini, dinamakan Puppeteer, menggunakan simulasi 56-DoF robot tugasan strategi humanoid8 untuk menjana prestasi tinggi dalam 8 sambil mensintesis pergerakan semula jadi seperti manusia dan keupayaan untuk merentasi rupa bumi yang mencabar.
 Model dunia hierarki terkawal berdimensi tinggi
Model dunia hierarki terkawal berdimensi tinggi
Robot humanoid boleh melakukan pelbagai tugas dengan menyepadukan kawalan dan persepsi seluruh badan, supaya ia menonjol sebagai platform pelbagai fungsi.
Tetapi kos meniru haiwan canggih seperti kita masih sangat tinggi.
Sebagai contoh, dalam gambar di bawah, untuk mengelak daripada melangkah ke dalam lubang, robot humanoid perlu mengesan dengan tepat kedudukan dan panjang celah lantai yang akan datang, dan pada masa yang sama berhati-hati menyelaraskan pergerakan seluruh badannya supaya ia mempunyai momentum dan julat yang mencukupi untuk merentasi setiap jurang A.

Ia terdiri daripada dua ejen yang berbeza: satu bertanggungjawab untuk persepsi dan penjejakan, menjejaki gerakan rujukan melalui kawalan peringkat bersama (puppeteer) yang lain belajar untuk melaksanakan tugas hiliran dengan mensintesis gerakan rujukan dimensi rendah, iaitu bekas sokongan pengesanan.
Puppeteer menggunakan algoritma RL-TD-MPC2 berasaskan model untuk melatih dua ejen secara bebas dalam dua peringkat berbeza.
(ps: TD-MPC2 ini adalah gambar animasi yang digunakan untuk perbandingan pada awal artikel. Walaupun nampak agak abstrak, ia sebenarnya SOTA sebelumnya, diterbitkan dalam ICLR tahun ini, dan karya pertama ialah juga karya pertama artikel ini.)
Pada peringkat pertama, model dunia untuk penjejakan pertama kali dipralatih, menggunakan data tangkapan gerakan manusia yang sedia ada sebagai rujukan untuk menukar gerakan kepada tindakan yang boleh dilaksanakan secara fizikal . Ejen ini boleh disimpan dan digunakan semula dalam semua tugas hiliran.
Di peringkat kedua, model dunia boneka dilatih, yang mengambil pemerhatian visual sebagai input dan mengintegrasikan gerakan rujukan yang disediakan oleh ejen lain sebagai output mengikut tugas hiliran yang ditentukan.
Rangka kerja ini kelihatan sangat mudah: kedua-dua model dunia adalah sama dari segi algoritma, hanya berbeza dalam input/output, dan dilatih menggunakan RL tanpa sebarang loceng dan wisel lain.
Berbeza daripada tetapan RL hierarki tradisional, "Boneka" mengeluarkan kedudukan geometri sendi kesan akhir dan bukannya pembenaman sasaran.
Ini menjadikan ejen yang bertanggungjawab untuk menjejak mudah untuk dikongsi dan digeneralisasikan antara tugas, menjimatkan ruang pengkomputeran keseluruhan.
Para penyelidik memodelkan kawalan humanoid seluruh badan visual sebagai masalah pembelajaran pengukuhan yang dikawal oleh proses keputusan Markov (MDP), yang berdasarkan tuple (S, A, T, R , γ , Δ) ialah ciri,
di mana S ialah keadaan, A ialah tindakan, T ialah fungsi peralihan persekitaran, R ialah fungsi ganjaran skalar, γ ialah faktor diskaun, dan Δ ialah syarat penamatan.
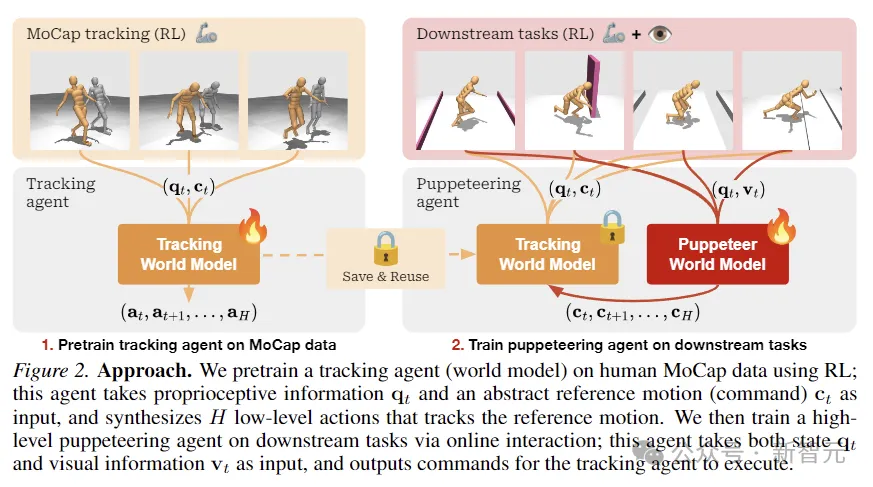
Seperti yang ditunjukkan dalam rajah di atas, para penyelidik menggunakan RL untuk pra-melatih ejen penjejakan pada data MoCap manusia, yang digunakan untuk mendapatkan maklumat proprioseptif dan input gerakan rujukan abstrak, dan mensintesis tindakan peringkat rendah untuk menjejaki gerakan rujukan.
Kemudian melalui interaksi dalam talian, ejen boneka lanjutan yang bertanggungjawab untuk tugas hiliran dilatih Boneka menerima status dan maklumat visual dan arahan output untuk ejen penjejakan.
TD-MPC2
TD-MPC2 mempelajari model dunia tanpa penyahkod terpendam daripada interaksi persekitaran dan menggunakan model yang dipelajari untuk perancangan.
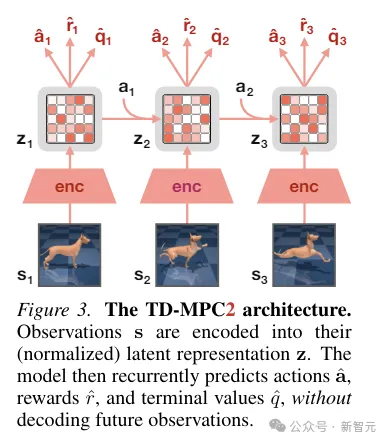
Semua komponen model dunia dipelajari dari hujung ke hujung menggunakan gabungan ramalan benam bersama, ramalan ganjaran dan kehilangan perbezaan temporal tanpa menyahkod pemerhatian asal.
Semasa inferens, TD-MPC2 mengikut rangka kerja Model Predictive Control (MPC), menggunakan Model Predictive Path Integral (MPPI) sebagai pengoptimum bebas derivatif (berasaskan persampelan) untuk pengoptimuman trajektori tempatan.
Untuk mempercepatkan perancangan, TD-MPC2 juga mempelajari strategi tanpa model terlebih dahulu untuk pra-memulakan program pensampelan. . robot humanoid darjah-kebebasan untuk kawalan seluruh badan visual Ia mengandungi sejumlah 8 tugasan yang mencabar. Kaedah yang digunakan untuk perbandingan termasuk SAC, DreamerV3 dan TD-MPC2.
8 tugasan ditunjukkan dalam rajah di bawah, termasuk 5 tugasan pergerakan seluruh badan keadaan visual, dan 3 tugasan lagi tanpa input visual.
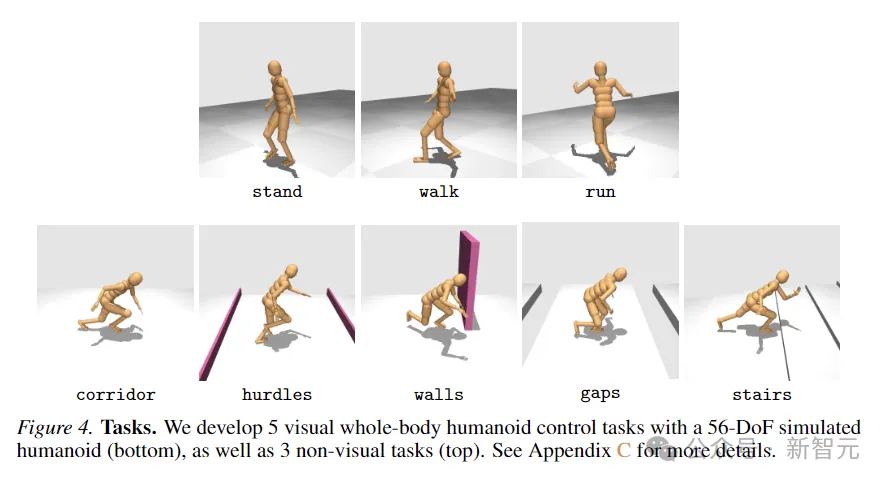
Pencarian direka bentuk dengan tahap rawak yang tinggi dan termasuk berlari ke koridor, melompati halangan dan celah, berjalan menaiki tangga dan mengelilingi dinding.
Lima tugas kawalan visual semuanya menggunakan fungsi ganjaran yang berkadar dengan kelajuan ke hadapan linear, manakala tugas bukan visual memberi ganjaran kepada anjakan ke mana-mana arah.
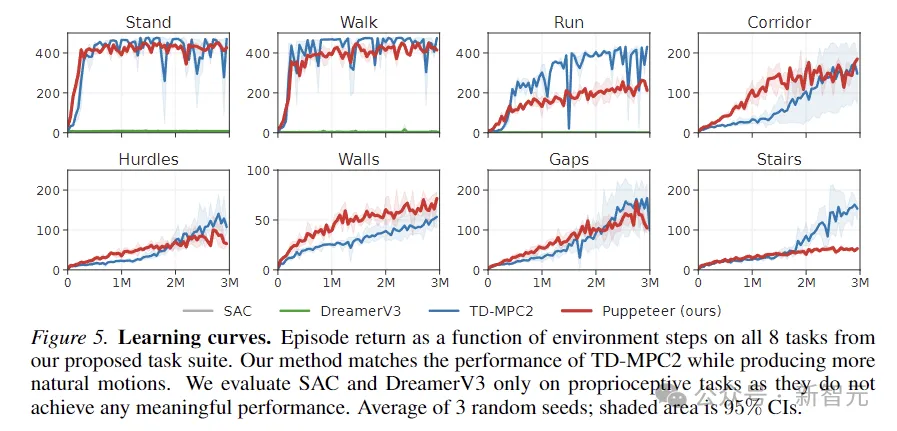
Gambar di atas menggambarkan keluk pembelajaran. Keputusan menunjukkan bahawa SAC dan DreamerV3 tidak dapat mencapai prestasi yang bermakna pada tugasan ini.
TD-MPC2 berprestasi setanding dengan kaedah kami dari segi ganjaran, tetapi menghasilkan tingkah laku yang tidak wajar (lihat tindakan abstrak dalam imej di bawah).

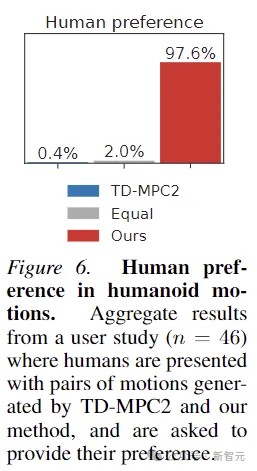
Selain itu, bagi membuktikan pergerakan yang dijana oleh Puppeteer sememangnya lebih "natural", artikel ini turut menjalankan ujikaji pilihan manusia terhadap 46 peserta menunjukkan manusia secara umumnya menyukai pergerakan yang dihasilkan oleh kaedah ini.
Atas ialah kandungan terperinci Kerja baharu LeCun: model dunia berlapis, kawalan robot humanoid dipacu data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana oracle berputar
Bagaimana oracle berputar
 Apakah maksud ICO?
Apakah maksud ICO?
 Bagaimana untuk menutup port 135 445
Bagaimana untuk menutup port 135 445
 Bagaimana untuk menyelesaikan masalah bahawa fail msxml6.dll hilang
Bagaimana untuk menyelesaikan masalah bahawa fail msxml6.dll hilang
 Bagaimana untuk menyelesaikan tiada laluan ke hos
Bagaimana untuk menyelesaikan tiada laluan ke hos
 Bagaimana untuk menyelesaikan masalah apabila suhu CPU komputer terlalu tinggi
Bagaimana untuk menyelesaikan masalah apabila suhu CPU komputer terlalu tinggi
 Penjelasan terperinci tentang fungsi garpu Linux
Penjelasan terperinci tentang fungsi garpu Linux
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



