Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Model bahasa visual arus perdana (VLM) terutamanya berdasarkan model bahasa besar (LLM) untuk penalaan lebih lanjut. Oleh itu, adalah perlu untuk memetakan imej ke ruang benam LLM dalam pelbagai cara, dan kemudian menggunakan kaedah autoregresif untuk meramalkan jawapan berdasarkan token imej. Dalam proses ini, penjajaran modal dilaksanakan secara tersirat melalui token teks Cara menyelaraskan langkah ini dengan baik adalah sangat kritikal. Sebagai tindak balas kepada masalah ini, penyelidik dari Universiti Wuhan, Pasukan Model Besar ByteDance Beanbao dan Akademi Sains Universiti China mencadangkan kaedah saringan token teks (CAL) berdasarkan pembelajaran kontras untuk menyaring Token teks yang sangat berkaitan dengan imej dinaikkan dalam berat fungsi kehilangan untuk mencapai penjajaran berbilang modal yang lebih tepat. Pautan kertas: https://arxiv.org/pdf/2405.17871 CAL mempunyai sorotan berikut:
- boleh terus bersarang ke dalam proses latihan tanpa peringkat pra-latihan tambahan.
- telah mencapai peningkatan ketara dalam penanda aras OCR dan Kapsyen Daripada visualisasi, didapati bahawa CAL menjadikan penjajaran modal imej lebih baik.
CAL menjadikan proses latihan lebih tahan terhadap data bising.
Motivasi penyelidikan
Pada masa ini, model bahasa visual bergantung pada penjajaran modaliti imej, dan bagaimana untuk melakukan penjajaran. Kaedah arus perdana semasa adalah untuk melakukan penjajaran tersirat melalui autoregresi teks, tetapi sumbangan setiap token teks kepada penjajaran imej adalah sangat perlu untuk membezakan token teks ini.
CAL mencadangkan bahawa dalam data latihan model bahasa visual (VLM) sedia ada, token teks boleh dibahagikan kepada tiga kategori:
Teks yang sangat berkaitan dengan gambar Seperti orang, haiwan, objek), kuantiti, warna, teks, dll. Token ini secara langsung sepadan dengan maklumat imej dan penting untuk penjajaran berbilang modal.
Teks dengan korelasi rendah dengan gambar
: Seperti perkataan atau kandungan berikut yang boleh disimpulkan daripada teks sebelumnya. Token ini sebenarnya digunakan terutamanya untuk melatih keupayaan teks biasa VLM.
Teks yang bercanggah dengan kandungan imej
: Token ini tidak konsisten dengan maklumat imej malah mungkin memberikan maklumat yang mengelirukan, menjejaskan proses penjajaran pelbagai mod secara negatif. -
标 Rajah 1: Tanda hijau berkaitan dengan Token berkaitan tinggi, merah adalah bertentangan dengan kandungan, dan tidak berwarna ialah Token neutral Semasa proses latihan, dua jenis terakhir token sebenarnya sebenarnya menduduki bahagian yang lebih besar, tetapi kerana ia tidak terlalu bergantung pada imej, ia mempunyai sedikit kesan pada penjajaran modal imej. Oleh itu, untuk mencapai penjajaran yang lebih baik, adalah perlu untuk meningkatkan berat jenis pertama token teks, iaitu, token yang sangat berkaitan dengan imej. Bagaimana untuk mencari bahagian token ini telah menjadi kunci untuk menyelesaikan masalah ini. KaedahMencari token yang sangat berkaitan dengan imej Masalah ini boleh diselesaikan dengan kontrastif keadaan.
Untuk setiap pasangan imej-teks dalam data latihan, jika tiada input imej, logit pada setiap token teks mewakili anggaran LLM tentang kejadian situasi ini berdasarkan konteks dan nilai pengetahuan sedia ada.
- Jika anda menambah input imej di hadapan, ia sama dengan memberikan maklumat kontekstual tambahan Dalam kes ini, logit setiap token teks akan dilaraskan berdasarkan situasi baharu. Perubahan logit dalam kedua-dua kes ini mewakili kesan keadaan baharu gambar pada setiap token teks.
Secara khusus, semasa proses latihan, CAL memasukkan urutan imej dan teks dan urutan teks individu ke dalam model bahasa besar (LLM) masing-masing untuk mendapatkan logit setiap token teks. Dengan mengira perbezaan logit antara kedua-dua kes, kita boleh mengukur kesan imej pada setiap token. Lebih besar perbezaan logit, lebih besar kesan imej pada token, jadi token lebih relevan dengan imej. Rajah di bawah menunjukkan carta alir kaedah perbezaan logit dan CAL untuk token teks.对 Rajah 2: Gambar kiri ialah visualisasi token logit diff dalam dua situasi Gambar di sebelah kanan ialah visualisasi proses kaedah CAL
 Cal dalam Llava Pengesahan eksperimen dijalankan pada dua. model arus perdana: MGM dan MGM, dan peningkatan prestasi dicapai dalam model saiz yang berbeza. Mengandungi empat bahagian pengesahan berikut: (1) Model menggunakan CAL berprestasi lebih baik pada pelbagai penunjuk penanda aras. (2) Cipta kumpulan data hingar (imej-teks tidak padan) dengan menukar teks secara rawak dalam dua pasangan teks imej dalam perkadaran, dan gunakannya untuk latihan model membuat proses latihan Mempunyai prestasi anti-bunyi data yang lebih kukuh.度 Rajah 3: Dalam kes latihan hingar pada intensiti yang berbeza, prestasi CAL dan garis dasar (3) mengira skor perhatian token gambar dalam bahagian jawapan Kes QA, Dan memplotkannya pada imej asal, model terlatih CAL mempunyai peta pengedaran perhatian yang lebih jelas. C Rajah 4: Garis dasar dan Peta Perhatian CAL boleh digambarkan Bahagian kanan setiap pasangan ialah CAL (4) kepada token teks kepada token teks dalam perbendaharaan kata LLM yang paling serupa imej asal, kandungan pemetaan model yang dilatih oleh CAL lebih dekat dengan kandungan imej. ByteDance Beanbag Pasukan model telah ditubuhkan pada 2023 dan komited untuk membangunkan teknologi model besar AI yang paling maju dalam industri, menjadi pasukan penyelidikan bertaraf dunia, dan menyumbang kepada pembangunan teknologi dan sosial. Pasukan Doubao Big Model mempunyai visi dan keazaman jangka panjang dalam bidang AI Arah penyelidikannya meliputi NLP, CV, ucapan, dsb., dan ia mempunyai makmal dan jawatan penyelidikan di China. Singapura, Amerika Syarikat dan tempat-tempat lain. Bergantung pada data yang mencukupi, pengkomputeran dan sumber lain, pasukan itu terus melabur dalam bidang berkaitan yang telah melancarkan model besar umum yang dibangunkan sendiri untuk menyediakan keupayaan berbilang modal. dan Jimeng, dan terbuka kepada orang ramai melalui pelanggan Korporat. Pada masa ini, Doubao APP telah menjadi aplikasi AIGC dengan bilangan pengguna terbesar di pasaran China. Selamat datang untuk menyertai pasukan model ByteDance Beanbao.
Cal dalam Llava Pengesahan eksperimen dijalankan pada dua. model arus perdana: MGM dan MGM, dan peningkatan prestasi dicapai dalam model saiz yang berbeza. Mengandungi empat bahagian pengesahan berikut: (1) Model menggunakan CAL berprestasi lebih baik pada pelbagai penunjuk penanda aras. (2) Cipta kumpulan data hingar (imej-teks tidak padan) dengan menukar teks secara rawak dalam dua pasangan teks imej dalam perkadaran, dan gunakannya untuk latihan model membuat proses latihan Mempunyai prestasi anti-bunyi data yang lebih kukuh.度 Rajah 3: Dalam kes latihan hingar pada intensiti yang berbeza, prestasi CAL dan garis dasar (3) mengira skor perhatian token gambar dalam bahagian jawapan Kes QA, Dan memplotkannya pada imej asal, model terlatih CAL mempunyai peta pengedaran perhatian yang lebih jelas. C Rajah 4: Garis dasar dan Peta Perhatian CAL boleh digambarkan Bahagian kanan setiap pasangan ialah CAL (4) kepada token teks kepada token teks dalam perbendaharaan kata LLM yang paling serupa imej asal, kandungan pemetaan model yang dilatih oleh CAL lebih dekat dengan kandungan imej. ByteDance Beanbag Pasukan model telah ditubuhkan pada 2023 dan komited untuk membangunkan teknologi model besar AI yang paling maju dalam industri, menjadi pasukan penyelidikan bertaraf dunia, dan menyumbang kepada pembangunan teknologi dan sosial. Pasukan Doubao Big Model mempunyai visi dan keazaman jangka panjang dalam bidang AI Arah penyelidikannya meliputi NLP, CV, ucapan, dsb., dan ia mempunyai makmal dan jawatan penyelidikan di China. Singapura, Amerika Syarikat dan tempat-tempat lain. Bergantung pada data yang mencukupi, pengkomputeran dan sumber lain, pasukan itu terus melabur dalam bidang berkaitan yang telah melancarkan model besar umum yang dibangunkan sendiri untuk menyediakan keupayaan berbilang modal. dan Jimeng, dan terbuka kepada orang ramai melalui pelanggan Korporat. Pada masa ini, Doubao APP telah menjadi aplikasi AIGC dengan bilangan pengguna terbesar di pasaran China. Selamat datang untuk menyertai pasukan model ByteDance Beanbao.
Atas ialah kandungan terperinci Bytedance Doubao dan Universiti Wuhan mencadangkan CAL: meningkatkan kesan penjajaran pelbagai mod melalui token berkaitan visual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




 Cal dalam Llava Pengesahan eksperimen dijalankan pada dua. model arus perdana: MGM dan MGM, dan peningkatan prestasi dicapai dalam model saiz yang berbeza.
Cal dalam Llava Pengesahan eksperimen dijalankan pada dua. model arus perdana: MGM dan MGM, dan peningkatan prestasi dicapai dalam model saiz yang berbeza. 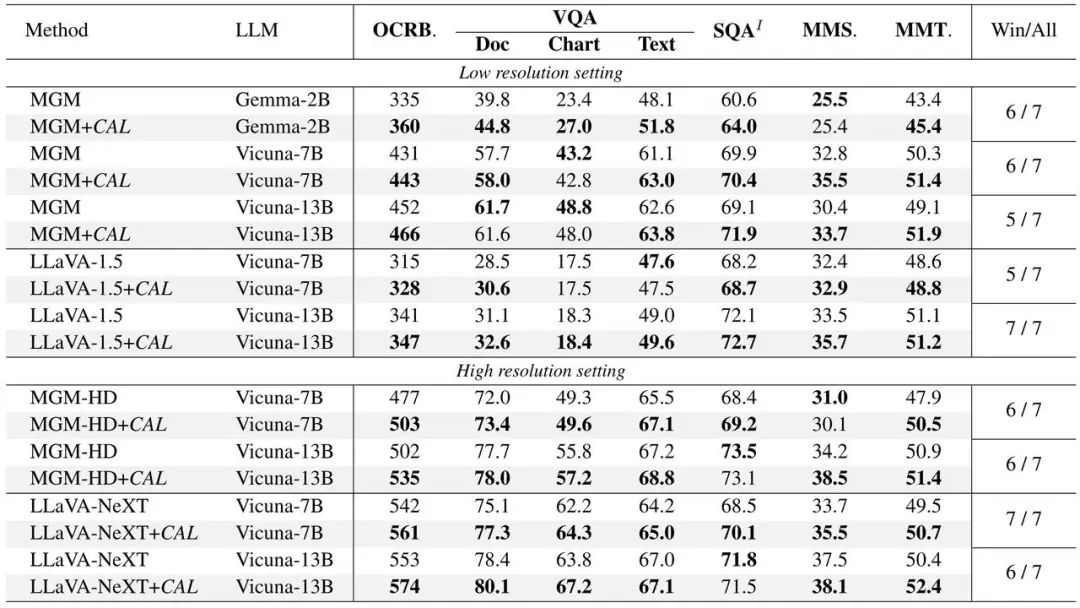

 Bagaimana untuk mengeksport Apipost di luar talian
Bagaimana untuk mengeksport Apipost di luar talian
 animasi jquery
animasi jquery
 Bagaimana untuk memulakan semula dengan kerap
Bagaimana untuk memulakan semula dengan kerap
 Apakah teg artikel yang digunakan untuk menentukan?
Apakah teg artikel yang digunakan untuk menentukan?
 Bagaimana untuk memanggil js luaran dalam html
Bagaimana untuk memanggil js luaran dalam html
 Bagaimana untuk mencari pembahagi sepunya terbesar dalam bahasa C
Bagaimana untuk mencari pembahagi sepunya terbesar dalam bahasa C
 Pengenalan kepada penggunaan fungsi paksi dalam Matlab
Pengenalan kepada penggunaan fungsi paksi dalam Matlab
 Apakah perisian untuk belajar python?
Apakah perisian untuk belajar python?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



