Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Kajian ini menilai pembelajaran konteks berbilang sampel bagi model asas pelbagai mod lanjutan pada 10 set data, mendedahkan peningkatan prestasi yang berterusan. Pertanyaan kelompok dengan ketara mengurangkan kependaman setiap contoh dan kos inferens tanpa mengorbankan prestasi. Penemuan ini menunjukkan bahawa: Memanfaatkan set besar contoh demo membolehkan penyesuaian pantas kepada tugasan dan domain baharu tanpa penalaan halus tradisional. 
- Alamat kertas: https://arxiv.org/abs/2405.09798
- Alamat kod: https://github.com/stanfordmlgroup/ManyICL
Pengenalan latar belakang Dalam penyelidikan terkini mengenai Model Asas Multimodal, Pembelajaran Dalam Konteks (ICL) telah terbukti sebagai salah satu kaedah yang berkesan untuk meningkatkan prestasi model.
Walau bagaimanapun, terhad oleh panjang konteks model asas, terutamanya untuk model asas berbilang modal yang memerlukan sejumlah besar token visual untuk mewakili imej, penyelidikan berkaitan sedia ada hanya terhad untuk menyediakan sebilangan kecil sampel dalam konteksnya.
Menariknya, kemajuan teknologi terkini telah meningkatkan panjang konteks model dengan banyak, yang membuka kemungkinan meneroka pembelajaran konteks menggunakan lebih banyak contoh.
Berdasarkan ini, penyelidikan terkini pasukan Stanford Ng - ManyICL, terutamanya menilai model asas pelbagai mod terkini dalam pembelajaran konteks daripada beberapa sampel (kurang daripada 100) kepada pelbagai sampel (sehingga 2000) Prestasi dalam . Dengan menguji set data daripada berbilang domain dan tugasan, pasukan itu mengesahkan kesan ketara pembelajaran konteks berbilang sampel dalam meningkatkan prestasi model dan meneroka kesan pertanyaan kelompok terhadap prestasi, kos dan kependaman.
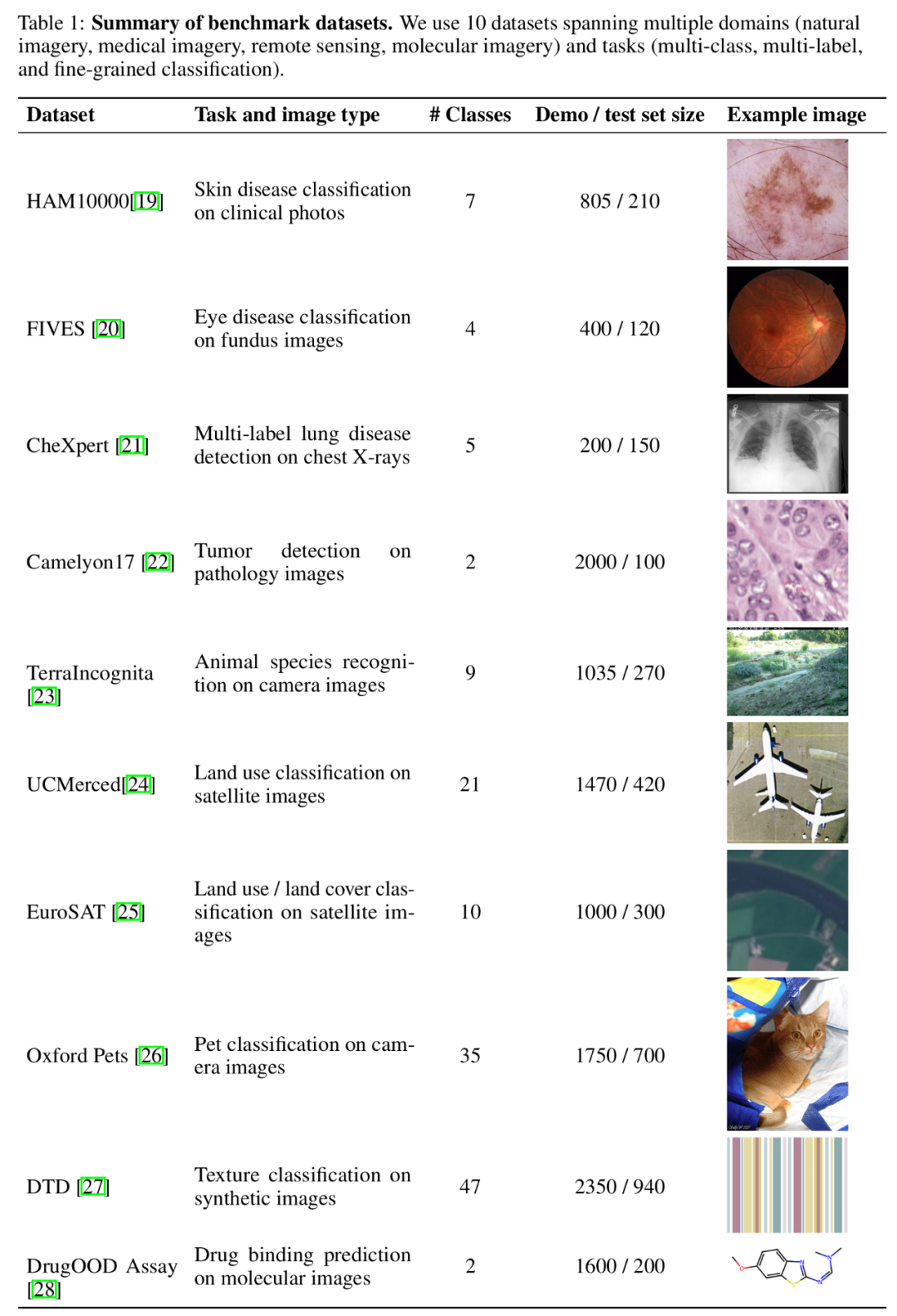
Perbandingan ICL banyak pukulan dan sampel sifar, beberapa sampel ICL. Tinjauan Keseluruhan KaedahTiga model asas pelbagai mod termaju telah dipilih untuk kajian ini: GPT-4o, GPT5 (V)-1.Turbo Pro Gemini. Disebabkan oleh prestasi unggul GPT-4o, pasukan penyelidik menumpukan pada GPT-4o dan Gemini 1.5 Pro dalam teks utama Sila lihat kandungan GPT4 (V)-Turbo yang berkaitan dalam lampiran. Dari segi set data, pasukan penyelidik menjalankan penyelidikan ke atas 10 set data yang merangkumi bidang yang berbeza (termasuk imej semula jadi, imej perubatan, imej penderiaan jauh dan pengimejan molekul, dsb.) dan tugasan (termasuk berbilang klasifikasi, klasifikasi berbilang label dan pengelasan berbutir halus) Eksperimen yang meluas.
Ringkasan set data penanda aras.
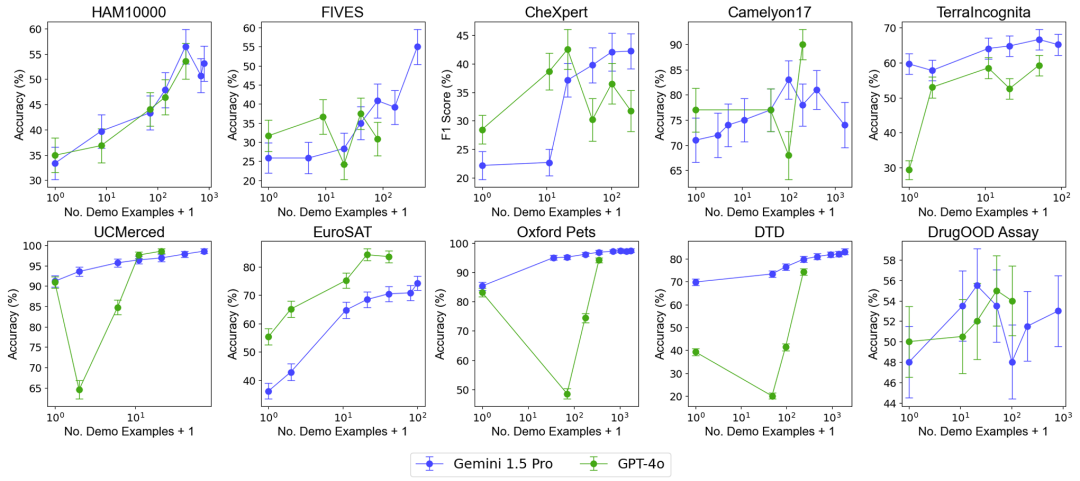
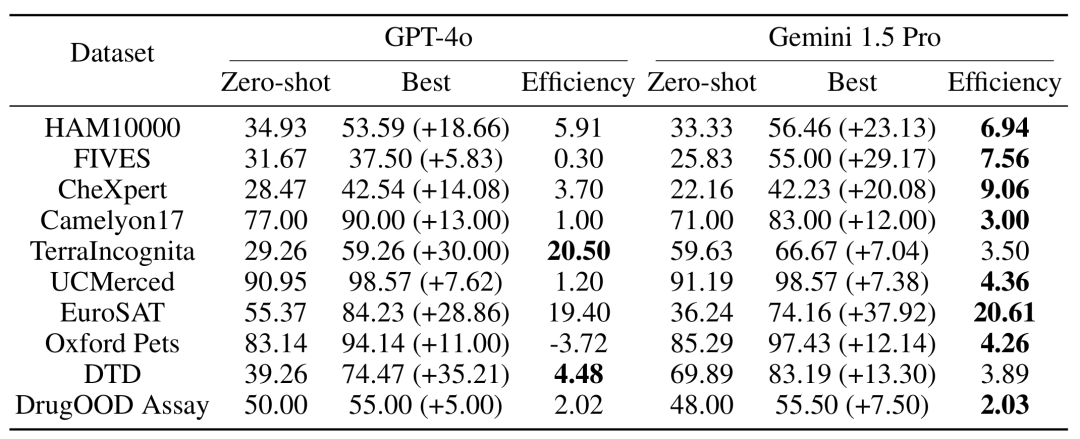
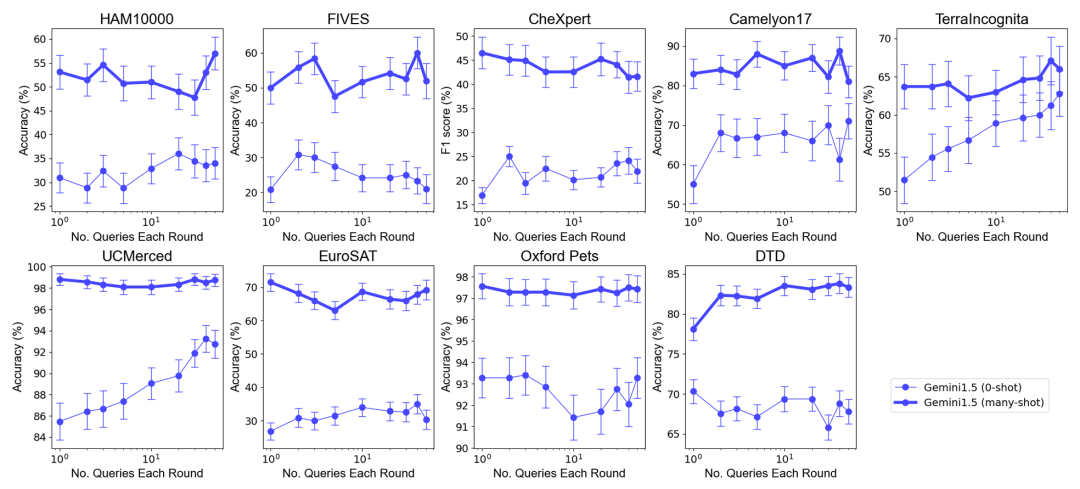
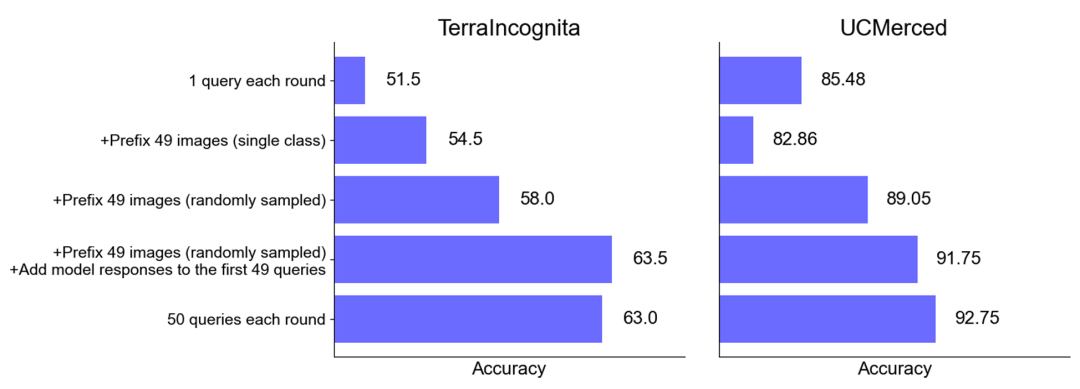
Untuk menguji kesan peningkatan bilangan contoh pada prestasi model, pasukan penyelidik secara beransur-ansur meningkatkan bilangan contoh yang disediakan dalam konteks, sehingga hampir 2,000 contoh. Pada masa yang sama, memandangkan kos tinggi dan kependaman tinggi pembelajaran berbilang sampel, pasukan penyelidik juga meneroka kesan pemprosesan kelompok pertanyaan. Di sini, pertanyaan kelompok merujuk kepada memproses berbilang pertanyaan dalam satu panggilan API. Hasil EksperimenMulti-sampel Konteks Konteks Pembelajaran Prestasi Performance : Pembelajaran konteks berbilang sampel dengan hampir 2000 contoh mengatasi prestasi pada semua dataset pembelajaran beberapa tembakan . Prestasi model Gemini 1.5 Pro menunjukkan peningkatan log-linear yang konsisten apabila bilangan contoh meningkat, manakala prestasi GPT-4o kurang stabil. Kecekapan data: Kajian mengukur kecekapan data pembelajaran kontekstual model, iaitu seberapa cepat model belajar daripada contoh. Keputusan menunjukkan bahawa Gemini 1.5 Pro menunjukkan kecekapan data pembelajaran konteks yang lebih tinggi daripada GPT-4o pada kebanyakan set data, bermakna ia boleh belajar daripada contoh dengan lebih berkesan. Impak pertanyaan kelompok Perlu diingat bahawa dalam senario sifar pukulan, satu pertanyaan berprestasi buruk pada banyak set data. Sebaliknya, pertanyaan kelompok malah boleh meningkatkan prestasi.
Peningkatan prestasi dalam senario sampel sifar: Untuk sesetengah set data (seperti UCMerced), pertanyaan kelompok meningkatkan prestasi dalam senario sampel sifar dengan ketara. Pasukan penyelidik menganalisis bahawa ini adalah terutamanya disebabkan oleh penentukuran domain, penentukuran kelas dan pembelajaran kendiri (self-ICL).
Analisis Kos dan Kependaman Pembelajaran konteks berbilang sampel Walaupun konteks input yang lebih panjang perlu diproses semasa inferens, kependaman dan kos inferens bagi setiap contoh boleh dikurangkan dengan ketara mengikut kelompok pertanyaan. Sebagai contoh, pada set data HAM10000, menggunakan model Gemini 1.5 Pro untuk pertanyaan kelompok sebanyak 350 contoh, kependaman menurun daripada 17.3 saat kepada 0.54 saat dan kos menurun daripada $0.842 kepada $0.0877 setiap contoh.
Kesimpulan
Hasil penyelidikan menunjukkan bahawa pembelajaran konteks berbilang sampel boleh meningkatkan prestasi model asas pelbagai modal dengan ketara, terutamanya model Gemini 1.5 Pro menunjukkan peningkatan prestasi berterusan pada pelbagai set data, membolehkannya menyesuaikan diri dengan lebih berkesan kepada tugasan dan domain baharu tanpa memerlukan penalaan halus tradisional.
Kedua, pemprosesan kelompok pertanyaan boleh mengurangkan kos inferens dan kependaman sambil mencapai prestasi model yang serupa atau lebih baik, menunjukkan potensi besar dalam aplikasi praktikal.
Secara amnya, penyelidikan oleh pasukan Andrew Ng ini membuka laluan baharu untuk penerapan model asas pelbagai mod, terutamanya dari segi penyesuaian pantas kepada tugas dan bidang baharu.
Atas ialah kandungan terperinci Kerja baharu oleh pasukan Andrew Ng: pembelajaran konteks berbilang modal dan berbilang sampel, cepat menyesuaikan diri dengan tugas baharu tanpa penalaan halus.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





 Hasil penyelidikan menunjukkan bahawa pembelajaran konteks berbilang sampel boleh meningkatkan prestasi model asas pelbagai modal dengan ketara, terutamanya model Gemini 1.5 Pro menunjukkan peningkatan prestasi berterusan pada pelbagai set data, membolehkannya menyesuaikan diri dengan lebih berkesan kepada tugasan dan domain baharu tanpa memerlukan penalaan halus tradisional.
Hasil penyelidikan menunjukkan bahawa pembelajaran konteks berbilang sampel boleh meningkatkan prestasi model asas pelbagai modal dengan ketara, terutamanya model Gemini 1.5 Pro menunjukkan peningkatan prestasi berterusan pada pelbagai set data, membolehkannya menyesuaikan diri dengan lebih berkesan kepada tugasan dan domain baharu tanpa memerlukan penalaan halus tradisional.  vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan
vcruntime140.dll tidak dapat ditemui dan pelaksanaan kod tidak dapat diteruskan
 kekunci pintasan pr
kekunci pintasan pr
 Bagaimana untuk berpakaian Douyin Xiaohuoren
Bagaimana untuk berpakaian Douyin Xiaohuoren
 Apakah maksud perisikan data?
Apakah maksud perisikan data?
 penggunaan nod induk
penggunaan nod induk
 Bagaimana untuk membaca data dalam fail excel dalam python
Bagaimana untuk membaca data dalam fail excel dalam python
 Apa yang perlu dilakukan jika komputer memalsukan kematian
Apa yang perlu dilakukan jika komputer memalsukan kematian
 Apa yang perlu dilakukan jika css tidak boleh dimuatkan
Apa yang perlu dilakukan jika css tidak boleh dimuatkan
 Apakah perbezaan antara JD International dikendalikan sendiri dan JD dikendalikan sendiri
Apakah perbezaan antara JD International dikendalikan sendiri dan JD dikendalikan sendiri











![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



