Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pengarang artikel ini, Xiao Zhenzhong, ialah pelajar kedoktoran di Institut Max Planck untuk Sistem Pintar dan Universiti Tübingen di Jerman, dan Robert Bamler ialah pelajar PhD di Universiti Tübingen Profesor pembelajaran mesin di universiti itu, Bernhard Schölkopf ialah pengarah Institut Max Planck untuk Sistem Pintar, dan Liu Weiyang ialah penyelidik dalam Projek Bersama Institut Max Planck Cambridge.

Alamat kertas: https://arxiv.org/abs/2406.04344Dalam senario pembelajaran mesin tradisional seperti masalah klasifikasi dan regresi, berdasarkan data latihan, kami mempelajari model fungsi dengan mengoptimumkan parameter dengan tepat hubungan antara dan dalam set latihan dan set ujian. Antaranya, ialah fungsi berdasarkan nilai berangka biasanya adalah vektor berangka atau matriks dalam ruang berterusan Algoritma pengoptimuman mengemas kini secara berulang dengan mengira kecerunan berangka untuk mencapai kesan pembelajaran. Daripada menggunakan nilai berangka, bolehkah kita menggunakan bahasa semula jadi untuk mewakili model? Bagaimana untuk melaksanakan inferens dan latihan pada model bukan berangka ini berdasarkan bahasa semula jadi? Verbalized Machine Learning (VML; Verbalized Machine Learning) menjawab soalan ini dan mencadangkan paradigma baharu pembelajaran mesin berdasarkan bahasa semula jadi. VML menganggap model bahasa besar (LLM) sebagai penghampir fungsi universal dalam ruang bahasa semula jadi, dan data serta parameter kedua-duanya adalah rentetan dalam ruang bahasa semula jadi. Apabila membuat inferens, kita boleh menyerahkan data input dan parameter yang diberikan kepada LLM, dan jawapan LLM ialah jawapan kepada inferens .Untuk tugasan dan data sewenang-wenangnya , bagaimana kita boleh mendapatkan ? Dalam pembelajaran mesin tradisional berdasarkan nilai berangka, kami mengemas kini parameter model sedia ada ke arah pengurangan kerugian dengan mengira kecerunan fungsi kehilangan, dengan itu memperoleh fungsi pengoptimuman :
di mana dan ialah kadar pembelajaran dan fungsi kerugian masing-masing. Dalam tetapan VML, memandangkan data dan parameter adalah kedua-dua rentetan dan LLM dianggap sebagai enjin inferens kotak hitam, kami tidak boleh mengoptimumkan melalui pengiraan berangka. Tetapi memandangkan kami telah menggunakan LLM sebagai fungsi penghampiran umum dalam ruang bahasa semula jadi untuk menganggarkan fungsi model, dan pengoptimum juga merupakan fungsi, mengapa kita tidak juga menggunakan LLM untuk menganggarkannya? Oleh itu, fungsi pengoptimuman lisan boleh ditulis sebagai
, di mana
ialah data latihan dan hasil ramalan model bagi kumpulan , dan ialah parameter fungsi pengoptimuman (sama seperti bahasa semula jadi). Rajah 1: Algoritma latihan VML. 中 Rajah 2: Contoh contoh templat bahasa semula jadi bagi model dan pengoptimum dalam VML. Rajah 1 menunjukkan algoritma lengkap VML. Ia boleh dilihat bahawa ia pada asasnya sama dengan algoritma pembelajaran mesin tradisional Satu-satunya perbezaan ialah data dan parameter adalah rentetan dalam ruang bahasa semula jadi, dan model
dan pengoptimum kedua-duanya melakukan inferens dalam ruang bahasa semula jadi. LLM. Rajah 2 menunjukkan contoh templat khusus model dan pengoptimum dalam tugas regresi. Berbanding dengan pembelajaran mesin tradisional, kelebihan VML termasuk: (1) Anda boleh menambah bias induktif pada model dengan penerangan ringkas dalam bahasa semula jadi (2) Memandangkan tidak perlu menetapkan keluarga fungsi model (keluarga fungsi), pengoptimum
secara automatik boleh memilih keluarga fungsi model semasa proses latihan; model juga bahasa semula jadi dan boleh dijelaskan.
Polynomial Regresi yang ditunjukkan dalam Rajah 3, parameter awal model adalah definisi regresi linear. Semasa langkah pertama pengoptimuman, pengoptimum mengatakan bahawa ia mendapati bahawa mempunyai julat nilai yang lebih besar daripada , dan ia kelihatan berkorelasi secara positif, jadi ia memutuskan untuk mengemas kini model kepada model regresi linear mudah.Dalam langkah kedua pengoptimuman, pengoptimum mengatakan bahawa prestasi lemah model semasa menyedarkan bahawa andaian model linear adalah terlalu mudah, dan mendapati terdapat hubungan bukan linear antara dan , jadi ia memutuskan untuk menukar model Dikemas kini kepada fungsi kuadratik. Dalam langkah pengoptimuman ketiga, tumpuan pengoptimum beralih daripada pemilihan keluarga fungsi kepada pengubahsuaian parameter fungsi kuadratik. Model akhir mempelajari hasil yang sangat hampir dengan fungsi sebenar.在 Rajah 3: Rekod proses latihan VML dalam misi regresi berbilang belah. . ayat "sempadan keputusan" digunakan Ia adalah bulatan" dan menambah bias induktif. Dalam langkah pertama pengoptimuman, pengoptimum mengatakan ia mengemas kini model kepada persamaan bulatan berdasarkan yang diberikan sebelumnya. Dalam langkah pengoptimuman seterusnya, pengoptimum melaraskan pusat dan jejari persamaan bulatan berdasarkan data latihan. Sehingga langkah 41, pengoptimum mengatakan bahawa model semasa kelihatan sesuai, jadi ia berhenti mengemas kini model.
Pada masa yang sama, kita juga dapat melihat bahawa VML juga boleh mempelajari model yang baik berdasarkan pepohon keputusan tanpa menambah berat sebelah induktif, tetapi kehilangan latihan lebih turun naik berbanding perbandingan. e 4: Rekod proses latihan VML dalam tugas pengelasan satah dua dimensi tak linear. Klasifikasi binari imej perubatanJika model besar menerima input berbilang modal, seperti gambar dan teks, maka VML juga boleh digunakan untuk tugasan imej. Dalam percubaan ini, kami menggunakan set data GPT-4o dan PneumoniaMNIST untuk melaksanakan tugas pengesanan radang paru-paru sinar-X. Seperti yang ditunjukkan dalam Rajah 5, kami memulakan dua model Parameter awal model kedua-duanya ditakrifkan sebagai klasifikasi kedua imej, tetapi salah satu daripadanya menambah ayat "Input ialah imej sinar-X yang digunakan. untuk pengesanan radang paru-paru." bias induktif sebagai priori. Selepas lima puluh langkah latihan, kedua-dua model mencapai ketepatan kira-kira 75%, dengan model dengan sebelumnya adalah lebih tepat sedikit. Melihat dengan teliti pada parameter model selepas langkah 50, kita dapat melihat bahawa penerangan model dengan bias induktif mengandungi banyak perkataan perubatan yang berkaitan dengan radang paru-paru, seperti "jangkitan" dan "keradangan"; bias hanya menerangkan ciri-ciri sinar-X paru-paru, seperti "transparensi" dan "simetri". Pada masa yang sama, penerangan yang dipelajari oleh model ini boleh disahkan oleh doktor dengan pengetahuan profesional. Model pembelajaran mesin yang boleh ditafsir dan boleh disemak manusia adalah berharga dalam senario perubatan kritikal keselamatan.
Rajah 5: Rekod latihan VML mengenai klasifikasi binari imej PneumoniaMNIST. . dan kebolehtafsiran VML pada tugas pengelasan. Atas ialah kandungan terperinci Bolehkah pembelajaran mesin dilakukan semata-mata dengan bercakap tanpa melakukan pengiraan berangka? Paradigma ML baharu berdasarkan bahasa semula jadi akan datang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




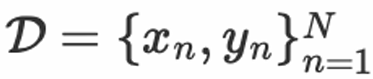 , kami mempelajari model fungsi
, kami mempelajari model fungsi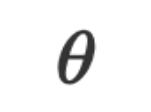 dengan mengoptimumkan parameter dengan tepat
dengan mengoptimumkan parameter dengan tepat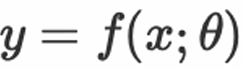 hubungan antara
hubungan antara 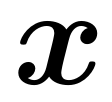 dan
dan 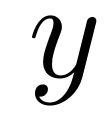 dalam set latihan dan set ujian. Antaranya,
dalam set latihan dan set ujian. Antaranya, 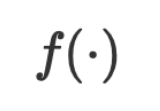 ialah fungsi berdasarkan nilai berangka
ialah fungsi berdasarkan nilai berangka  biasanya adalah vektor berangka atau matriks dalam ruang berterusan Algoritma pengoptimuman mengemas kini
biasanya adalah vektor berangka atau matriks dalam ruang berterusan Algoritma pengoptimuman mengemas kini  dalam ruang bahasa semula jadi, dan data
dalam ruang bahasa semula jadi, dan data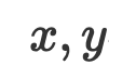 serta parameter
serta parameter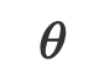 kedua-duanya adalah rentetan dalam ruang bahasa semula jadi. Apabila membuat inferens, kita boleh menyerahkan data input
kedua-duanya adalah rentetan dalam ruang bahasa semula jadi. Apabila membuat inferens, kita boleh menyerahkan data input 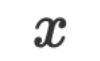 dan parameter
dan parameter  yang diberikan kepada LLM, dan jawapan LLM ialah jawapan kepada inferens
yang diberikan kepada LLM, dan jawapan LLM ialah jawapan kepada inferens 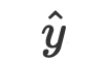 .
.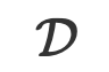 , bagaimana kita boleh mendapatkan
, bagaimana kita boleh mendapatkan 
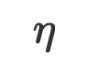 dan
dan 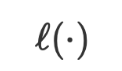 ialah kadar pembelajaran dan fungsi kerugian masing-masing.
ialah kadar pembelajaran dan fungsi kerugian masing-masing.  dan parameter
dan parameter 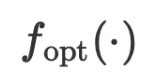 lisan boleh ditulis sebagai
lisan boleh ditulis sebagai 
 , dan
, dan 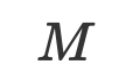 ialah parameter fungsi pengoptimuman (sama seperti bahasa semula jadi).
ialah parameter fungsi pengoptimuman (sama seperti bahasa semula jadi). 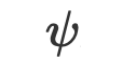
 Rajah 1: Algoritma latihan VML.
Rajah 1: Algoritma latihan VML.  dalam tugas regresi.
dalam tugas regresi. 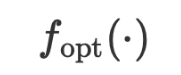


 dan
dan  , jadi ia memutuskan untuk menukar model Dikemas kini kepada fungsi kuadratik.
, jadi ia memutuskan untuk menukar model Dikemas kini kepada fungsi kuadratik. 
 kedua-duanya ditakrifkan sebagai klasifikasi kedua imej, tetapi salah satu daripadanya menambah ayat "Input ialah imej sinar-X yang digunakan. untuk pengesanan radang paru-paru." bias induktif sebagai priori. Selepas lima puluh langkah latihan, kedua-dua model mencapai ketepatan kira-kira 75%, dengan model dengan sebelumnya adalah lebih tepat sedikit.
kedua-duanya ditakrifkan sebagai klasifikasi kedua imej, tetapi salah satu daripadanya menambah ayat "Input ialah imej sinar-X yang digunakan. untuk pengesanan radang paru-paru." bias induktif sebagai priori. Selepas lima puluh langkah latihan, kedua-dua model mencapai ketepatan kira-kira 75%, dengan model dengan sebelumnya adalah lebih tepat sedikit. 
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



