Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pasukan penyelidik Makmal Kepintaran Buatan Generatif (GAIR Lab) Universiti Jiao Tong Shanghai, arahan latihan model besar ialah: , penjajaran dan Menilai. Laman utama pasukan: https://plms.ai/Teknologi AI berubah setiap hari Baru-baru ini, Claude-3.5-Sonnet terbaru yang dikeluarkan oleh Syarikat Anthropic telah digunakan secara meluas dalam pengetahuan-. penaakulan berasaskan, penaakulan matematik, tugas pengaturcaraan dan penaakulan visual Menetapkan penanda aras industri baharu pada tugas lain telah mencetuskan perbincangan meluas: Adakah Claude-3.5-Sonnet telah menggantikan GPT4o OpenAI sebagai "AI Paling Pintar" di dunia. Cabaran dalam menjawab soalan ini ialah kami pertama sekali memerlukan penanda aras ujian kecerdasan yang cukup mencabar yang membolehkan kami membezakan tahap tertinggi semasa AI. Arena Olimpik[1] (Arena Olimpik) yang dilancarkan oleh Makmal Kepintaran Buatan Generatif (GAIR Lab) Universiti Jiao Tong Shanghai memenuhi keperluan ini.
Pertandingan Mata Pelajaran Olimpik bukan sahaja cabaran yang melampau untuk ketangkasan berfikir manusia (kecerdasan berasaskan karbon), penguasaan pengetahuan dan penaakulan logik, ia juga merupakan tempat latihan yang sangat baik untuk AI ("kecerdasan berasaskan silikon" ). Kayu pengukur penting untuk mengukur jarak antara AI dan "kecerdasan super". OlympicArena - arena Olimpik AI sebenar. Di sini, AI bukan sahaja perlu menunjukkan kedalamannya dalam pengetahuan subjek tradisional (pertandingan teratas seperti matematik, fizik, biologi, kimia, geografi, dll.), tetapi juga bersaing dalam keupayaan penaakulan kognitif antara model.
Baru-baru ini, pasukan penyelidik yang sama mencadangkan buat kali pertama penggunaan kaedah "
Senarai Pingat Olimpik" untuk meletakkan kedudukan setiap model AI berdasarkan prestasi keseluruhannya di Arena Olimpik (pelbagai disiplin) dan pilih yang terbaik setakat ini AI yang paling pintar. Dalam arena ini, pasukan penyelidik menumpukan pada menganalisis dan membandingkan dua model termaju yang dikeluarkan baru-baru ini - Claude-3.5-Sonnet dan Gemini-1.5-Pro, serta siri GPT-4 OpenAI (mis., GPT4o ). Dengan cara ini, pasukan penyelidik berharap dapat menilai dan mempromosikan pembangunan teknologi AI dengan lebih berkesan. 
... sama, mereka diisih mengikut skor prestasi keseluruhan. Hasil eksperimen menunjukkan bahawa: Claude-3.5-Sonnet sangat kompetitif dengan GPT-4o dalam prestasi keseluruhan, malah melebihi 4 dalam prestasi keseluruhan dalam fizik, kimia dan biologi). Gemini-1.5-Pro dan GPT-4V berada di belakang GPT-4o dan Claude-3.5-Sonnet, tetapi terdapat jurang prestasi yang jelas di antara mereka.
-
Prestasi model AI daripada komuniti sumber terbuka jelas ketinggalan di belakang model proprietari ini.
-
Prestasi model-model ini yang tidak memuaskan pada penanda aras ini menunjukkan bahawa kita masih mempunyai perjalanan yang panjang untuk menuju ke superintelligence.
-
- Laman utama projek: https://gair-nlp.github.io/OlympicArena/
mengambil set ujian Olimpik. Jawapan kepada set ujian ini tidak didedahkan kepada umum untuk membantu mencegah kebocoran data dan dengan itu mencerminkan prestasi sebenar model. Pasukan penyelidik menguji model besar multimodal (LMM) dan model besar teks sahaja (LLM). Untuk ujian LLM, tiada maklumat berkaitan imej diberikan kepada model sebagai input, hanya teks. Semua penilaian menggunakan kata gesaan Rantaian Pemikiran pukulan sifar. Pasukan penyelidik menilai satu siri model besar multimodal sumber terbuka dan tertutup (LMM) dan model besar teks sahaja (LLM). Untuk LMM, model sumber tertutup seperti GPT-4o, GPT-4V, Claude-3-Sonnet, Gemini Pro Vision, Qwen-VL-Max, dsb. telah dipilih Selain itu, LLaVA-NeXT-34B, InternVL-Chat -V1.5 juga dinilai , Yi-VL-34B dan Qwen-VL-Chat dan model sumber terbuka yang lain. Untuk LLM, model sumber terbuka seperti Qwen-7B-Chat, Qwen1.5-32B-Chat, Yi-34B-Chat dan InternLM2-Chat-20B dinilai terutamanya. Selain itu, pasukan penyelidik secara khusus memasukkan Claude-3.5-Sonnet serta Gemini-1.5-Pro yang baru dikeluarkan dan membandingkannya dengan GPT-4o dan GPT-4V yang berkuasa. untuk mencerminkan prestasi model terkini.
Metrik Memandangkan semua masalah boleh dinilai dengan padanan berasaskan peraturan, pasukan penyelidik menggunakan ketepatan untuk tugasan bukan pengaturcaraan dan metrik pas@k yang tidak berat sebelah, untuk ditakrifkan sebagai metrik lulus@k yang tidak berat sebelah. berikut: Dalam penilaian ini, k = 1 dan n = 5 ditetapkan, dan c mewakili bilangan sampel yang betul yang melepasi semua kes ujian.
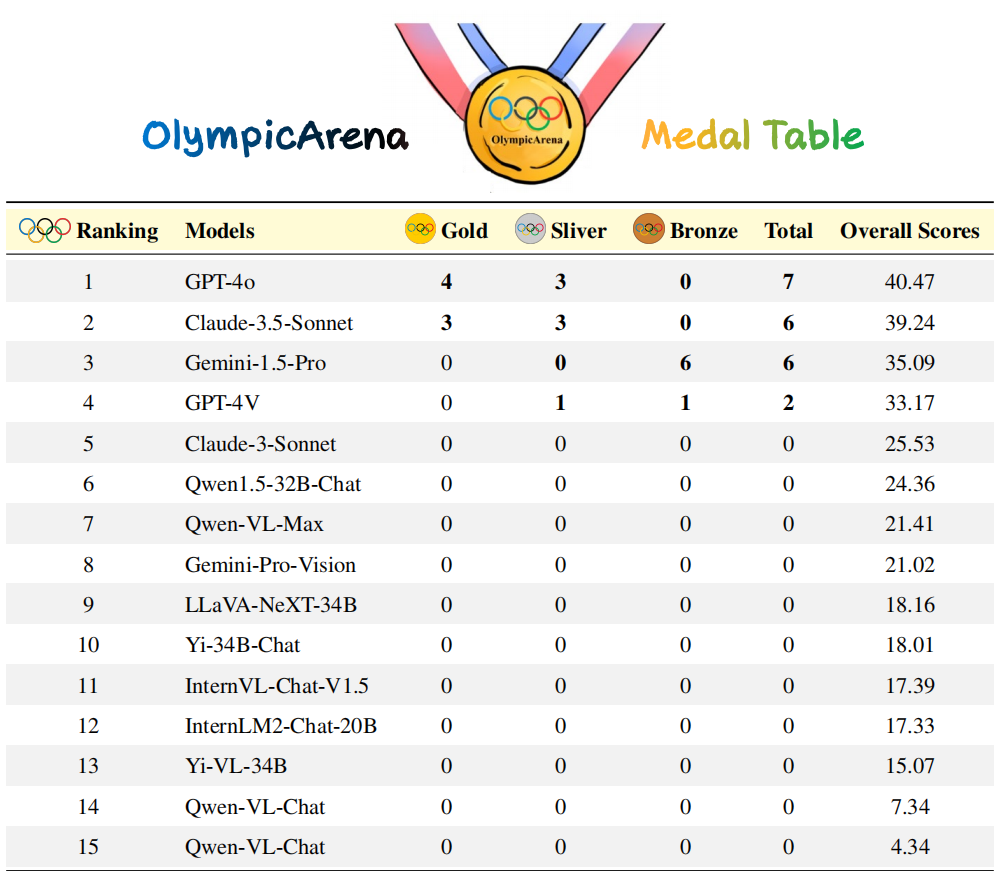
Senarai Pingat Arena Olimpik: Sama seperti sistem pingat yang digunakan dalam Sukan Olimpik, ia merupakan mekanisme ranking perintis yang direka khusus untuk menilai prestasi model AI dalam pelbagai bidang akademik. Jadual tersebut memberikan pingat kepada model yang mencapai keputusan tiga teratas dalam mana-mana disiplin, sekali gus menyediakan rangka kerja yang jelas dan kompetitif untuk membandingkan model yang berbeza. Pasukan penyelidik mula-mula menyusun model mengikut bilangan pingat emas Jika bilangan pingat emas adalah sama, ia disusun mengikut markah prestasi keseluruhan. Ia menyediakan cara yang intuitif dan ringkas untuk mengenal pasti model terkemuka dalam bidang akademik yang berbeza, menjadikannya lebih mudah untuk penyelidik dan pembangun memahami kekuatan dan kelemahan model yang berbeza. Penilaian terperinci: Pasukan penyelidik juga menjalankan penilaian terperinci berasaskan ketepatan berdasarkan disiplin yang berbeza, modaliti yang berbeza, bahasa yang berbeza dan jenis kebolehan penaakulan logik dan visual yang berbeza. Kandungan analisis tertumpu terutamanya pada Claude-3.5-Sonnet dan GPT-4o, dan juga sebahagiannya membincangkan prestasi Gemini-1.5-Pro. Keadaan keseluruhan
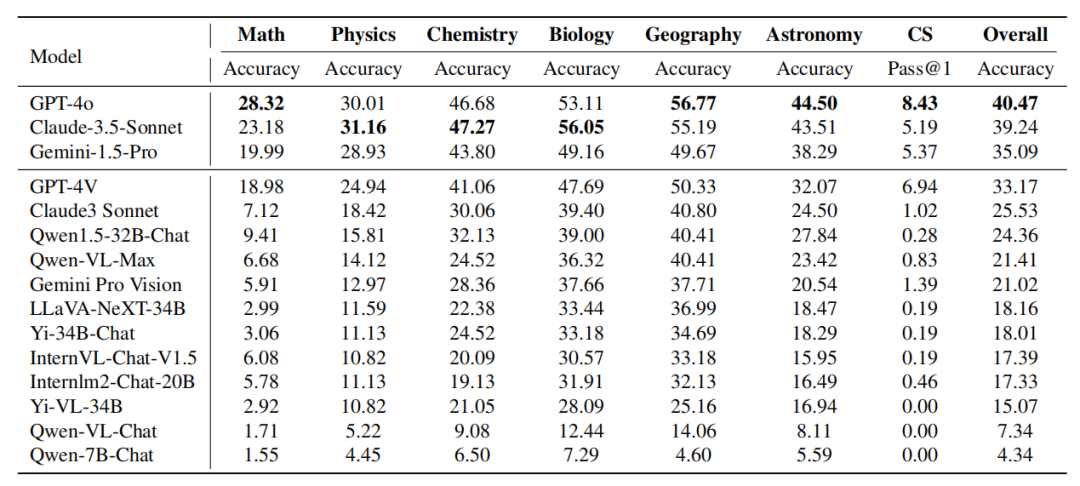
🎜🎜🎜🎜Jadual: Prestasi model pada subjek berbeza Prestasi Claude-3.5-Sonnet adalah berkuasa dan mencapai hampir Setanding dengan GPT-4o. Perbezaan ketepatan keseluruhan antara kedua-duanya hanya kira-kira 1%. Gemini-1.5-Pro yang baru dikeluarkan juga telah menunjukkan kekuatan yang cukup besar, mengatasi prestasi GPT-4V (model kedua paling berkuasa semasa OpenAI) dalam kebanyakan disiplin.
Perlu diingat bahawa pada masa penulisan ini, yang paling awal daripada ketiga-tiga model ini dikeluarkan hanya sebulan yang lalu, mencerminkan perkembangan pesat dalam bidang ini.
- Analisis terperinci untuk disiplin
GPT-4o lwn. Claude-3.5-Sonnet: 🜎 PT-4o dan Claude-3 5-Sonnet secara keseluruhan Prestasi adalah serupa, tetapi kedua-dua model mempamerkan kelebihan subjek yang berbeza. GPT-4o menunjukkan keupayaan unggul dalam tugas penaakulan deduktif dan induktif tradisional, terutamanya dalam matematik dan sains komputer. Claude-3.5-Sonnet berprestasi baik dalam mata pelajaran seperti fizik, kimia dan biologi, terutamanya dalam biologi, di mana ia melebihi GPT-4o sebanyak 3%.
GPT-4V lwn Gemini-1.5-Pro:
Fenomena serupa boleh diperhatikan dalam perbandingan Gemini-1.5-Pro vs. Gemini-1.5-Pro dengan ketara mengatasi prestasi GPT-4V dalam fizik, kimia dan biologi. Walau bagaimanapun, dari segi matematik dan sains komputer, kelebihan Gemini-1.5-Pro tidak jelas malah lebih rendah daripada GPT-4V. Daripada dua set perbandingan ini, dapat dilihat bahawa: Siri GPT OpenAI berprestasi cemerlang dalam penaakulan matematik tradisional dan keupayaan pengaturcaraan. Ini menunjukkan bahawa model siri GPT telah dilatih dengan teliti untuk mengendalikan tugas yang memerlukan banyak penaakulan deduktif dan pemikiran algoritma. Sebaliknya, model lain seperti Claude-3.5-Sonnet dan Gemini-1.5-Pro menunjukkan prestasi kompetitif apabila melibatkan subjek yang memerlukan penggabungan pengetahuan dengan penaakulan, seperti fizik, kimia dan biologi. Ini mencerminkan bidang kepakaran model yang berbeza dan tumpuan latihan yang berpotensi, menunjukkan kemungkinan pertukaran antara tugas intensif penaakulan dan tugas penyepaduan pengetahuan. Analisis terperinci jenis penaakulanKapsyen: Prestasi setiap model dalam keupayaan penaakulan logik. Kebolehan penaakulan logik termasuk: penaakulan deduktif (DED), penaakulan induktif (IND), penaakulan abduktif (ABD), penaakulan analogi (ANA), penaakulan kausal (CAE), pemikiran kritis (CT), penaakulan penguraian (DEC) dan Penaakulan kuantitatif ( QUA). . dalam kebanyakan keupayaan penaakulan logik Lebih baik daripada Claude-3.5-Sonnet dalam bidang seperti penaakulan deduktif, penaakulan induktif, penaakulan abduktif, penaakulan analogi dan pemikiran kritis. Walau bagaimanapun, Claude-3.5-Sonnet mengatasi GPT-4o dalam penaakulan kausal, penaakulan penguraian dan penaakulan kuantitatif. Secara keseluruhan, prestasi kedua-dua model adalah setanding, walaupun GPT-4o mempunyai sedikit kelebihan dalam kebanyakan kategori. -
Jadual: Prestasi setiap model dalam keupayaan penaakulan visual. Kebolehan penaakulan visual termasuk: pengecaman corak (PR), penaakulan spatial (SPA), penaakulan diagram (DIA), tafsiran simbolik (SYB), dan perbandingan visual (COM). . pengecaman corak dan Peneraju dalam penaakulan rajah, menunjukkan daya saingnya dalam pengecaman corak dan tafsiran rajah. Kedua-dua model menunjukkan prestasi yang sama pada tafsiran simbol, menunjukkan bahawa mereka mempunyai kebolehan yang setanding dalam memahami dan memproses maklumat simbolik. Walau bagaimanapun, GPT-4o mengatasi Claude-3.5-Sonnet dalam penaakulan spatial dan perbandingan visual, menunjukkan keunggulannya pada tugas yang memerlukan pemahaman perhubungan spatial dan membandingkan data visual.
Analisis komprehensif disiplin dan jenis penaakulan, pasukan penyelidik mendapati bahawa:
Matematik dan pengaturcaraan komputer menekankan kemahiran penaakulan deduktif kompleks dan derivasi berasaskan peraturan yang kurang Pengetahuan sedia ada. Sebaliknya, disiplin seperti kimia dan biologi sering memerlukan asas pengetahuan yang besar untuk menaakul berdasarkan maklumat yang diketahui tentang hubungan sebab akibat dan fenomena. Ini menunjukkan bahawa walaupun kebolehan matematik dan pengaturcaraan masih merupakan penunjuk yang sah bagi keupayaan penaakulan model, disiplin lain lebih baik menguji keupayaan model untuk menaakul dan menganalisis masalah berdasarkan pengetahuan dalamannya. Ciri-ciri disiplin yang berbeza menunjukkan kepentingan set data latihan yang disesuaikan. Sebagai contoh, untuk meningkatkan prestasi model dalam mata pelajaran intensif pengetahuan seperti kimia dan biologi, model memerlukan pendedahan yang meluas kepada data khusus domain semasa latihan. Sebaliknya, bagi subjek yang memerlukan logik yang kuat dan penaakulan deduktif, seperti matematik dan sains komputer, model boleh mendapat manfaat daripada latihan yang tertumpu pada penaakulan logik semata-mata.
Tambahan pula, perbezaan antara keupayaan penaakulan dan aplikasi pengetahuan menunjukkan potensi model untuk aplikasi merentas disiplin. Contohnya, model dengan keupayaan penaakulan deduktif yang kuat boleh membantu bidang yang memerlukan pemikiran sistematik untuk menyelesaikan masalah, seperti penyelidikan saintifik. Dan model yang kaya dengan pengetahuan adalah berharga dalam disiplin yang sangat bergantung pada maklumat sedia ada, seperti perubatan dan sains alam sekitar. Memahami nuansa ini membantu membangunkan model yang lebih khusus dan serba boleh.
Analisis jenis bahasa yang terperinci
- Kapsyen: Prestasi setiap model
Jadual di atas menunjukkan prestasi model dalam bahasa yang berbeza. Pasukan penyelidik mendapati bahawa kebanyakan model adalah lebih tepat dalam bahasa Inggeris berbanding bahasa Cina, dengan jurang ini amat ketara dalam kalangan model kedudukan teratas. Terdapat spekulasi bahawa mungkin terdapat beberapa sebab:
Walaupun model ini mengandungi sejumlah besar data latihan bahasa Cina dan mempunyai keupayaan generalisasi merentas bahasa, data latihan mereka terutamanya berasaskan bahasa Inggeris. Soalan bahasa Cina lebih mencabar daripada soalan bahasa Inggeris, terutamanya dalam mata pelajaran seperti fizik dan kimia, soalan Olimpik Cina lebih sukar.
Model ini tidak mencukupi dalam mengenal pasti watak dalam imej berbilang modal, dan masalah ini lebih serius dalam persekitaran Cina.
-
Walau bagaimanapun, pasukan penyelidik juga mendapati bahawa beberapa model yang dibangunkan oleh pengeluar China atau diperhalusi berdasarkan model asas yang menyokong bahasa Cina berprestasi lebih baik dalam senario Cina berbanding dalam senario Inggeris, seperti Qwen1.5-32B- Sembang, Qwen -VL-Max, Yi-34B-Chat dan Qwen-7B-Chat, dsb. Model lain, seperti InternLM2-Chat-20B dan Yi-VL-34B, walaupun masih berprestasi lebih baik dalam bahasa Inggeris, mempunyai perbezaan ketepatan yang lebih kecil antara adegan bahasa Inggeris dan Cina berbanding model sumber tertutup yang menduduki tempat teratas. Ini menunjukkan bahawa mengoptimumkan model untuk data Cina dan lebih banyak bahasa di seluruh dunia masih memerlukan perhatian yang ketara.
- Analisis modaliti yang terperinci
Kapsyen: Prestasi setiap model dalam masalah mod yang berbeza. Jadual di atas menunjukkan prestasi model dalam modaliti yang berbeza. GPT-4o mengatasi Claude-3.5-Sonnet dalam kedua-dua teks biasa dan tugasan berbilang modal, dan berprestasi lebih menonjol pada teks biasa. Sebaliknya, Gemini-1.5-Pro mengungguli GPT-4V pada kedua-dua teks biasa dan tugasan berbilang modal. Pemerhatian ini menunjukkan bahawa walaupun model terkuat yang ada pada masa ini mempunyai ketepatan yang lebih tinggi pada tugasan teks sahaja berbanding tugasan berbilang modal. Ini menunjukkan bahawa model masih mempunyai ruang yang besar untuk penambahbaikan dalam menggunakan maklumat pelbagai modal untuk menyelesaikan masalah penaakulan yang kompleks. Dalam semakan ini, pasukan penyelidik memberi tumpuan terutamanya pada model terkini: Claude-3.5-Sonnet dan Gemini-1.5-Pro, dan membandingkannya dengan OpenAIo dan GPT 4V untuk perbandingan. Selain itu, pasukan penyelidik juga mereka bentuk sistem ranking baru untuk model besar, Jadual Pingat OlympicArena, untuk membandingkan dengan jelas keupayaan model yang berbeza. Pasukan penyelidik mendapati bahawa GPT-4o cemerlang dalam mata pelajaran seperti matematik dan sains komputer, dan mempunyai keupayaan penaakulan deduktif kompleks yang kuat dan keupayaan untuk membuat kesimpulan umum berdasarkan peraturan. Claude-3.5-Sonnet pula lebih pandai menaakul berdasarkan hubungan sebab akibat dan fenomena yang sedia ada. Di samping itu, pasukan penyelidik juga memerhatikan bahawa model-model ini menunjukkan prestasi yang lebih baik dalam masalah bahasa Inggeris dan mempunyai ruang yang besar untuk penambahbaikan dalam keupayaan pelbagai modal. Memahami nuansa model ini boleh membantu membangunkan model yang lebih khusus yang lebih memenuhi keperluan pelbagai bidang akademik dan profesional yang berbeza. Memandangkan acara Olimpik empat tahunan semakin hampir, kita tidak boleh tidak membayangkan apakah jenis pertarungan puncak antara kebijaksanaan dan teknologi jika kecerdasan buatan juga boleh mengambil bahagian? Ia bukan lagi sekadar persaingan fizikal Penambahan AI sudah pasti akan membuka penerokaan baharu tentang had kecerdasan Kami juga mengharapkan lebih ramai pemain AI menyertai Sukan Olimpik intelektual ini. [1] Huang et al., Olympicarena: Penanda aras pelbagai disiplin penalaran kognitif untuk Superintelligent AI https://arxiv.org/abs/2406.12753v1
Atas ialah kandungan terperinci Memilih AI paling bijak dalam Olympiad: Claude-3.5-Sonnet lwn. GPT-4o?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



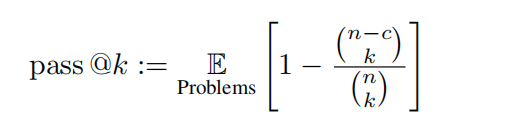
 Keadaan keseluruhan
Keadaan keseluruhan Soalan bahasa Cina lebih mencabar daripada soalan bahasa Inggeris, terutamanya dalam mata pelajaran seperti fizik dan kimia, soalan Olimpik Cina lebih sukar.
Soalan bahasa Cina lebih mencabar daripada soalan bahasa Inggeris, terutamanya dalam mata pelajaran seperti fizik dan kimia, soalan Olimpik Cina lebih sukar. 















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



