Meta telah membangunkan Pengkompil LLM yang hebat untuk membantu pengaturcara menulis kod dengan lebih cekap.
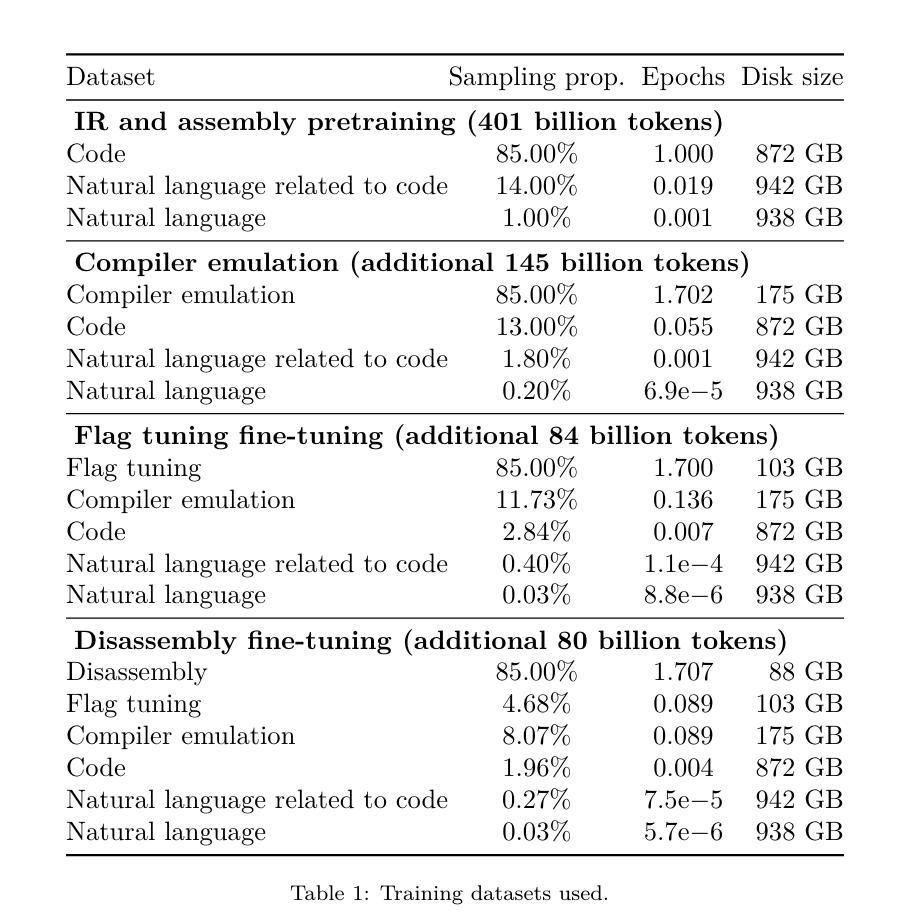
Semalam, tiga gergasi AI utama OpenAI, Google dan Meta bekerjasama untuk mengeluarkan hasil penyelidikan terkini model besar mereka sendiri - OpenAI melancarkan model baharu GPT-4GPT berasaskan latihan yang mengkhusus dalam mencari pepijat, sumber Terbuka Google 9B dan 27B versi Gemma2, dan Meta telah menghasilkan penemuan kecerdasan buatan terkini-LLM Compiler. Ini ialah set model sumber terbuka berkuasa yang direka untuk mengoptimumkan kod dan merevolusikan reka bentuk pengkompil. Inovasi ini berpotensi mengubah cara pembangun mendekati pengoptimuman kod, menjadikannya lebih pantas, lebih cekap dan lebih menjimatkan kos. Dilaporkan bahawa potensi pengoptimuman Pengkompil LLM mencapai 77% daripada carian penalaan automatik Hasil ini boleh mengurangkan masa penyusunan dan meningkatkan kecekapan kod pelbagai aplikasi, dan dari segi pembongkaran, pusingannya. perjalanan Kadar kejayaan pembongkaran ialah 45%. Sesetengah netizen mengatakan bahawa ini seperti penukar permainan untuk pengoptimuman dan pembongkaran kod. Ini adalah berita yang sangat baik untuk pembangun. Model bahasa yang besar telah menunjukkan keupayaan yang sangat baik dalam banyak tugas kejuruteraan perisian dan pengaturcaraan, tetapi aplikasinya dalam bidang pengoptimuman kod dan penyusun belum dieksploitasi sepenuhnya. Melatih LLM ini memerlukan sumber pengkomputeran yang luas, termasuk masa GPU yang mahal dan set data yang besar, yang sering menjadikan banyak penyelidikan dan projek tidak mampan. Untuk mengisi jurang ini, pasukan penyelidik Meta memperkenalkan Pengkompil LLM untuk mengoptimumkan kod secara khusus dan merevolusikan reka bentuk pengkompil. Dengan melatih model pada korpus besar-besaran 546 bilion token LLVM-IR dan kod pemasangan, mereka membolehkan model memahami perwakilan pengantara pengkompil, bahasa himpunan dan teknik pengoptimuman. Pautan kertas: https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/Penyelidik di “ LLM Compiler menyediakan pemahaman yang dipertingkatkan tentang perwakilan perantaraan pengkompil (IR), bahasa himpunan dan teknik pengoptimuman,” jelas kertas kerja mereka Pemahaman yang dipertingkatkan ini membolehkan model melaksanakan tugas yang sebelum ini terhad kepada pakar manusia atau alat khusus. Proses latihan Pengkompil LLM ditunjukkan dalam Rajah 1. LLM Compiler mencapai hasil yang ketara dalam pengoptimuman saiz kod. Dalam ujian, potensi pengoptimuman model mencapai 77% daripada carian penalaan automatik, hasil yang boleh mengurangkan masa penyusunan dengan ketara dan meningkatkan kecekapan kod untuk pelbagai aplikasi. Model lebih baik dalam pembongkaran. LLM Compiler mencapai 45% kadar kejayaan pembongkaran pergi balik (14% daripadanya adalah padanan tepat) apabila menukar kod pemasangan x86_64 dan ARM kembali kepada LLVM-IR. Keupayaan ini boleh menjadi tidak ternilai untuk tugas kejuruteraan terbalik dan penyelenggaraan kod warisan. Salah satu penyumbang teras kepada projek itu, Chris Cummins, menyerlahkan potensi impak teknologi ini: “Dengan menyediakan model pra-latihan dalam dua saiz (700 juta dan 1.3 bilion parameter) dan menunjukkan keberkesanannya melalui halus- versi yang ditala, "LLM Compiler membuka jalan untuk meneroka potensi LLM yang belum diterokai dalam bidang kod dan pengoptimuman pengkompil," katanya Pra-latihan mengenai kod pemasangan dan IR pengkompil Data yang digunakan untuk melatih pengaturcaraan. LLM biasanya terdiri daripada bahasa sumber peringkat tinggi seperti Python, akaun kod pemasangan untuk bahagian yang boleh diabaikan dalam set data ini, dan akaun IR pengkompil untuk yang lebih kecil.Untuk membina LLM dengan pemahaman yang baik tentang bahasa ini, pasukan penyelidik memulakan model Pengkompil LLM dengan pemberat Kod Llama, dan kemudian melatih 401 bilion token pada set data berpusatkan pengkompil Ini terutamanya terdiri daripada kod pemasangan dan IR pengkompil, seperti yang ditunjukkan dalam Jadual 1. Dataset LLM Compiler dilatih terutamanya pada perwakilan pengantara pengkompil dan kod pemasangan yang dijana oleh LLVM (versi 17.0.6 Data ini diperoleh daripada set data yang sama yang digunakan untuk melatih Kod Llama, yang telah dilaporkan dalam Jadual 2). Set data digariskan dalam . Seperti Code Llama, kami juga memperoleh kumpulan latihan kecil daripada set data bahasa semula jadi.  Penalaan halus arahan untuk simulasi pengkompilUntuk memahami mekanisme pengoptimuman kod, pasukan penyelidik melakukan penalaan halus arahan pada model Pengkompil LLM untuk mensimulasikan pengoptimuman pengkompil, seperti yang ditunjukkan dalam Rajah 2. Ideanya adalah untuk menjana sejumlah besar contoh daripada koleksi terhad program benih yang tidak dioptimumkan dengan menggunakan urutan pengoptimuman pengkompil yang dijana secara rawak pada program ini. Mereka kemudian melatih model untuk meramalkan kod yang dijana oleh pengoptimuman, dan juga melatih model untuk meramal saiz kod selepas menggunakan pengoptimuman. Spesifikasi tugas. Memandangkan LLVM-IR yang tidak dioptimumkan (output oleh bahagian hadapan clang), senarai pas pengoptimuman dan saiz kod permulaan, jana kod dan saiz kod yang terhasil selepas menggunakan pengoptimuman ini. Terdapat dua jenis tugasan ini: dalam yang pertama, model menjangkakan untuk mengeluarkan IR pengkompil, dalam yang kedua, model menjangkakan untuk mengeluarkan kod pemasangan. IR input, proses pengoptimuman dan saiz kod adalah sama untuk kedua-dua jenis, dan pembayang menentukan format output yang diperlukan. Saiz kod. Mereka menggunakan dua metrik untuk mengukur saiz kod: bilangan arahan IR dan saiz binari. Saiz binari dikira sebagai jumlah saiz segmen .TEKS dan .DATA selepas menurunkan taraf IR atau pemasangan kepada fail objek. Kami mengecualikan segmen .BSS kerana ia tidak menjejaskan saiz pada cakera. Optimumkan pas. Dalam kerja ini, pasukan penyelidik menyasarkan LLVM 17.0.6 dan menggunakan pengurus proses baharu (PM, 2021), yang mengklasifikasikan pas kepada tahap yang berbeza, seperti modul, fungsi, gelung, dll., serta menukar dan menganalisis pas . Pas transformasi menukar IR input yang diberikan, manakala pas analisis menjana maklumat yang mempengaruhi transformasi seterusnya. Daripada 346 kemungkinan parameter lulus untuk opt, mereka memilih 167 untuk digunakan. Ini termasuk setiap saluran paip pengoptimuman lalai (cth. modul (lalai)), pas transformasi pengoptimuman individu (cth. modul (constmerge)), tetapi tidak termasuk pas utiliti yang tidak mengoptimumkan (cth. modul (dot-callgraph)) dan tidak mengekalkan pas penukaran semantik (seperti modul (internalize)). Mereka mengecualikan pas analisis kerana mereka tidak mempunyai kesan sampingan dan kami bergantung kepada pengurus pas untuk menyuntik pas analisis bergantung seperti yang diperlukan. Untuk pas yang menerima parameter, kami menggunakan nilai lalai (cth. modul (licm)). Jadual 9 mengandungi senarai semua pas yang digunakan. Kami menggunakan senarai pas menggunakan alat opt LLVM dan menurunkan taraf IR yang terhasil kepada fail objek menggunakan clang. Penyenaraian 1 menunjukkan arahan yang digunakan. set data. Pasukan penyelidik menjana set data simulasi pengkompil dengan menggunakan senarai 1 hingga 50 pas pengoptimuman rawak kepada program yang tidak dioptimumkan yang diringkaskan dalam Jadual 2. Panjang setiap senarai lulus dipilih secara seragam dan rawak. Senarai lulus dijana dengan pensampelan seragam daripada set 167 lulus di atas. Senarai lulus yang menyebabkan pengkompil ranap atau tamat masa selepas 120 saat dikecualikan. LLM Compiler FTD: Lanjutkan tugas kompilasi hiliran Penalaan halus arahan untuk pengoptimuman impak penalaan pada pengkompilasian bendera
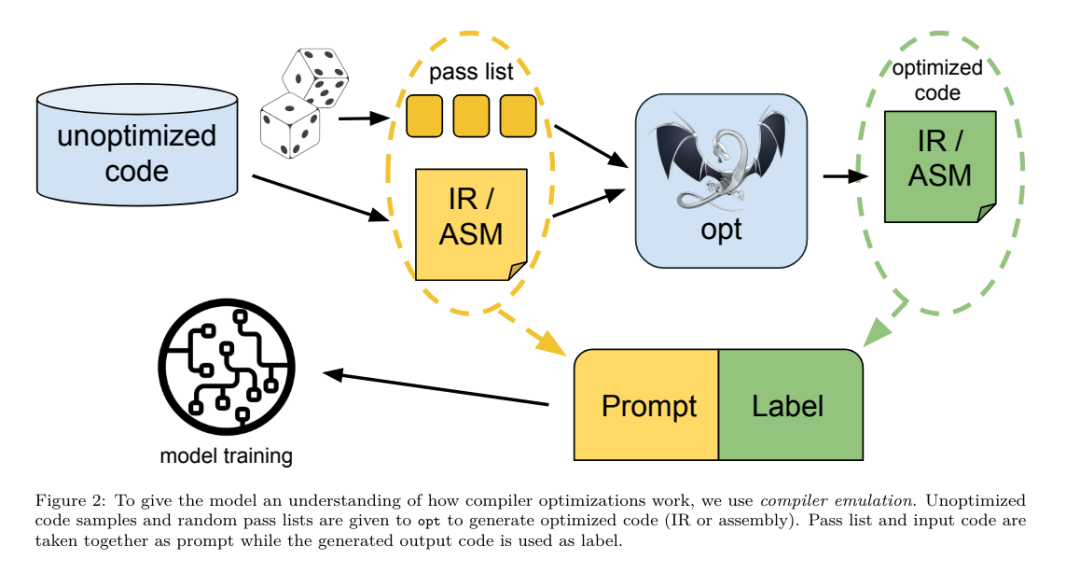
Penalaan halus arahan untuk simulasi pengkompilUntuk memahami mekanisme pengoptimuman kod, pasukan penyelidik melakukan penalaan halus arahan pada model Pengkompil LLM untuk mensimulasikan pengoptimuman pengkompil, seperti yang ditunjukkan dalam Rajah 2. Ideanya adalah untuk menjana sejumlah besar contoh daripada koleksi terhad program benih yang tidak dioptimumkan dengan menggunakan urutan pengoptimuman pengkompil yang dijana secara rawak pada program ini. Mereka kemudian melatih model untuk meramalkan kod yang dijana oleh pengoptimuman, dan juga melatih model untuk meramal saiz kod selepas menggunakan pengoptimuman. Spesifikasi tugas. Memandangkan LLVM-IR yang tidak dioptimumkan (output oleh bahagian hadapan clang), senarai pas pengoptimuman dan saiz kod permulaan, jana kod dan saiz kod yang terhasil selepas menggunakan pengoptimuman ini. Terdapat dua jenis tugasan ini: dalam yang pertama, model menjangkakan untuk mengeluarkan IR pengkompil, dalam yang kedua, model menjangkakan untuk mengeluarkan kod pemasangan. IR input, proses pengoptimuman dan saiz kod adalah sama untuk kedua-dua jenis, dan pembayang menentukan format output yang diperlukan. Saiz kod. Mereka menggunakan dua metrik untuk mengukur saiz kod: bilangan arahan IR dan saiz binari. Saiz binari dikira sebagai jumlah saiz segmen .TEKS dan .DATA selepas menurunkan taraf IR atau pemasangan kepada fail objek. Kami mengecualikan segmen .BSS kerana ia tidak menjejaskan saiz pada cakera. Optimumkan pas. Dalam kerja ini, pasukan penyelidik menyasarkan LLVM 17.0.6 dan menggunakan pengurus proses baharu (PM, 2021), yang mengklasifikasikan pas kepada tahap yang berbeza, seperti modul, fungsi, gelung, dll., serta menukar dan menganalisis pas . Pas transformasi menukar IR input yang diberikan, manakala pas analisis menjana maklumat yang mempengaruhi transformasi seterusnya. Daripada 346 kemungkinan parameter lulus untuk opt, mereka memilih 167 untuk digunakan. Ini termasuk setiap saluran paip pengoptimuman lalai (cth. modul (lalai)), pas transformasi pengoptimuman individu (cth. modul (constmerge)), tetapi tidak termasuk pas utiliti yang tidak mengoptimumkan (cth. modul (dot-callgraph)) dan tidak mengekalkan pas penukaran semantik (seperti modul (internalize)). Mereka mengecualikan pas analisis kerana mereka tidak mempunyai kesan sampingan dan kami bergantung kepada pengurus pas untuk menyuntik pas analisis bergantung seperti yang diperlukan. Untuk pas yang menerima parameter, kami menggunakan nilai lalai (cth. modul (licm)). Jadual 9 mengandungi senarai semua pas yang digunakan. Kami menggunakan senarai pas menggunakan alat opt LLVM dan menurunkan taraf IR yang terhasil kepada fail objek menggunakan clang. Penyenaraian 1 menunjukkan arahan yang digunakan. set data. Pasukan penyelidik menjana set data simulasi pengkompil dengan menggunakan senarai 1 hingga 50 pas pengoptimuman rawak kepada program yang tidak dioptimumkan yang diringkaskan dalam Jadual 2. Panjang setiap senarai lulus dipilih secara seragam dan rawak. Senarai lulus dijana dengan pensampelan seragam daripada set 167 lulus di atas. Senarai lulus yang menyebabkan pengkompil ranap atau tamat masa selepas 120 saat dikecualikan. LLM Compiler FTD: Lanjutkan tugas kompilasi hiliran Penalaan halus arahan untuk pengoptimuman impak penalaan pada pengkompilasian bendera prestasi masa jalan dan saiz kod. Pasukan penyelidik melatih model LLM Compiler FTD untuk melaksanakan tugas hiliran memilih bendera untuk pilihan alat pengoptimuman IR LLVM untuk menghasilkan saiz kod terkecil.
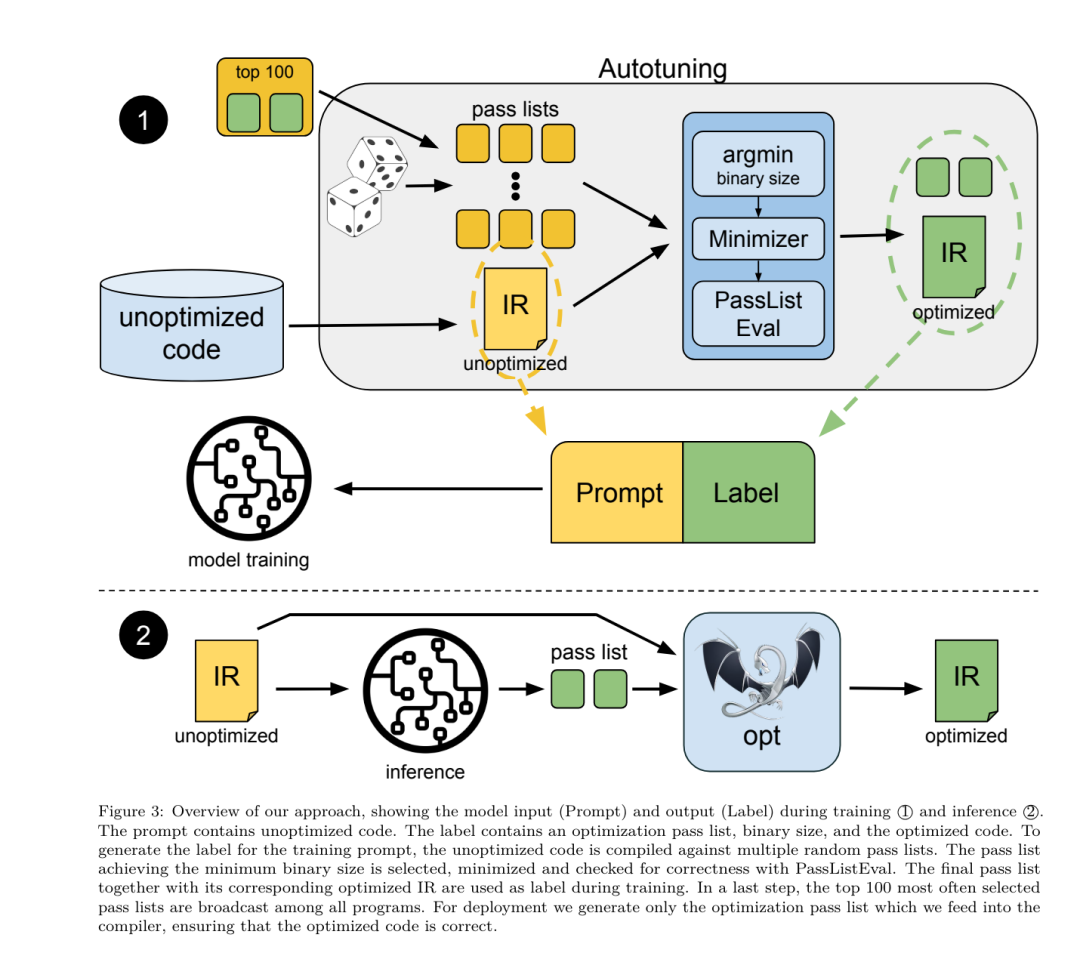
🎜Kaedah pembelajaran mesin yang ditala bendera sebelum ini telah menunjukkan hasil yang baik, tetapi menghadapi kesukaran dengan generalisasi merentas program yang berbeza.Kerja sebelumnya sering memerlukan penyusunan program baharu berpuluh atau ratusan kali untuk mencuba konfigurasi yang berbeza dan mencari pilihan berprestasi terbaik. Pasukan penyelidik melatih dan menilai model LLM Compiler FTD pada versi tangkapan sifar tugas ini dengan meramalkan bendera untuk meminimumkan saiz kod program yang tidak kelihatan. Pendekatan mereka tidak bergantung pada pengkompil dan metrik pengoptimuman yang dipilih, dan mereka berhasrat untuk menyasarkan prestasi masa jalan pada masa hadapan. Pada masa ini, mengoptimumkan saiz kod memudahkan pengumpulan data latihan. Spesifikasi tugas. Pasukan penyelidik membentangkan LLVM-IR yang tidak dioptimumkan (dihasilkan oleh bahagian hadapan clang) kepada model LLM Compiler FTD dan memintanya menjana senarai bendera opt yang harus digunakan, saiz binari sebelum dan selepas pengoptimuman ini digunakan, dan kod output jika ia tidak boleh digunakan pada kod input Penambahbaikan dibuat untuk menghasilkan mesej output pendek yang mengandungi hanya saiz binari yang tidak dioptimumkan. Mereka menggunakan set pas pengoptimuman terhad yang sama seperti tugas simulasi pengkompil dan mengira saiz binari dengan cara yang sama. Rajah 3 menggambarkan proses yang digunakan untuk menjana data latihan dan cara model digunakan pada masa inferens. Hanya senarai lulus yang dijana diperlukan semasa penilaian. Mereka mengekstrak senarai pas daripada output model dan menjalankan opt dengan parameter yang diberikan. Penyelidik kemudiannya boleh menilai ketepatan saiz binari yang diramalkan model dan mengoptimumkan kod output, tetapi ini adalah tugasan pembelajaran tambahan dan tidak diperlukan untuk digunakan. Ketepatan. Pengoptimum LLVM tidak sempurna dan laluan pengoptimuman yang dijalankan dalam susunan yang tidak dijangka atau tidak diuji boleh mendedahkan ralat ketepatan halus yang mengurangkan kegunaan model. Untuk mengurangkan risiko ini, pasukan penyelidik membangunkan PassListEval, alat untuk membantu mengenal pasti senarai laluan secara automatik yang memecahkan semantik program atau menyebabkan pengkompil ranap. Rajah 4 menunjukkan gambaran keseluruhan alat. 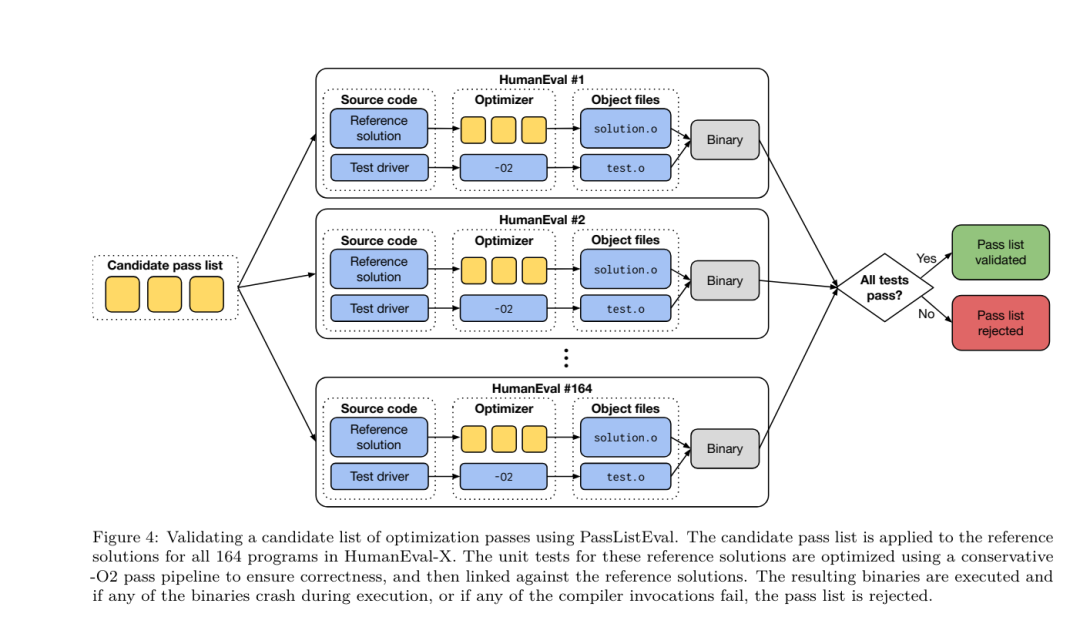 PassListEval menerima sebagai input senarai pas calon dan menilainya pada set 164 program C++ ujian sendiri, diambil daripada HumanEval-X. Setiap program mengandungi penyelesaian rujukan kepada cabaran pengaturcaraan, seperti "semak sama ada jarak antara dua nombor dalam vektor nombor tertentu adalah kurang daripada ambang tertentu", serta set ujian unit untuk mengesahkan ketepatan. Mereka menggunakan senarai pas calon untuk rujukan penyelesaian dan kemudian memautkannya dengan suite ujian untuk menjana binari. Semasa melaksanakan, jika mana-mana ujian gagal, binari akan ranap. Jika sebarang ranap binari, atau sebarang panggilan pengkompil gagal, kami menolak senarai lulus calon. set data. Pasukan ini melatih model LLM Compiler FTD pada set data contoh yang ditala bendera yang diperoleh daripada 4.5 juta IR tidak dioptimumkan yang digunakan untuk pralatihan. Untuk menjana contoh senarai lulus terbaik bagi setiap program, mereka melakukan proses penyusunan berulang yang meluas, seperti yang ditunjukkan dalam Rajah 3. 1. Pasukan penyelidik menggunakan carian rawak berskala besar untuk menjana senarai lulus terbaik calon awal untuk program ini. Untuk setiap program, mereka secara bebas menjana senarai rawak sehingga 50 pas, sampel seragam daripada set 167 pas yang boleh dicari yang diterangkan sebelumnya. Setiap kali mereka menilai senarai lulus program, mereka merekodkan saiz binari yang terhasil, dan kemudian memilih senarai lulus setiap program yang menghasilkan saiz binari terkecil. Mereka menjalankan 22 bilion kompilasi bebas, purata 4,877 setiap program. 2. Senarai lulus yang dijana oleh carian rawak mungkin mengandungi pas berlebihan, yang tidak memberi kesan kepada keputusan akhir. Selain itu, beberapa pesanan pas boleh ditukar ganti dan susunan semula tidak akan menjejaskan keputusan akhir. Memandangkan ini memperkenalkan hingar ke dalam data latihan, mereka membangunkan proses peminimakan dan menggunakannya pada setiap senarai lulus. Pengurangan termasuk tiga langkah: penghapusan pas berlebihan, isihan gelembung dan carian sisipan. Dalam penyingkiran pas berlebihan, mereka meminimumkan senarai pas optimum dengan mengalih keluar pas individu secara berulang untuk melihat sama ada ia menyumbang kepada saiz binari, dan jika tidak, buangkannya. Ulangi proses ini sehingga tiada lagi pas boleh digugurkan. Isih gelembung kemudian cuba menyediakan susunan bersatu untuk urutan pas, mengisih pas berdasarkan kata kunci. Akhir sekali, isihan sisipan melakukan carian setempat dengan menggelung setiap pas dalam senarai pas dan cuba memasukkan setiap satu daripada 167 pas carian sebelumnya. Jika berbuat demikian meningkatkan saiz binari, simpan senarai pas baharu ini. Keseluruhan saluran paip pengecilan digelung sehingga titik tetap dicapai. Taburan panjang senarai lulus yang diminimumkan ditunjukkan dalam Rajah 9. Purata panjang senarai lulus ialah 3.84.3 Mereka menggunakan PassListEval yang diterangkan sebelum ini kepada senarai lulus terbaik calon. Dengan cara ini, mereka mengenal pasti 167,971 daripada 1,704,443 senarai pas unik (9.85%) yang akan menyebabkan ralat masa kompilasi atau masa jalan 4 Mereka menyiarkan 100 senarai pas optimum yang paling biasa kepada semua program dan kemas kini senarai lulus terbaik untuk setiap program jika penambahbaikan didapati. Selepas itu, jumlah senarai lulus terbaik unik telah dikurangkan daripada 1,536,472 kepada 581,076. Saluran paip penalaan automatik di atas menghasilkan pengurangan saiz binari min geometri sebanyak 7.1% berbanding -Oz. Rajah 10 menunjukkan kekerapan satu hantaran. Bagi mereka, penalaan automatik ini berfungsi sebagai standard emas untuk setiap pengoptimuman program. Walaupun penjimatan saiz binari yang ditemui adalah penting, ini memerlukan 28 bilion kompilasi tambahan dengan kos pengiraan lebih 21,000 hari CPU. Matlamat penalaan halus arahan LLM Compiler FTD untuk melaksanakan tugas penalaan bendera adalah untuk mencapai sebahagian kecil daripada prestasi penala automatik tanpa perlu menjalankan pengkompil beribu kali. . seni bina baharu. Bidang penyahkompilasi telah mencapai kemajuan dalam menggunakan teknik pembelajaran mesin untuk menjana kod yang boleh dibaca dan tepat daripada boleh laku binari. Dalam kajian ini, pasukan penyelidik menunjukkan bagaimana LLM Compiler FTD boleh melakukan pembongkaran melalui penalaan halus, mempelajari hubungan antara kod pemasangan dan IR pengkompil. Tugasnya adalah untuk mempelajari terjemahan songsang bagi clang -xir - -o - -S, seperti yang ditunjukkan dalam Rajah 5. Ujian pergi dan balik. Menggunakan LLM untuk pembongkaran boleh menyebabkan masalah ketepatan. Kod yang dirangsang mesti disahkan dengan penyemak kesetaraan, yang tidak selalu boleh dilakukan, atau memerlukan pengesahan manual ketepatan, atau kes ujian yang mencukupi untuk mendapatkan keyakinan. Walau bagaimanapun, had yang lebih rendah pada ketepatan boleh didapati melalui ujian pergi balik. Iaitu, dengan menyusun semula IR yang diangkat ke dalam kod pemasangan, jika kod pemasangan adalah sama, IR adalah betul. Ini menyediakan laluan mudah untuk menggunakan hasil LLM dan merupakan cara mudah untuk mengukur utiliti model yang dibongkar.
PassListEval menerima sebagai input senarai pas calon dan menilainya pada set 164 program C++ ujian sendiri, diambil daripada HumanEval-X. Setiap program mengandungi penyelesaian rujukan kepada cabaran pengaturcaraan, seperti "semak sama ada jarak antara dua nombor dalam vektor nombor tertentu adalah kurang daripada ambang tertentu", serta set ujian unit untuk mengesahkan ketepatan. Mereka menggunakan senarai pas calon untuk rujukan penyelesaian dan kemudian memautkannya dengan suite ujian untuk menjana binari. Semasa melaksanakan, jika mana-mana ujian gagal, binari akan ranap. Jika sebarang ranap binari, atau sebarang panggilan pengkompil gagal, kami menolak senarai lulus calon. set data. Pasukan ini melatih model LLM Compiler FTD pada set data contoh yang ditala bendera yang diperoleh daripada 4.5 juta IR tidak dioptimumkan yang digunakan untuk pralatihan. Untuk menjana contoh senarai lulus terbaik bagi setiap program, mereka melakukan proses penyusunan berulang yang meluas, seperti yang ditunjukkan dalam Rajah 3. 1. Pasukan penyelidik menggunakan carian rawak berskala besar untuk menjana senarai lulus terbaik calon awal untuk program ini. Untuk setiap program, mereka secara bebas menjana senarai rawak sehingga 50 pas, sampel seragam daripada set 167 pas yang boleh dicari yang diterangkan sebelumnya. Setiap kali mereka menilai senarai lulus program, mereka merekodkan saiz binari yang terhasil, dan kemudian memilih senarai lulus setiap program yang menghasilkan saiz binari terkecil. Mereka menjalankan 22 bilion kompilasi bebas, purata 4,877 setiap program. 2. Senarai lulus yang dijana oleh carian rawak mungkin mengandungi pas berlebihan, yang tidak memberi kesan kepada keputusan akhir. Selain itu, beberapa pesanan pas boleh ditukar ganti dan susunan semula tidak akan menjejaskan keputusan akhir. Memandangkan ini memperkenalkan hingar ke dalam data latihan, mereka membangunkan proses peminimakan dan menggunakannya pada setiap senarai lulus. Pengurangan termasuk tiga langkah: penghapusan pas berlebihan, isihan gelembung dan carian sisipan. Dalam penyingkiran pas berlebihan, mereka meminimumkan senarai pas optimum dengan mengalih keluar pas individu secara berulang untuk melihat sama ada ia menyumbang kepada saiz binari, dan jika tidak, buangkannya. Ulangi proses ini sehingga tiada lagi pas boleh digugurkan. Isih gelembung kemudian cuba menyediakan susunan bersatu untuk urutan pas, mengisih pas berdasarkan kata kunci. Akhir sekali, isihan sisipan melakukan carian setempat dengan menggelung setiap pas dalam senarai pas dan cuba memasukkan setiap satu daripada 167 pas carian sebelumnya. Jika berbuat demikian meningkatkan saiz binari, simpan senarai pas baharu ini. Keseluruhan saluran paip pengecilan digelung sehingga titik tetap dicapai. Taburan panjang senarai lulus yang diminimumkan ditunjukkan dalam Rajah 9. Purata panjang senarai lulus ialah 3.84.3 Mereka menggunakan PassListEval yang diterangkan sebelum ini kepada senarai lulus terbaik calon. Dengan cara ini, mereka mengenal pasti 167,971 daripada 1,704,443 senarai pas unik (9.85%) yang akan menyebabkan ralat masa kompilasi atau masa jalan 4 Mereka menyiarkan 100 senarai pas optimum yang paling biasa kepada semua program dan kemas kini senarai lulus terbaik untuk setiap program jika penambahbaikan didapati. Selepas itu, jumlah senarai lulus terbaik unik telah dikurangkan daripada 1,536,472 kepada 581,076. Saluran paip penalaan automatik di atas menghasilkan pengurangan saiz binari min geometri sebanyak 7.1% berbanding -Oz. Rajah 10 menunjukkan kekerapan satu hantaran. Bagi mereka, penalaan automatik ini berfungsi sebagai standard emas untuk setiap pengoptimuman program. Walaupun penjimatan saiz binari yang ditemui adalah penting, ini memerlukan 28 bilion kompilasi tambahan dengan kos pengiraan lebih 21,000 hari CPU. Matlamat penalaan halus arahan LLM Compiler FTD untuk melaksanakan tugas penalaan bendera adalah untuk mencapai sebahagian kecil daripada prestasi penala automatik tanpa perlu menjalankan pengkompil beribu kali. . seni bina baharu. Bidang penyahkompilasi telah mencapai kemajuan dalam menggunakan teknik pembelajaran mesin untuk menjana kod yang boleh dibaca dan tepat daripada boleh laku binari. Dalam kajian ini, pasukan penyelidik menunjukkan bagaimana LLM Compiler FTD boleh melakukan pembongkaran melalui penalaan halus, mempelajari hubungan antara kod pemasangan dan IR pengkompil. Tugasnya adalah untuk mempelajari terjemahan songsang bagi clang -xir - -o - -S, seperti yang ditunjukkan dalam Rajah 5. Ujian pergi dan balik. Menggunakan LLM untuk pembongkaran boleh menyebabkan masalah ketepatan. Kod yang dirangsang mesti disahkan dengan penyemak kesetaraan, yang tidak selalu boleh dilakukan, atau memerlukan pengesahan manual ketepatan, atau kes ujian yang mencukupi untuk mendapatkan keyakinan. Walau bagaimanapun, had yang lebih rendah pada ketepatan boleh didapati melalui ujian pergi balik. Iaitu, dengan menyusun semula IR yang diangkat ke dalam kod pemasangan, jika kod pemasangan adalah sama, IR adalah betul. Ini menyediakan laluan mudah untuk menggunakan hasil LLM dan merupakan cara mudah untuk mengukur utiliti model yang dibongkar.
Spesifikasi tugas. Pasukan penyelidik memberi kod pemasangan model dan melatihnya untuk mengeluarkan IR pembongkaran yang sepadan. Panjang konteks untuk tugasan ini ditetapkan kepada 8k token untuk kod pemasangan input dan 8k token untuk IR output. 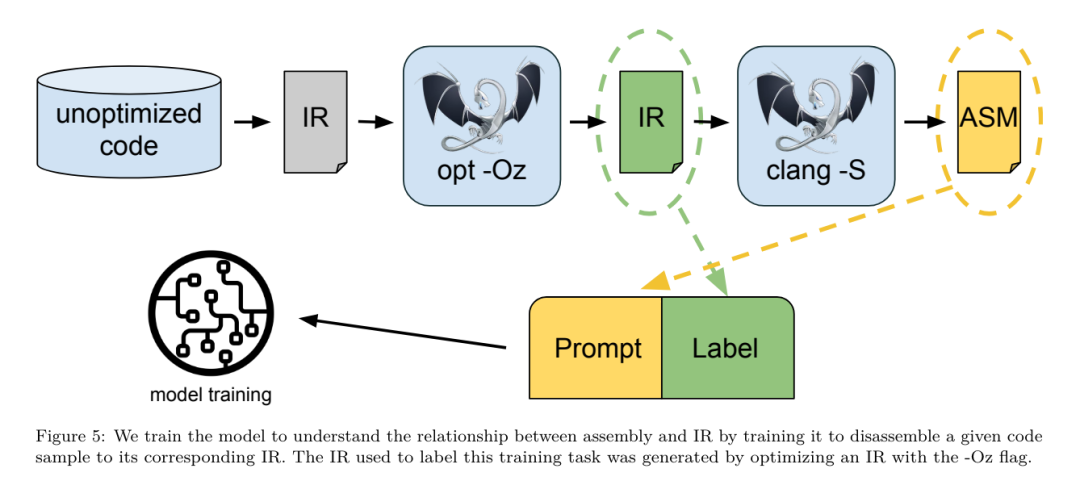 set data. Mereka memperoleh kod pemasangan dan pasangan IR daripada set data yang digunakan dalam tugasan sebelumnya. Set data penalaan halus mereka mengandungi 4.7 juta sampel, dan IR input telah dioptimumkan menggunakan -Oz sebelum dikurangkan kepada pemasangan x86.
set data. Mereka memperoleh kod pemasangan dan pasangan IR daripada set data yang digunakan dalam tugasan sebelumnya. Set data penalaan halus mereka mengandungi 4.7 juta sampel, dan IR input telah dioptimumkan menggunakan -Oz sebelum dikurangkan kepada pemasangan x86. Parameter Latihan
Data ditandakan melalui pengekodan pasangan bait, menggunakan tokenizer yang sama seperti Kod Llama, Llama dan Llama 2. Mereka menggunakan parameter latihan yang sama untuk keempat-empat fasa latihan. Mereka menggunakan kebanyakan parameter latihan yang sama seperti model asas Kod Llama, menggunakan pengoptimum AdamW dengan nilai 0.9 dan 0.95 untuk β1 dan β2. Mereka menggunakan penjadualan kosinus dengan langkah memanaskan badan sebanyak 1000 langkah dan menetapkan kadar pembelajaran akhir kepada 1/30 daripada kadar pembelajaran puncak. Berbanding dengan model asas Kod Llama, pasukan itu meningkatkan panjang konteks jujukan tunggal daripada 4096 kepada 16384 tetapi mengekalkan saiz kelompok malar pada 4 juta token. Untuk menampung konteks yang lebih panjang, mereka menetapkan kadar pembelajaran kepada 2e-5 dan mengubah suai parameter pembenaman kedudukan RoPE, di mana mereka menetapkan semula kekerapan kepada nilai asas θ=10^6. Tetapan ini konsisten dengan latihan konteks panjang model asas Code Llama. Penilaian
Pasukan penyelidik menilai prestasi model Pengkompil LLM mengenai tugas penalaan dan pembongkaran bendera, simulasi pengkompil, ramalan token seterusnya dan tugasan kejuruteraan perisian.
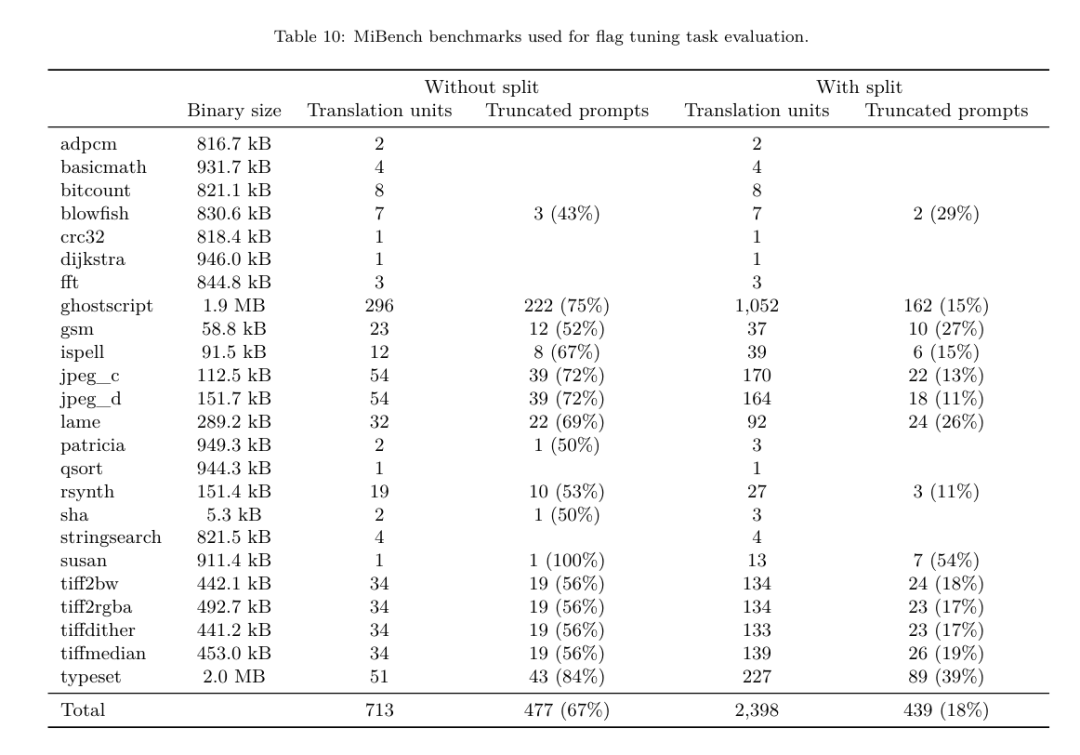
Kaedah. Mereka menilai prestasi LLM Compiler FTD pada tugas menala bendera pengoptimuman untuk program yang tidak kelihatan dan membandingkannya dengan GPT-4 Turbo dan Code Llama - Instruct. Mereka menjalankan inferens pada setiap model dan mengekstrak senarai pas pengoptimuman daripada output model Mereka kemudian menggunakan senarai pas ini untuk mengoptimumkan program tertentu dan merekodkan saiz binari ialah saiz binari program apabila dioptimumkan dengan -Oz. Untuk GPT-4 Turbo dan Code Llama - Arahan, mereka menambahkan akhiran selepas pembayang untuk menyediakan konteks tambahan untuk menerangkan lebih lanjut masalah dan format output yang dijangkakan.Semua senarai pas yang dijana oleh model disahkan menggunakan PassListEval, dan -Oz digunakan sebagai alternatif jika pengesahan gagal. Untuk mengesahkan lagi ketepatan senarai lulus yang dijana oleh model, mereka memautkan perduaan atur cara terakhir dan menguji secara berbeza outputnya terhadap output penanda aras yang dioptimumkan menggunakan saluran paip pengoptimuman konservatif -O2. Set data. Pasukan penyelidik menjalankan penilaian menggunakan 2,398 petunjuk ujian yang diekstrak daripada suite penanda aras MiBench. Untuk menjana pembayang ini, mereka mengambil kesemua 713 unit terjemahan yang membentuk 24 penanda aras MiBench dan menjana IR yang tidak dioptimumkan daripada setiap unit, kemudian memformatkannya menjadi pembayang. Jika pembayang yang dijana melebihi 15k token, mereka menggunakan llvm-extract untuk memisahkan modul LLVM yang mewakili unit terjemahan itu kepada modul yang lebih kecil, satu bagi setiap fungsi, yang menghasilkan 1,985 pembayang yang sesuai dengan tetingkap konteks token 15k, meninggalkan 443 unit terjemahan Tidak sesuai . Apabila mengira skor prestasi, mereka menggunakan -Oz untuk 443 unit terjemahan yang dikecualikan. Jadual 10 meringkaskan penanda aras. 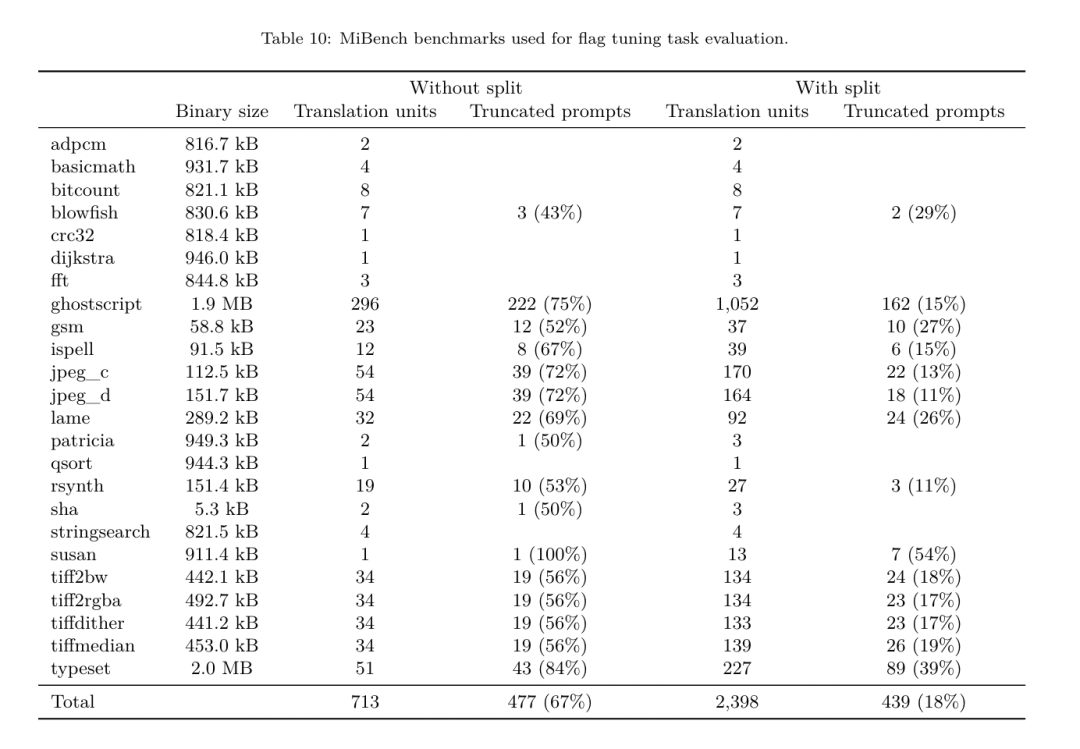 Hasilnya. Jadual 3 menunjukkan prestasi tangkapan sifar semua model pada tugas penalaan bendera. Hanya model LLM Compiler FTD bertambah baik berbanding -Oz, dengan model parameter 13B sedikit mengatasi model yang lebih kecil, menghasilkan fail objek yang lebih kecil daripada -Oz 61% pada masa itu.
Hasilnya. Jadual 3 menunjukkan prestasi tangkapan sifar semua model pada tugas penalaan bendera. Hanya model LLM Compiler FTD bertambah baik berbanding -Oz, dengan model parameter 13B sedikit mengatasi model yang lebih kecil, menghasilkan fail objek yang lebih kecil daripada -Oz 61% pada masa itu. 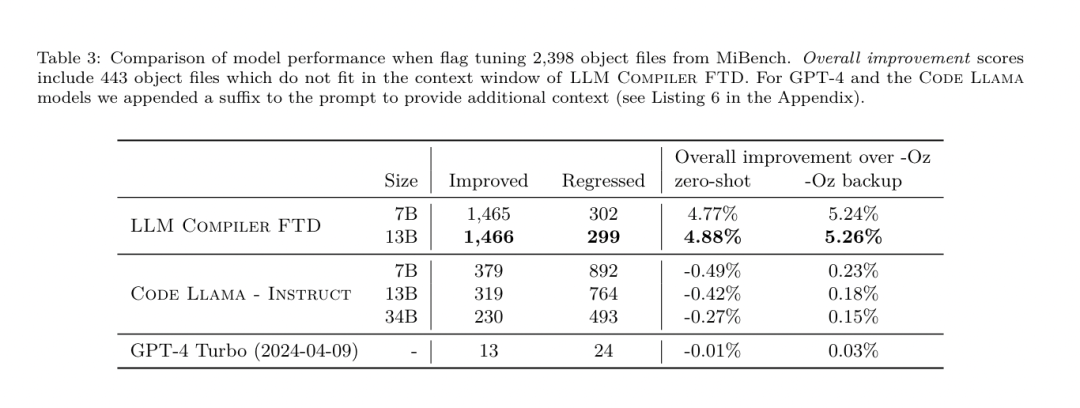 Dalam sesetengah kes, senarai pas yang dijana oleh model menghasilkan saiz fail sasaran yang lebih besar daripada -Oz. Sebagai contoh, LLM Compiler FTD 13B mempunyai kemerosotan dalam 12% kes. Degradasi ini boleh dielakkan dengan hanya menyusun atur cara dua kali: sekali dengan senarai lulus yang dijana oleh model, dan sekali dengan -Oz, kemudian memilih senarai lulus yang menghasilkan hasil terbaik. Dengan menghapuskan kemerosotan berbanding -Oz, skor sandaran -Oz ini meningkatkan peningkatan keseluruhan LLM Compiler FTD 13B berbanding -Oz kepada 5.26% dan membolehkan Kod Llama - Arahan dan GPT-4 Turbo mencapai peningkatan sederhana berbanding -Oz . Rajah 6 menunjukkan pecahan prestasi setiap model pada pelbagai penanda aras.
Dalam sesetengah kes, senarai pas yang dijana oleh model menghasilkan saiz fail sasaran yang lebih besar daripada -Oz. Sebagai contoh, LLM Compiler FTD 13B mempunyai kemerosotan dalam 12% kes. Degradasi ini boleh dielakkan dengan hanya menyusun atur cara dua kali: sekali dengan senarai lulus yang dijana oleh model, dan sekali dengan -Oz, kemudian memilih senarai lulus yang menghasilkan hasil terbaik. Dengan menghapuskan kemerosotan berbanding -Oz, skor sandaran -Oz ini meningkatkan peningkatan keseluruhan LLM Compiler FTD 13B berbanding -Oz kepada 5.26% dan membolehkan Kod Llama - Arahan dan GPT-4 Turbo mencapai peningkatan sederhana berbanding -Oz . Rajah 6 menunjukkan pecahan prestasi setiap model pada pelbagai penanda aras. 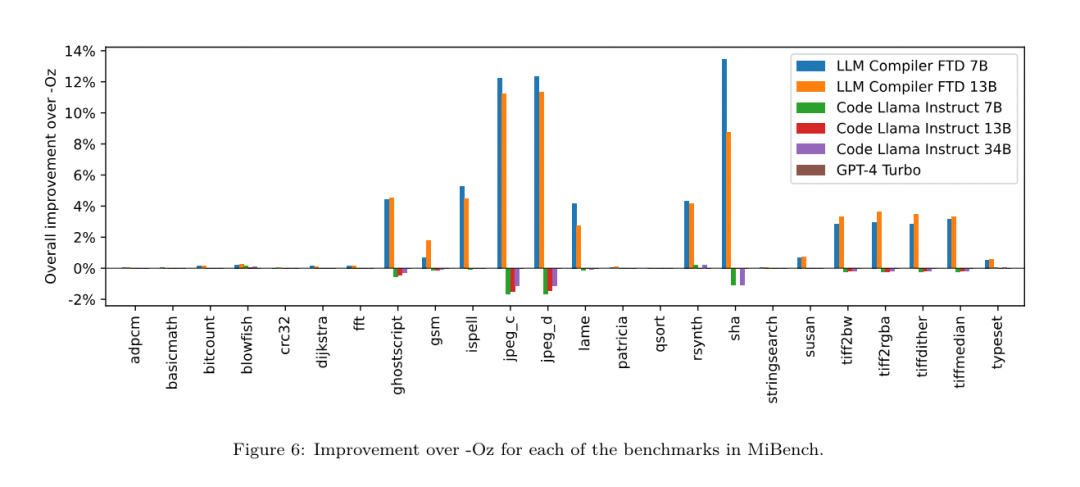 Ketepatan saiz binari. Walaupun ramalan saiz binari yang dijana oleh model tidak mempunyai kesan ke atas kompilasi sebenar, pasukan penyelidik boleh menilai prestasi model dalam meramalkan saiz binari sebelum dan selepas pengoptimuman untuk memahami sejauh mana setiap model memahami pengoptimuman. Rajah 7 menunjukkan keputusan.
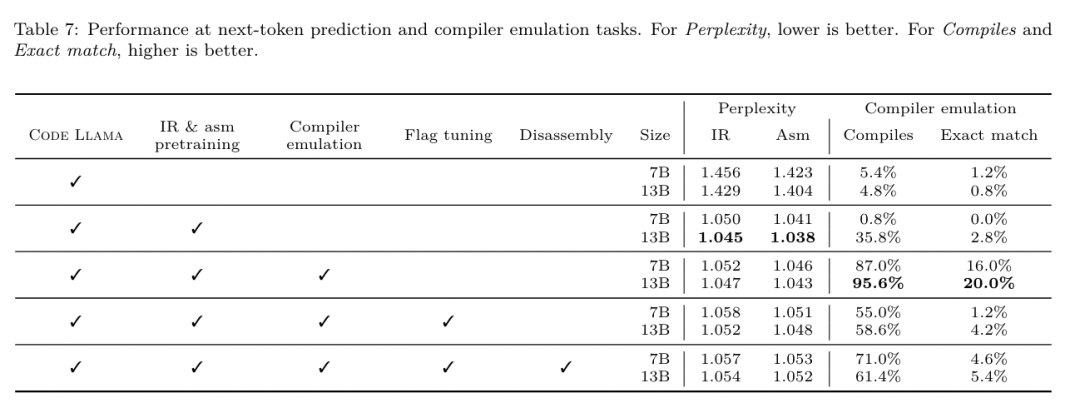
Ketepatan saiz binari. Walaupun ramalan saiz binari yang dijana oleh model tidak mempunyai kesan ke atas kompilasi sebenar, pasukan penyelidik boleh menilai prestasi model dalam meramalkan saiz binari sebelum dan selepas pengoptimuman untuk memahami sejauh mana setiap model memahami pengoptimuman. Rajah 7 menunjukkan keputusan.  Ramalan saiz binari LLM Compiler FTD berkait rapat dengan keadaan sebenar, dengan model parameter 7B mencapai nilai MAPE sebanyak 0.083 dan 0.225 untuk saiz binari yang tidak dioptimumkan dan dioptimumkan. Nilai MAPE untuk model parametrik 13B adalah serupa, masing-masing 0.082 dan 0.225. Kod Llama - Arahan dan ramalan saiz binari GPT-4 Turbo mempunyai sedikit korelasi dengan realiti. Para penyelidik mendapati bahawa LLM Compiler FTD mempunyai ralat yang lebih tinggi sedikit untuk kod yang dioptimumkan daripada untuk kod yang tidak dioptimumkan. Khususnya, LLM Compiler FTD kadangkala mempunyai kecenderungan untuk menilai terlalu tinggi keberkesanan pengoptimuman, menghasilkan ramalan saiz binari yang lebih rendah daripada saiz sebenar. Penyelidikan ablasi. Jadual 4 membentangkan kajian ablasi prestasi model pada set pengesahan kecil tahan 500 isyarat daripada pengedaran yang sama dengan data latihan mereka (tetapi tidak digunakan dalam latihan). Mereka melakukan latihan yang ditala bendera pada setiap peringkat saluran paip latihan yang ditunjukkan dalam Rajah 1 untuk membandingkan prestasi. Seperti yang ditunjukkan, latihan pembongkaran mengakibatkan penurunan prestasi sedikit daripada purata 5.15% kepada 5.12% (peningkatan melebihi -Oz). Mereka juga menunjukkan prestasi penala auto yang digunakan untuk menjana data latihan yang diterangkan dalam Bahagian 2. LLM Compiler FTD mencapai 77% daripada prestasi autotuner.
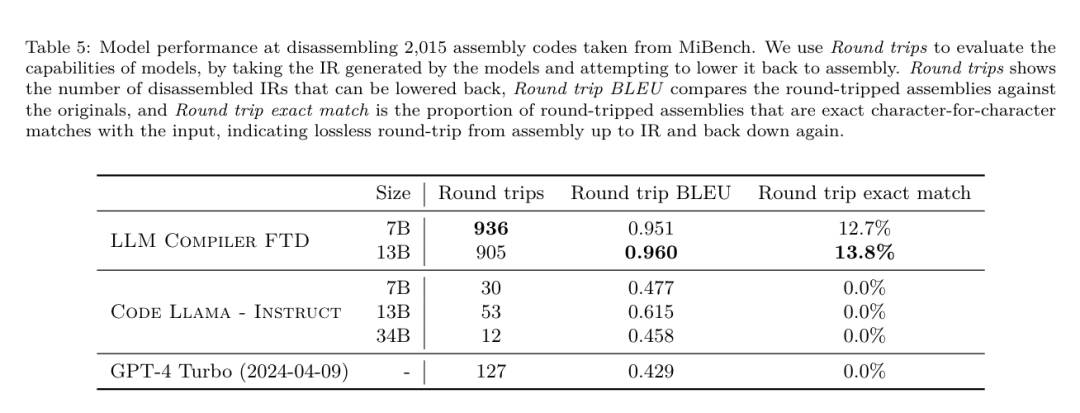
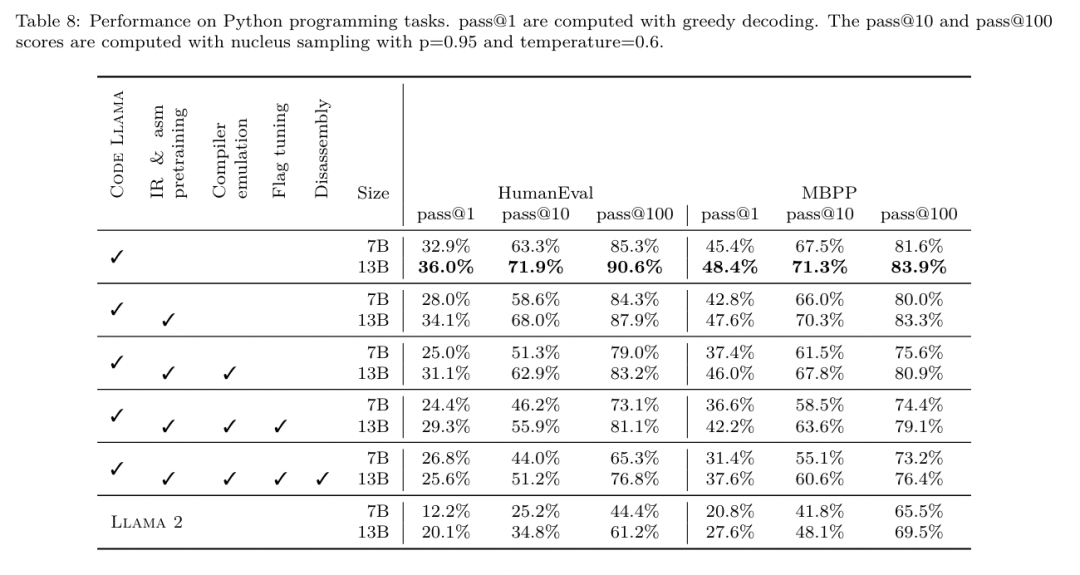
Ramalan saiz binari LLM Compiler FTD berkait rapat dengan keadaan sebenar, dengan model parameter 7B mencapai nilai MAPE sebanyak 0.083 dan 0.225 untuk saiz binari yang tidak dioptimumkan dan dioptimumkan. Nilai MAPE untuk model parametrik 13B adalah serupa, masing-masing 0.082 dan 0.225. Kod Llama - Arahan dan ramalan saiz binari GPT-4 Turbo mempunyai sedikit korelasi dengan realiti. Para penyelidik mendapati bahawa LLM Compiler FTD mempunyai ralat yang lebih tinggi sedikit untuk kod yang dioptimumkan daripada untuk kod yang tidak dioptimumkan. Khususnya, LLM Compiler FTD kadangkala mempunyai kecenderungan untuk menilai terlalu tinggi keberkesanan pengoptimuman, menghasilkan ramalan saiz binari yang lebih rendah daripada saiz sebenar. Penyelidikan ablasi. Jadual 4 membentangkan kajian ablasi prestasi model pada set pengesahan kecil tahan 500 isyarat daripada pengedaran yang sama dengan data latihan mereka (tetapi tidak digunakan dalam latihan). Mereka melakukan latihan yang ditala bendera pada setiap peringkat saluran paip latihan yang ditunjukkan dalam Rajah 1 untuk membandingkan prestasi. Seperti yang ditunjukkan, latihan pembongkaran mengakibatkan penurunan prestasi sedikit daripada purata 5.15% kepada 5.12% (peningkatan melebihi -Oz). Mereka juga menunjukkan prestasi penala auto yang digunakan untuk menjana data latihan yang diterangkan dalam Bahagian 2. LLM Compiler FTD mencapai 77% daripada prestasi autotuner.  kaedah. Pasukan penyelidik menilai ketepatan fungsi kod yang dijana LLM apabila membuka kod pemasangan ke dalam LLVM-IR. Mereka menilai LLM Compiler FTD dan membandingkannya dengan Code Llama - Instruct dan GPT-4 Turbo dan mendapati bahawa akhiran pembayang tambahan diperlukan untuk mengekstrak prestasi terbaik daripada model ini. Akhiran menyediakan konteks tambahan tentang tugasan dan format output yang dijangkakan. Untuk menilai prestasi model, mereka pergi balik menurunkan taraf IR pembongkaran yang dijana oleh model kembali kepada pemasangan. Ini membolehkan kami menilai ketepatan pembongkaran dengan membandingkan skor BLEU pemasangan asal dengan keputusan perjalanan pergi dan balik.Pembongkaran sempurna tanpa kerugian daripada pemasangan ke IR akan mempunyai skor BLEU pergi balik 1.0 (padanan tepat). Set data. Mereka menilai menggunakan 2,015 petunjuk ujian yang diekstrak daripada suite penanda aras MiBench, mengambil 2,398 unit terjemahan yang digunakan untuk penilaian penalaan bendera di atas, untuk menjana pembayang nyahpasang. Mereka kemudian menapis petua berdasarkan panjang token maksimum 8k, membenarkan 8k token untuk output model, meninggalkan 2,015. Jadual 11 meringkaskan penanda aras. Hasilnya. Jadual 5 menunjukkan prestasi model pada tugas pembongkaran. LLM Compiler FTD 7B mempunyai kadar kejayaan perjalanan pergi balik yang lebih tinggi sedikit daripada LLM Compiler FTD 13B, tetapi LLM Compiler FTD 13B mempunyai ketepatan pemasangan pergi balik (BLEU pergi balik) dan paling kerap menghasilkan pemasangan yang sempurna ( padanan tepat pergi balik). Kod Llama - Arahan dan GPT-4 Turbo mengalami kesukaran menjana LLVM-IR yang betul secara sintaksis. Rajah 8 menunjukkan taburan markah BLEU pergi dan balik untuk semua model. Penyelidikan ablasi. Jadual 6 membentangkan kajian ablasi prestasi model pada set pengesahan tahan tahan kecil sebanyak 500 isyarat, diambil daripada dataset MiBench yang digunakan sebelum ini. Mereka melakukan latihan pembongkaran pada setiap peringkat saluran paip latihan yang ditunjukkan dalam Rajah 1 untuk membandingkan prestasi. Kadar perjalanan pergi balik adalah tertinggi apabila melalui keseluruhan susunan data latihan dan terus menurun dengan setiap peringkat latihan, walaupun BLEU pergi balik berubah sedikit pada setiap peringkat. kaedah. Pasukan penyelidik menjalankan penyelidikan ablasi pada model LLM Compiler pada dua tugas model asas: ramalan token seterusnya dan simulasi pengkompil. Mereka melakukan penilaian ini pada setiap peringkat saluran paip latihan untuk memahami cara latihan untuk setiap tugas berturut-turut mempengaruhi prestasi. Untuk ramalan token seterusnya, mereka mengira kebingungan pada sampel kecil LLVM-IR dan kod pemasangan pada semua peringkat pengoptimuman. Mereka menilai simulasi pengkompil menggunakan dua metrik: sama ada IR yang dijana atau kod pemasangan disusun, dan sama ada IR atau kod pemasangan yang dijana betul-betul sepadan dengan apa yang dihasilkan oleh pengkompil. Set data. Untuk ramalan token seterusnya, mereka menggunakan set data pengesahan penahanan kecil daripada pengedaran yang sama seperti data latihan kami tetapi tidak digunakan untuk latihan. Mereka menggunakan gabungan tahap pengoptimuman, termasuk kod yang tidak dioptimumkan, kod yang dioptimumkan dengan -Oz dan senarai laluan yang dijana secara rawak. Untuk simulasi pengkompil, mereka dinilai menggunakan 500 petua yang dijana daripada MiBench menggunakan senarai lulus yang dijana secara rawak mengikut cara yang diterangkan dalam Bahagian 2.2. Hasilnya. Jadual 7 menunjukkan prestasi LLM Compiler FTD pada dua tugas latihan model asas (ramalan token seterusnya dan simulasi pengkompil) merentas semua peringkat latihan. Prestasi ramalan token seterusnya meningkat dengan mendadak selepas Code Llama, yang hampir tidak melihat IR dan pemasangan, dan menurun sedikit dengan setiap peringkat penalaan halus berikutnya. Untuk simulasi pengkompil, model asas Code Llama dan model pra-latihan tidak berprestasi baik kerana mereka tidak dilatih dalam tugas ini. Prestasi maksimum dicapai secara langsung selepas latihan simulasi pengkompil, di mana 95.6% IR dan pemasangan yang dijana oleh LLM Compiler FTD 13B menyusun dan 20% sepadan dengan pengkompil dengan tepat. Selepas melakukan penalaan bendera dan penalaan halus pembongkaran, prestasi menurun. Tugas Kejuruteraan PerisianKaedah. Walaupun tujuan LLM Compiler FTD adalah untuk menyediakan model asas untuk pengoptimuman kod, ia dibina di atas model Llama Kod asas yang dilatih untuk tugas kejuruteraan perisian. Untuk menilai cara latihan tambahan LLM Compiler FTD mempengaruhi prestasi penjanaan kod, mereka menggunakan suite penanda aras yang sama seperti Code Llama untuk menilai keupayaan LLM untuk menjana kod Python daripada gesaan bahasa semula jadi, seperti "Tulis fungsi yang mencari rantaian terpanjang dibentuk oleh pasangan set. Mereka menggunakan tanda aras HumanEval dan MBPP, sama seperti Kod Llama. Hasilnya. Jadual 8 menunjukkan prestasi penyahkodan tamak (lulus@1) untuk semua peringkat latihan model dan saiz model bermula daripada model asas Kod Llama.Ia juga menunjukkan skor model pada pass@10 dan pass@100, yang dijana dengan p=0.95 dan suhu=0.6. Setiap fasa latihan berpusatkan pengkompil mengakibatkan kemerosotan sedikit kebolehan pengaturcaraan Python. Pada HumanEval dan MBPP, prestasi pass@1 LLM Compiler menurun sehingga 18% dan 5%, dan LLM Compiler FTD menurun sehingga 29% dan 22% selepas penalaan bendera tambahan dan penalaan halus pembongkaran. Semua model masih mengungguli Llama 2 dalam kedua-dua tugas. Pasukan penyelidik meta telah menunjukkan bahawa LLM Compiler berprestasi baik pada tugas pengoptimuman pengkompil dan memberikan pemahaman yang lebih baik tentang perwakilan pengkompil dan kod pemasangan berbanding dengan beberapa pengehadan sebelumnya, Tetapi masih ada. Had utama ialah panjang jujukan terhad input (tetingkap konteks). LLM Compiler menyokong tetingkap konteks 16k token, tetapi kod program mungkin lebih panjang daripada ini. Contohnya, apabila diformatkan sebagai tip penalaan bendera, 67% unit terjemahan MiBench melebihi tetingkap konteks ini, seperti yang ditunjukkan dalam Jadual 10. Untuk mengurangkan masalah ini, mereka membahagikan unit terjemahan yang lebih besar kepada fungsi yang berasingan, walaupun ini mengehadkan skop pengoptimuman yang boleh dilakukan, dan masih 18% daripada unit terjemahan berpecah terlalu besar untuk model terlalu besar untuk diterima sebagai input. Penyelidik menggunakan tetingkap konteks yang semakin meningkat, tetapi tetingkap konteks terhad kekal sebagai masalah biasa dalam LLM. Keterbatasan kedua, dan masalah biasa kepada semua LLM, ialah ketepatan output model. Pengguna LLM Compiler disyorkan untuk menilai model mereka menggunakan penanda aras penilaian khusus pengkompil. Memandangkan pengkompil tidak bebas pepijat, sebarang pengoptimuman pengkompil yang dicadangkan mesti diuji dengan teliti. Apabila model dinyahkompilasi menjadi kod pemasangan, ketepatannya hendaklah disahkan melalui perjalanan pergi balik, pemeriksaan manual atau ujian unit. Untuk sesetengah aplikasi, penjanaan LLM boleh dihadkan kepada ungkapan biasa, atau digabungkan dengan pengesahan automatik untuk memastikan ketepatan. https://x.com/AIatMeta/status/1806361623831171318.com
kaedah. Pasukan penyelidik menilai ketepatan fungsi kod yang dijana LLM apabila membuka kod pemasangan ke dalam LLVM-IR. Mereka menilai LLM Compiler FTD dan membandingkannya dengan Code Llama - Instruct dan GPT-4 Turbo dan mendapati bahawa akhiran pembayang tambahan diperlukan untuk mengekstrak prestasi terbaik daripada model ini. Akhiran menyediakan konteks tambahan tentang tugasan dan format output yang dijangkakan. Untuk menilai prestasi model, mereka pergi balik menurunkan taraf IR pembongkaran yang dijana oleh model kembali kepada pemasangan. Ini membolehkan kami menilai ketepatan pembongkaran dengan membandingkan skor BLEU pemasangan asal dengan keputusan perjalanan pergi dan balik.Pembongkaran sempurna tanpa kerugian daripada pemasangan ke IR akan mempunyai skor BLEU pergi balik 1.0 (padanan tepat). Set data. Mereka menilai menggunakan 2,015 petunjuk ujian yang diekstrak daripada suite penanda aras MiBench, mengambil 2,398 unit terjemahan yang digunakan untuk penilaian penalaan bendera di atas, untuk menjana pembayang nyahpasang. Mereka kemudian menapis petua berdasarkan panjang token maksimum 8k, membenarkan 8k token untuk output model, meninggalkan 2,015. Jadual 11 meringkaskan penanda aras. Hasilnya. Jadual 5 menunjukkan prestasi model pada tugas pembongkaran. LLM Compiler FTD 7B mempunyai kadar kejayaan perjalanan pergi balik yang lebih tinggi sedikit daripada LLM Compiler FTD 13B, tetapi LLM Compiler FTD 13B mempunyai ketepatan pemasangan pergi balik (BLEU pergi balik) dan paling kerap menghasilkan pemasangan yang sempurna ( padanan tepat pergi balik). Kod Llama - Arahan dan GPT-4 Turbo mengalami kesukaran menjana LLVM-IR yang betul secara sintaksis. Rajah 8 menunjukkan taburan markah BLEU pergi dan balik untuk semua model. Penyelidikan ablasi. Jadual 6 membentangkan kajian ablasi prestasi model pada set pengesahan tahan tahan kecil sebanyak 500 isyarat, diambil daripada dataset MiBench yang digunakan sebelum ini. Mereka melakukan latihan pembongkaran pada setiap peringkat saluran paip latihan yang ditunjukkan dalam Rajah 1 untuk membandingkan prestasi. Kadar perjalanan pergi balik adalah tertinggi apabila melalui keseluruhan susunan data latihan dan terus menurun dengan setiap peringkat latihan, walaupun BLEU pergi balik berubah sedikit pada setiap peringkat. kaedah. Pasukan penyelidik menjalankan penyelidikan ablasi pada model LLM Compiler pada dua tugas model asas: ramalan token seterusnya dan simulasi pengkompil. Mereka melakukan penilaian ini pada setiap peringkat saluran paip latihan untuk memahami cara latihan untuk setiap tugas berturut-turut mempengaruhi prestasi. Untuk ramalan token seterusnya, mereka mengira kebingungan pada sampel kecil LLVM-IR dan kod pemasangan pada semua peringkat pengoptimuman. Mereka menilai simulasi pengkompil menggunakan dua metrik: sama ada IR yang dijana atau kod pemasangan disusun, dan sama ada IR atau kod pemasangan yang dijana betul-betul sepadan dengan apa yang dihasilkan oleh pengkompil. Set data. Untuk ramalan token seterusnya, mereka menggunakan set data pengesahan penahanan kecil daripada pengedaran yang sama seperti data latihan kami tetapi tidak digunakan untuk latihan. Mereka menggunakan gabungan tahap pengoptimuman, termasuk kod yang tidak dioptimumkan, kod yang dioptimumkan dengan -Oz dan senarai laluan yang dijana secara rawak. Untuk simulasi pengkompil, mereka dinilai menggunakan 500 petua yang dijana daripada MiBench menggunakan senarai lulus yang dijana secara rawak mengikut cara yang diterangkan dalam Bahagian 2.2. Hasilnya. Jadual 7 menunjukkan prestasi LLM Compiler FTD pada dua tugas latihan model asas (ramalan token seterusnya dan simulasi pengkompil) merentas semua peringkat latihan. Prestasi ramalan token seterusnya meningkat dengan mendadak selepas Code Llama, yang hampir tidak melihat IR dan pemasangan, dan menurun sedikit dengan setiap peringkat penalaan halus berikutnya. Untuk simulasi pengkompil, model asas Code Llama dan model pra-latihan tidak berprestasi baik kerana mereka tidak dilatih dalam tugas ini. Prestasi maksimum dicapai secara langsung selepas latihan simulasi pengkompil, di mana 95.6% IR dan pemasangan yang dijana oleh LLM Compiler FTD 13B menyusun dan 20% sepadan dengan pengkompil dengan tepat. Selepas melakukan penalaan bendera dan penalaan halus pembongkaran, prestasi menurun. Tugas Kejuruteraan PerisianKaedah. Walaupun tujuan LLM Compiler FTD adalah untuk menyediakan model asas untuk pengoptimuman kod, ia dibina di atas model Llama Kod asas yang dilatih untuk tugas kejuruteraan perisian. Untuk menilai cara latihan tambahan LLM Compiler FTD mempengaruhi prestasi penjanaan kod, mereka menggunakan suite penanda aras yang sama seperti Code Llama untuk menilai keupayaan LLM untuk menjana kod Python daripada gesaan bahasa semula jadi, seperti "Tulis fungsi yang mencari rantaian terpanjang dibentuk oleh pasangan set. Mereka menggunakan tanda aras HumanEval dan MBPP, sama seperti Kod Llama. Hasilnya. Jadual 8 menunjukkan prestasi penyahkodan tamak (lulus@1) untuk semua peringkat latihan model dan saiz model bermula daripada model asas Kod Llama.Ia juga menunjukkan skor model pada pass@10 dan pass@100, yang dijana dengan p=0.95 dan suhu=0.6. Setiap fasa latihan berpusatkan pengkompil mengakibatkan kemerosotan sedikit kebolehan pengaturcaraan Python. Pada HumanEval dan MBPP, prestasi pass@1 LLM Compiler menurun sehingga 18% dan 5%, dan LLM Compiler FTD menurun sehingga 29% dan 22% selepas penalaan bendera tambahan dan penalaan halus pembongkaran. Semua model masih mengungguli Llama 2 dalam kedua-dua tugas. Pasukan penyelidik meta telah menunjukkan bahawa LLM Compiler berprestasi baik pada tugas pengoptimuman pengkompil dan memberikan pemahaman yang lebih baik tentang perwakilan pengkompil dan kod pemasangan berbanding dengan beberapa pengehadan sebelumnya, Tetapi masih ada. Had utama ialah panjang jujukan terhad input (tetingkap konteks). LLM Compiler menyokong tetingkap konteks 16k token, tetapi kod program mungkin lebih panjang daripada ini. Contohnya, apabila diformatkan sebagai tip penalaan bendera, 67% unit terjemahan MiBench melebihi tetingkap konteks ini, seperti yang ditunjukkan dalam Jadual 10. Untuk mengurangkan masalah ini, mereka membahagikan unit terjemahan yang lebih besar kepada fungsi yang berasingan, walaupun ini mengehadkan skop pengoptimuman yang boleh dilakukan, dan masih 18% daripada unit terjemahan berpecah terlalu besar untuk model terlalu besar untuk diterima sebagai input. Penyelidik menggunakan tetingkap konteks yang semakin meningkat, tetapi tetingkap konteks terhad kekal sebagai masalah biasa dalam LLM. Keterbatasan kedua, dan masalah biasa kepada semua LLM, ialah ketepatan output model. Pengguna LLM Compiler disyorkan untuk menilai model mereka menggunakan penanda aras penilaian khusus pengkompil. Memandangkan pengkompil tidak bebas pepijat, sebarang pengoptimuman pengkompil yang dicadangkan mesti diuji dengan teliti. Apabila model dinyahkompilasi menjadi kod pemasangan, ketepatannya hendaklah disahkan melalui perjalanan pergi balik, pemeriksaan manual atau ujian unit. Untuk sesetengah aplikasi, penjanaan LLM boleh dihadkan kepada ungkapan biasa, atau digabungkan dengan pengesahan automatik untuk memastikan ketepatan. https://x.com/AIatMeta/status/1806361623831171318.com
/ penyelidikan/penerbitan/meta -model-penyusun-asas-model-bahasa-besar-pengoptimuman-pengkompil/?utm_source=twitter&utm_medium=organic_social&utm_content=link&utm_campaign=fairAtas ialah kandungan terperinci Pemaju sangat gembira! Keluaran terbaru Meta bagi LLM Compiler mencapai kecekapan penalaan automatik 77%.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!











 Bagaimana untuk menyelesaikan ralat 504 dalam cdn
Bagaimana untuk menyelesaikan ralat 504 dalam cdn
 Apakah perkembangan sekunder biasa dalam PHP?
Apakah perkembangan sekunder biasa dalam PHP?
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran Tomcat
 Apakah pengecam Python?
Apakah pengecam Python?
 Cara menggunakan return dalam bahasa C
Cara menggunakan return dalam bahasa C
 Sebab mengapa pencetak Windows tidak mencetak
Sebab mengapa pencetak Windows tidak mencetak
 Penjelasan terperinci tentang konfigurasi nginx
Penjelasan terperinci tentang konfigurasi nginx
 Pengenalan kepada jenis antara muka cakera keras
Pengenalan kepada jenis antara muka cakera keras








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



