


Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pengarang artikel ini, Dr. Pan Liang, kini merupakan seorang Saintis Penyelidik di Makmal Kepintaran Buatan Shanghai. Sebelum ini, dari 2020 hingga 2023, beliau berkhidmat sebagai Felo Penyelidik di S-Lab of Nanyang Technological University di Singapura, dan penasihatnya ialah Profesor Liu Ziwei. Penyelidikannya memfokuskan pada penglihatan komputer, awan titik 3D dan manusia maya, dan dia telah menerbitkan berbilang kertas dalam persidangan dan jurnal teratas, dengan lebih daripada 2700 petikan Google Scholar. Selain itu, beliau telah berkhidmat sebagai penyemak untuk persidangan dan jurnal teratas dalam bidang penglihatan komputer dan pembelajaran mesin.
Baru-baru ini, S-Lab Pusat Penyelidikan AI Bersama SenseTime-Nanyang Technological University, Makmal Kecerdasan Buatan Shanghai, Universiti Peking dan Universiti Michigan bersama-sama mencadangkan DreamGaussian4D (DG4D), yang menggabungkan pemodelan eksplisit transformasi ruang dengan 3D Splatting statik (Gaussian Splatting). Teknologi GS) membolehkan penjanaan kandungan empat dimensi yang cekap.
Penjanaan kandungan empat dimensi telah mencapai kemajuan yang ketara baru-baru ini, tetapi kaedah sedia ada mempunyai masalah seperti masa pengoptimuman yang lama, keupayaan kawalan gerakan yang lemah dan kualiti perincian yang rendah. DG4D mencadangkan rangka kerja keseluruhan yang mengandungi dua modul utama: 1) Imej kepada GS 4D - kami mula-mula menggunakan DreamGaussianHD untuk menjana GS 3D statik, dan kemudian menjana penjanaan dinamik berdasarkan ubah bentuk Gaussian berdasarkan HexPlane 2) Video kepada penghalusan tekstur video - kami peta tekstur spatial UV yang terhasil diperhalusi dan ketekalan temporalnya dipertingkatkan dengan menggunakan model resapan imej-ke-video yang telah dilatih.
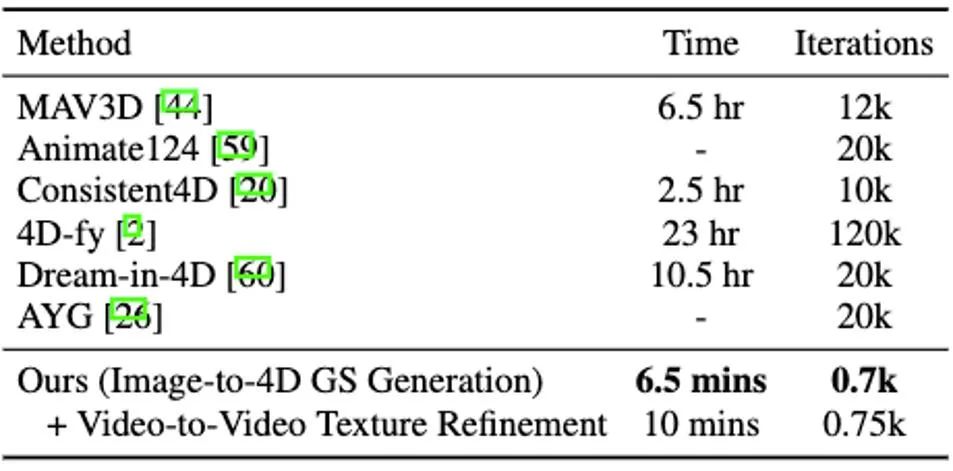
Perlu diambil perhatian bahawa DG4D mengurangkan masa pengoptimuman penjanaan kandungan empat dimensi daripada jam kepada minit (seperti yang ditunjukkan dalam Rajah 1), membenarkan kawalan visual bagi gerakan tiga dimensi yang dijana dan menyokong penjanaan imej yang boleh dipaparkan secara realistik dalam model mesh animasi tiga dimensi.

Nama kertas: DreamGaussian4D: Generatif 4D Gaussian Splatting
Alamat halaman utama: https://jiawei-ren.github.io/projects/dreamgaussian

Rajah 1. DG4D dapat menyedari kandungan empat dimensi dalam empat dan a setengah minit Mengoptimumkan Penumpuan Asas
Isu dan CabaranModel generatif boleh memudahkan pengeluaran dan penghasilan kandungan digital yang pelbagai seperti imej 2D, video dan pemandangan 3D, dan telah mencapai kemajuan yang ketara dalam beberapa tahun kebelakangan ini. Kandungan empat dimensi ialah bentuk kandungan penting untuk banyak tugas hiliran seperti permainan, filem dan televisyen. Kandungan terjana empat dimensi juga harus menyokong pengimportan perisian enjin pemaparan grafik tradisional (seperti Blender atau Enjin Tidak Sebenar) untuk menyambung ke saluran pengeluaran kandungan grafik sedia ada (lihat Rajah 2).
Walaupun terdapat beberapa kajian khusus untuk generasi tiga dimensi (iaitu empat dimensi) dinamik, masih terdapat cabaran dalam penjanaan adegan empat dimensi yang cekap dan berkualiti tinggi. Dalam tahun-tahun kebelakangan ini, semakin banyak kaedah penyelidikan telah digunakan untuk mencapai penjanaan kandungan empat dimensi dengan menggabungkan model penjanaan video dan tiga dimensi untuk mengekang ketekalan penampilan kandungan dan tindakan di bawah sebarang sudut tontonan.

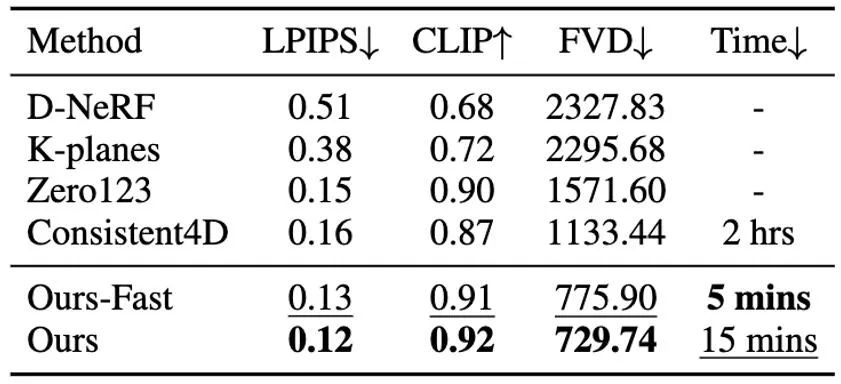
NeRF) berkata. Contohnya, MAV3D [1] mencapai penjanaan kandungan teks kepada empat dimensi dengan memperhalusi model resapan teks kepada video pada HexPlane [2]. Consistent4D [3] memperkenalkan rangka kerja video-ke-4D untuk mengoptimumkan DyNeRF berlatarkan untuk menjana pemandangan 4D daripada video yang ditangkap secara statik. Dengan model resapan berbilang terdahulu, Animate124 [4] dapat menganimasikan satu imej 2D yang belum diproses menjadi video dinamik 3D melalui penerangan gerakan teks. Berdasarkan teknologi SDS [5] hibrid, 4D-fy [6] membolehkan penjanaan kandungan teks kepada empat dimensi yang menarik menggunakan berbilang model resapan terlatih. Walau bagaimanapun, semua kaedah sedia ada [1,3,4,6] yang dinyatakan di atas memerlukan beberapa jam untuk menjana satu NeRF 4D, yang sangat mengehadkan potensi aplikasinya. Tambahan pula, mereka semua menghadapi kesukaran untuk mengawal atau memilih gerakan yang dihasilkan dengan berkesan. Kelemahan di atas terutamanya datang daripada faktor berikut: Pertama, perwakilan empat dimensi tersirat yang mendasari kaedah yang disebutkan di atas tidak cukup cekap, dan terdapat masalah seperti kelajuan pemaparan yang perlahan dan keteraturan gerakan yang lemah, kedua, sifat rawak SDS video; meningkatkan kesukaran penumpuan, dan dalam keputusan akhir Memperkenalkan ketidakstabilan dan pelbagai artifak. Pengenalan kaedah Berbeza daripada kaedah yang mengoptimumkan 4D NeRF secara langsung, DG4D membina perwakilan yang cekap dan berkuasa untuk penjanaan kandungan 4D dengan menggabungkan teknologi percikan Gaussian statik dan pemodelan transformasi spatial yang eksplisit. Tambahan pula, kaedah penjanaan video berpotensi untuk menyediakan prior spatiotemporal berharga yang meningkatkan penjanaan 4D berkualiti tinggi. Secara khusus, kami mencadangkan rangka kerja keseluruhan yang terdiri daripada dua peringkat utama: 1) imej kepada penjanaan 4D GS; 2) pemurnian peta tekstur berasaskan model besar. D1. Penjanaan imej kepada GS 4D
Dalam peringkat ini, kami menggunakan GS 3D dinamik dan statiknya adegan dimensi. Berdasarkan imej 2D yang diberikan, kami menggunakan kaedah DreamGaussianHD yang dipertingkatkan untuk menjana GS 3D statik. Selepas itu, dengan mengoptimumkan medan ubah bentuk bergantung masa pada fungsi GS 3D statik, ubah bentuk Gaussian pada setiap cap waktu dianggarkan, bertujuan untuk menjadikan bentuk dan tekstur setiap bingkai cacat selaras dengan bingkai yang sepadan dalam video pemanduan. Pada akhir peringkat ini, jujukan model mesh tiga dimensi dinamik akan dihasilkan. Berdasarkan model 3D GS statik yang dijana, kami menjana video yang memenuhi jangkaan dengan meramalkan ubah bentuk kernel Gaussian dalam setiap bingkai model Dynamic 4D GS. Dari segi pencirian kesan dinamik, kami memilih HexPlane (ditunjukkan dalam Rajah 5) untuk meramalkan anjakan isirong Gaussian, putaran dan skala pada setiap cap waktu, dengan itu memacu penjanaan model dinamik bagi setiap bingkai. Di samping itu, kami juga melaraskan rangkaian reka bentuk dengan cara yang disasarkan, terutamanya sambungan baki dan reka bentuk permulaan sifar untuk beberapa lapisan rangkaian operasi linear terakhir, supaya medan dinamik boleh dimulakan dengan lancar dan sepenuhnya berdasarkan model 3D GS statik ( kesannya adalah seperti yang ditunjukkan dalam rajah) yang ditunjukkan dalam 6).始 Rajah 6 Kesan permulaan pembentukan dinamik pada generasi akhir medan dinamik Sama seperti DreamGaussian, selepas peringkat pertama penjanaan model dinamik empat dimensi berdasarkan GS 4D, jujukan model mesh empat dimensi boleh diekstrak. Selain itu, kami juga boleh mengoptimumkan lagi tekstur dalam ruang UV model mesh, sama seperti apa yang DreamGaussian lakukan. Tidak seperti DreamGaussian, yang hanya menggunakan model penjanaan imej untuk mengoptimumkan tekstur untuk model jejaring 3D individu, kami perlu mengoptimumkan keseluruhan jujukan jejaring 3D. Selain itu, kami mendapati bahawa jika kami mengikuti pendekatan DreamGaussian, iaitu, melakukan pengoptimuman tekstur bebas untuk setiap jujukan jejaring 3D, tekstur jejaring 3D akan dijana secara tidak konsisten pada cap waktu yang berbeza, dan selalunya akan berkelip, dsb. Artifak kecacatan muncul. Memandangkan perkara ini, kami berbeza daripada DreamGaussian dan mencadangkan kaedah pengoptimuman tekstur video-ke-video dalam ruang UV berdasarkan model penjanaan video yang besar. Khususnya, kami menjana satu siri trajektori kamera secara rawak semasa proses pengoptimuman, dan menghasilkan berbilang video berdasarkan ini, dan melakukan penambahan hingar dan denosing yang sepadan pada video yang diberikan untuk mencapai penjanaan jujukan model mesh. Perbandingan kesan pengoptimuman tekstur untuk menghasilkan model besar berdasarkan gambar dan menghasilkan model besar berdasarkan video ditunjukkan dalam Rajah 8. Berbanding dengan kaedah pengoptimuman keseluruhan NeRF 4D sebelumnya, DG4D dikurangkan dengan ketara Masa yang diperlukan untuk menjana kandungan empat dimensi dikurangkan. Perbandingan masa tertentu boleh dilihat dalam Jadual 1.
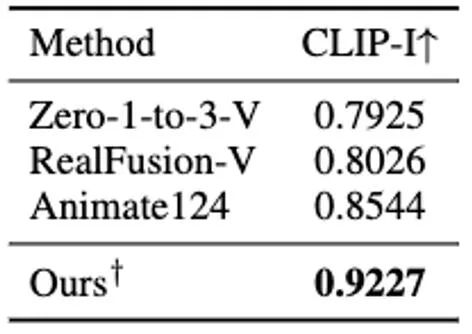
Laporan ketekalan. hasil berangka kaedah berkaitan kandungan empat dimensi berdasarkan penjanaan video Selain itu, kami juga menjana kandungan 3D statik berdasarkan kaedah suapan terus terkini untuk menjana GS 3D daripada satu imej (iaitu, tidak menggunakan kaedah pengoptimuman SDS), dan memulakan penjanaan 4D GS dinamik berdasarkan ini. Penjanaan suapan terus 3D GS boleh menghasilkan kandungan 3D yang lebih berkualiti dan lebih pelbagai lebih pantas daripada kaedah berdasarkan pengoptimuman SDS. Kandungan empat dimensi yang diperoleh berdasarkan ini ditunjukkan dalam Rajah 11.生 Rajah 11 Kandungan dinamik empat dimensi yang dijana berdasarkan kaedah penjanaan 3D GS Kesimpulan
Berdasarkan GS 4D, kami mencadangkan DreamGaussian4D (DG4D), rangka kerja penjanaan imej-ke-4D yang cekap. Berbanding dengan rangka kerja penjanaan kandungan empat dimensi sedia ada, DG4D mengurangkan masa pengoptimuman dari jam ke minit dengan ketara. Selain itu, kami menunjukkan penggunaan video yang dijana untuk penjanaan gerakan terdorong, mencapai penjanaan gerakan 3D yang boleh dikawal secara visual.
Rujukan [1] Penyanyi et al. "Generasi adegan dinamik teks-ke-4D." [ 2] Cao et al. "Hexplane: Perwakilan pantas untuk adegan dinamik." Penjanaan Objek Dinamik 360° daripada Video Monokular." Persidangan Antarabangsa Kedua Belas mengenai Perwakilan Pembelajaran. 2023. [4] Zhao et al. "Animate124: Animating one image to 4d dynamic scene." arXiv.40 pracetak 4d. (2023). [5] Poole et al. , Sherwin, et al. "4d-fy: Penjanaan teks-ke-4d menggunakan pensampelan penyulingan skor hibrid" arXiv arXiv:2311.17984 (2023). Gaussian Splatting untuk Penciptaan Kandungan 3D yang Cekap." Persidangan Antarabangsa Kedua Belas mengenai Perwakilan Pembelajaran. 2023.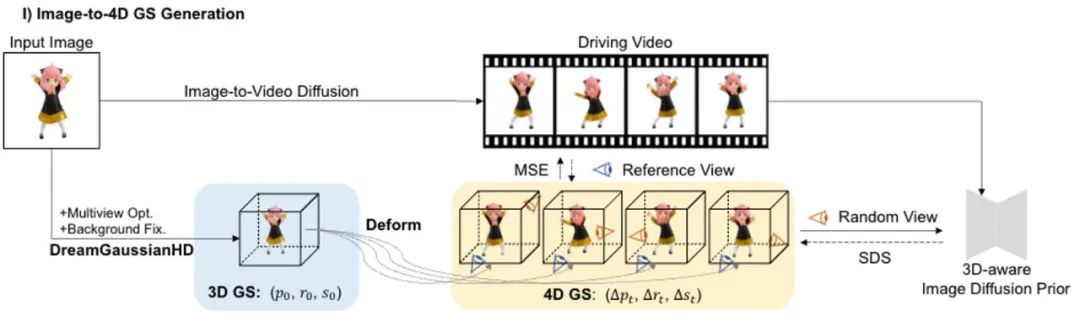

Tekstur video bingkai gambar rajah 7 
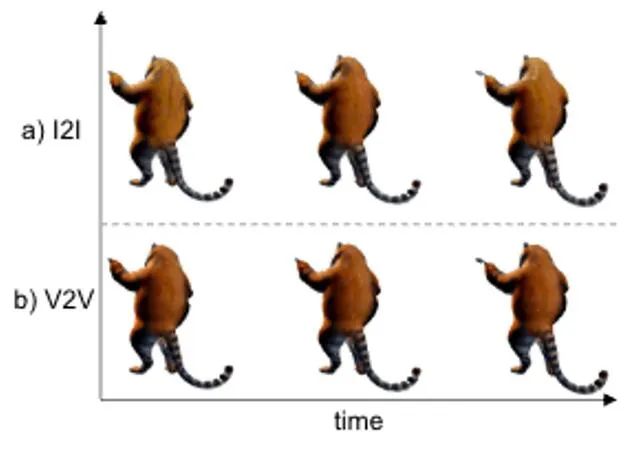
 DG4D dan graf SOTA sumber terbuka sedia ada menjana kesan kaedah kandungan empat dimensi dan kaedah kandungan empat dimensi yang menjana video, iaitu dipaparkan dalam Rajah 9 masing-masing dan Rajah 10.内容 Rajah 9 Rajah 9 Rajah 4 -perbandingan kesan kandungan dimensi Rajah 10 Video Sheng perbandingan kesan kandungan empat dimensi Rajah
DG4D dan graf SOTA sumber terbuka sedia ada menjana kesan kaedah kandungan empat dimensi dan kaedah kandungan empat dimensi yang menjana video, iaitu dipaparkan dalam Rajah 9 masing-masing dan Rajah 10.内容 Rajah 9 Rajah 9 Rajah 4 -perbandingan kesan kandungan dimensi Rajah 10 Video Sheng perbandingan kesan kandungan empat dimensi Rajah 

Atas ialah kandungan terperinci Hasilkan kandungan empat dimensi dalam beberapa minit dan kawal kesan gerakan: Universiti Peking dan Michigan mencadangkan DG4D. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



