
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Dalam beberapa tahun kebelakangan ini, penerapan model bahasa besar multimodal (MLLM) dalam pelbagai bidang telah mencapai kejayaan yang ketara. Walau bagaimanapun, sebagai model asas untuk banyak tugas hiliran, MLLM semasa terdiri daripada rangkaian Transformer yang terkenal, yang mempunyai kerumitan pengiraan kuadratik yang kurang cekap. Untuk meningkatkan kecekapan model asas sedemikian, sebilangan besar eksperimen menunjukkan bahawa: (1) Cobra mempunyai prestasi yang sangat kompetitif dengan kaedah terkini yang terkini dengan kecekapan pengiraan yang tinggi (cth., LLaVA-Phi, TinyLLaVA dan MobileVLM v2), dan disebabkan pemodelan jujukan linear Cobra, yang lebih pantas. (2) Menariknya, keputusan penanda aras ramalan mencabar set tertutup menunjukkan bahawa Cobra berprestasi baik dalam mengatasi ilusi visual dan pertimbangan hubungan spatial. (3) Perlu diingat bahawa Cobra mencapai prestasi yang setanding dengan LLaVA walaupun bilangan parameter hanya kira-kira 43% daripada LLaVA. Model bahasa besar (LLM) terhad kepada berinteraksi hanya melalui bahasa, mengehadkan kebolehsuaian mereka untuk mengendalikan tugas yang lebih pelbagai. Pemahaman pelbagai mod adalah penting untuk meningkatkan keupayaan model untuk menangani cabaran dunia sebenar dengan berkesan. Oleh itu, penyelidik sedang giat berusaha untuk memanjangkan model bahasa yang besar untuk menggabungkan keupayaan pemprosesan maklumat multimodal. Model Bahasa Visual (VLM) seperti GPT-4, Penyesuai LLaMA dan LLaVA telah dibangunkan untuk meningkatkan keupayaan pemahaman visual LLM. Walau bagaimanapun, penyelidikan terdahulu terutamanya cuba mendapatkan VLM yang cekap dengan cara yang sama, iaitu, mengurangkan parameter model bahasa asas atau bilangan token visual sambil mengekalkan struktur Transformer berasaskan perhatian tidak berubah. Makalah ini mencadangkan perspektif yang berbeza: secara langsung menggunakan model ruang keadaan (SSM) sebagai rangkaian tulang belakang, MLLM dengan kerumitan pengiraan linear diperolehi. Selain itu, kertas kerja ini meneroka dan mengkaji pelbagai skim gabungan modal untuk mencipta Mamba berbilang modal yang berkesan. Secara khusus, kertas kerja ini mengguna pakai model bahasa Mamba sebagai model asas VLM, yang telah menunjukkan prestasi yang boleh bersaing dengan model bahasa Transformer, tetapi dengan kecekapan inferens yang lebih tinggi. Ujian menunjukkan bahawa prestasi inferens Cobra adalah 3x hingga 4x lebih pantas daripada MobileVLM v2 3B dan TinyLLaVA 3B dengan magnitud parameter yang sama. Walaupun jika dibandingkan dengan model LLaVA v1.5 (parameter 7B), yang mempunyai bilangan parameter yang jauh lebih tinggi, Cobra masih mencapai prestasi padanan pada beberapa penanda aras dengan kira-kira 43% bilangan parameter. 
Mengtinjau model bahasa berskala besar berskala besar berbilang modal yang mempamerkan rangkaian komplek Transional (MLLMs) yang kompleks. Untuk menangani ketidakcekapan ini, kertas kerja ini memperkenalkan Cobra, MLLM novel dengan kerumitan pengiraan linear.
Selami pelbagai skema gabungan modal untuk mengoptimumkan penyepaduan maklumat visual dan linguistik dalam model bahasa Mamba. Melalui eksperimen, kertas kerja ini meneroka keberkesanan strategi gabungan yang berbeza dan menentukan kaedah yang menghasilkan perwakilan multimodal yang paling berkesan.
Eksperimen meluas telah dijalankan untuk menilai prestasi Cobra dengan kajian selari yang bertujuan untuk meningkatkan kecekapan pengiraan asas MLLM. Terutama, Cobra mencapai prestasi yang setanding dengan LLaVA walaupun dengan parameter yang lebih sedikit, menyerlahkan kecekapannya.
- Pautan asal: https://arxiv.org/pdf/2403.14520v2.pdf
- Pautan projek: https://sites.google.com/view/cobravlm/
- tajuk:CobraPaper Memperluaskan Mamba kepada Model Bahasa Besar Berbilang Modal untuk Inferens Cekap untuk menyambung dua model Struktur VLM terdiri daripada projektor stateful dan tulang belakang bahasa LLM. Bahagian tulang belakang LLM menggunakan model bahasa Mamba pra-latihan parameter 2.8B, yang telah dilatih pada set data SlimPajama dengan token 600B dan diperhalusi dengan arahan data perbualan.网络 Gambarajah struktur rangkaian Cobra
Berbeza daripada LLAVA, dsb., COBRA menggunakan perwakilan visual gabungan Dinov2 dan SIGLIP Dengan mencantumkan output kedua-dua pengekod visual bersama-sama Memasukkan ke dalam projektor, model boleh menangkap dengan lebih baik ciri semantik peringkat tinggi yang dibawa oleh SigLIP dan ciri imej berbutir halus peringkat rendah yang diekstrak oleh DINOv2. Skim latihan
Penyelidikan terkini menunjukkan bahawa untuk paradigma latihan sedia ada berdasarkan LLaVA (iaitu, hanya melatih peringkat pra-penjajaran lapisan unjuran dan tahap penalaan halus bagi LLM. setiap satu), peringkat prapenjajaran mungkin tidak diperlukan dan model yang diperhalusi mungkin masih kurang dipasang. Oleh itu, Cobra meninggalkan peringkat prapenjajaran dan terus memperhalusi keseluruhan tulang belakang dan projektor bahasa LLM. Proses penalaan halus ini dilakukan untuk dua zaman dengan pensampelan rawak pada set data gabungan yang terdiri daripada: 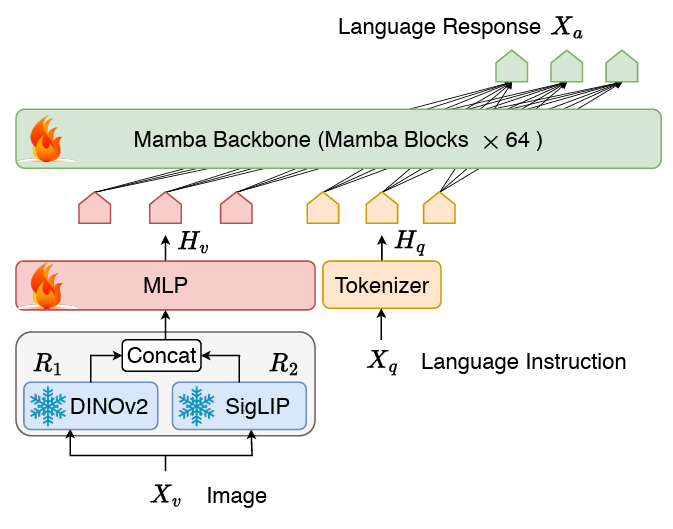
Dataset hibrid yang digunakan dalam LLaVA v1.5, yang mengandungi sejumlah 655K perbualan berbilang pusingan visual, termasuk Akademik Sampel VQA, serta data penalaan arahan visual dalam LLaVA-Instruct dan data penalaan arahan teks biasa dalam ShareGPT. LVIS-Instruct-4V, yang mengandungi 220K imej dengan penjajaran visual dan arahan peka konteks yang dijana oleh GPT-4V. LRV-Instruct, set data yang mengandungi 400K arahan visual yang meliputi 16 tugas bahasa visual, bertujuan untuk mengurangkan fenomena halusinasi. Seluruh set data mengandungi kira-kira 1.2 juta imej dan berbilang pusingan data perbualan yang sepadan, serta data perbualan teks biasa. Eksperimen
Dalam bahagian eksperimen, makalah ini membandingkan model COBRA yang dicadangkan dan model SOTA VLM sumber terbuka pada penanda aras asas, dan membandingkannya dengan sama Magnitud adalah berdasarkan kelajuan menjawab model VLM berdasarkan seni bina Transformer. Pada masa yang sama, kelajuan penjanaan dan perbandingan prestasi graf pada masa yang sama, COBRA juga merupakan empat tugas VQA terbuka VQA-V2, GQA, Vizwiz, TextVQA dan VSR, POPE dua Untuk tugas ramalan set tertutup , markah dibandingkan pada sejumlah 6 penanda aras. Perbandingan peta pada Penanda Aras dan model sumber terbuka lain
Ujian kualitatif Di samping itu, Cobra juga memberikan dua contoh VQA untuk objek secara kualitatif i. Keunggulan dalam keupayaan untuk mengenali hubungan ruang dan mengurangkan ilusi model.和 Rajah COBRA dan model garis dasar lain dalam pertimbangan hubungan ruang objek 和 Rajah Cobra dan model garis dasar lain dalam contoh ilusi visual Dalam contoh, Llava V1.5 dan Mobilevlm diberi jawapan ralat, manakala COBRA melakukan Penerangan yang tepat telah diberikan, terutamanya dalam contoh kedua, Cobra mengenal pasti dengan tepat bahawa gambar itu datang dari persekitaran simulasi robot.
Artikel ini menjalankan penyelidikan ablasi mengenai penyelesaian yang diterima pakai oleh Cobra daripada dua dimensi prestasi dan kelajuan penjanaan. Pelan eksperimen menjalankan eksperimen ablasi masing-masing pada projektor, pengekod visual, dan tulang belakang bahasa LLM. Perbandingan prestasi prestasi eksperimen ablasi gambar rajah menunjukkan bahawa eksperimen ablasi bahagian projek projektor menunjukkan bahawa kesan projektor MLP yang diguna pakai dalam artikel ini adalah lebih baik secara signifikan daripada khusus untuk mengurangkan bilangan Token visual kepada LDP. modul meningkatkan kelajuan pengkomputeran Pada masa yang sama, kerana kelajuan pemprosesan jujukan dan kerumitan pengkomputeran Cobra adalah lebih baik daripada Transformer, modul LDP tidak mempunyai kelebihan yang jelas dalam kelajuan penjanaan. Oleh itu, model kelas Mamba digunakan untuk mengurangkan bilangan token visual dengan mengorbankan ketepatan Pensampel mungkin tidak diperlukan.和 Rajah COBRA dan model lain dalam julat perbandingan kelajuan penjanaan
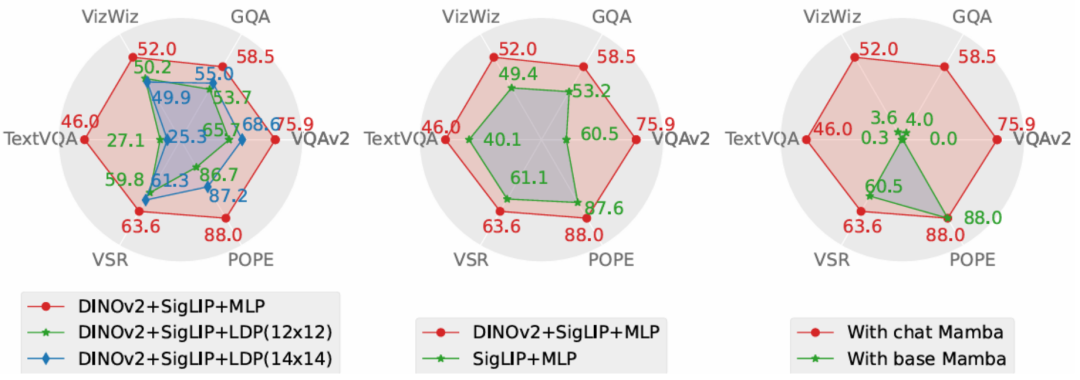
Keputusan ablasi bahagian pengekod visual menunjukkan gabungan ciri Dinov2 secara berkesan meningkatkan prestasi COBRA. Dalam eksperimen tulang belakang bahasa, model bahasa Mamba tanpa penalaan halus arahan sama sekali tidak dapat memberikan jawapan yang munasabah dalam ujian soalan dan jawapan terbuka, manakala model bahasa Mamba yang ditala halus boleh mencapai prestasi yang besar dalam pelbagai tugas. KesimpulanKertas ini mencadangkan Cobra, yang menyelesaikan kesesakan kecekapan model bahasa berskala besar berbilang mod sedia ada yang bergantung pada rangkaian Transformer dengan kompleksiti pengiraan kuadratik. Kertas kerja ini meneroka gabungan model bahasa dengan kerumitan pengiraan linear dan input multimodal. Dari segi penggabungan maklumat visual dan bahasa, kertas kerja ini berjaya mengoptimumkan integrasi maklumat dalaman model bahasa Mamba dan mencapai perwakilan pelbagai mod yang lebih berkesan melalui penyelidikan mendalam mengenai skema gabungan modal yang berbeza. Eksperimen menunjukkan bahawa Cobra bukan sahaja meningkatkan kecekapan pengiraan dengan ketara, tetapi juga setanding dalam prestasi kepada model lanjutan seperti LLaVA, terutamanya dalam mengatasi ilusi visual dan pertimbangan hubungan ruang. Malah ia mengurangkan bilangan parameter dengan ketara. Ini membuka kemungkinan baharu untuk penggunaan model AI berprestasi tinggi pada masa hadapan dalam persekitaran yang memerlukan pemprosesan maklumat visual frekuensi tinggi, seperti kawalan maklum balas robot berasaskan penglihatan. 
Atas ialah kandungan terperinci MLLM berasaskan Mamba yang pertama ada di sini! Berat model, kod latihan, dsb. semuanya telah menjadi sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



